3 День 2. Работа с реальными данными в R
3.1 Препроцессинг данных в R
Вчера мы узнали про основы языка R, про то, как работать с векторами, списками, матрицами и, наконец, датафреймами. Мы закончили день на загрузке данных, с чего мы и начнем сегодня:
got <- read.csv("data/character-deaths.csv", stringsAsFactors = FALSE)После загрузки данных стоит немного “осмотреть” получившийся датафрейм got.
3.1.1 Исследование данных
Ок, давайте немного поизучаем датасет. Обычно мы привыкли глазами пробегать по данным, листая строки и столбцы - и это вполне правильно и логично, от этого не нужно отучаться. Но мы можем дополнить наш базовый зрительнопоисковой инструментарий несколькими полезными командами.
Во-первых, вспомним другую полезную функцию str():
str(got)## 'data.frame': 917 obs. of 13 variables:
## $ Name : chr "Addam Marbrand" "Aegon Frey (Jinglebell)" "Aegon Targaryen" "Adrack Humble" ...
## $ Allegiances : chr "Lannister" "None" "House Targaryen" "House Greyjoy" ...
## $ Death.Year : int NA 299 NA 300 NA NA 300 300 NA NA ...
## $ Book.of.Death : int NA 3 NA 5 NA NA 4 5 NA NA ...
## $ Death.Chapter : int NA 51 NA 20 NA NA 35 NA NA NA ...
## $ Book.Intro.Chapter: int 56 49 5 20 NA NA 21 59 11 0 ...
## $ Gender : int 1 1 1 1 1 1 1 0 1 1 ...
## $ Nobility : int 1 1 1 1 1 1 1 1 1 0 ...
## $ GoT : int 1 0 0 0 0 0 1 1 0 0 ...
## $ CoK : int 1 0 0 0 0 1 0 1 1 0 ...
## $ SoS : int 1 1 0 0 1 1 1 1 0 1 ...
## $ FfC : int 1 0 0 0 0 0 1 0 1 0 ...
## $ DwD : int 0 0 1 1 0 0 0 1 0 0 ...Давайте разберемся с переменными в датафрейме:
Колонка Name - здесь все понятно. Важно, что эти имена записаны абсолютно по-разному: где-то с фамилией, где-то без, где-то в скобочках есть пояснения. Колонка Allegiances - к какому дому принадлежит персонаж. С этим сложно, иногда они меняют дома, здесь путаются сами семьи и персонажи, лояльные им. Особой разницы между Stark и House Stark нет. Следующие колонки - Death Year, Book.of.Death, Death.Chapter, Book.Intro.Chapter - означают номер главы, в которой персонаж впервые появляется, а так же номер книги, глава и год (от завоевания Вестероса Эйгоном Таргариеном), в которой персонаж умирает. Gender - 1 для мужчин, 0 для женщин. Nobility - дворянское происхождение персонажа. Последние 5 столбцов содержат информацию, появлялся ли персонаж в книге (всего книг пока что 5).
Другая полезная функция для больших таблиц - функция head(): она выведет первые несколько (по дефолту 6) строчек датафрейма.
head(got)## Name Allegiances Death.Year Book.of.Death
## 1 Addam Marbrand Lannister NA NA
## 2 Aegon Frey (Jinglebell) None 299 3
## 3 Aegon Targaryen House Targaryen NA NA
## 4 Adrack Humble House Greyjoy 300 5
## 5 Aemon Costayne Lannister NA NA
## 6 Aemon Estermont Baratheon NA NA
## Death.Chapter Book.Intro.Chapter Gender Nobility GoT CoK SoS FfC DwD
## 1 NA 56 1 1 1 1 1 1 0
## 2 51 49 1 1 0 0 1 0 0
## 3 NA 5 1 1 0 0 0 0 1
## 4 20 20 1 1 0 0 0 0 1
## 5 NA NA 1 1 0 0 1 0 0
## 6 NA NA 1 1 0 1 1 0 0Есть еще функция tail(). Догадайтесь сами, что она делает.
Для некоторых переменных полезно посмотреть таблицы частотности с помощью функции table():
table(got$Allegiances)##
## Arryn Baratheon Greyjoy House Arryn
## 23 56 51 7
## House Baratheon House Greyjoy House Lannister House Martell
## 8 24 21 12
## House Stark House Targaryen House Tully House Tyrell
## 35 19 8 11
## Lannister Martell Night's Watch None
## 81 25 116 253
## Stark Targaryen Tully Tyrell
## 73 17 22 15
## Wildling
## 40Уау! Очень просто и удобно, не так ли? Функция table() может принимать сразу несколько столбцов. Это удобно для получения таблиц сопряженности:
table(got$Allegiances, got$Gender)##
## 0 1
## Arryn 3 20
## Baratheon 6 50
## Greyjoy 4 47
## House Arryn 3 4
## House Baratheon 0 8
## House Greyjoy 1 23
## House Lannister 2 19
## House Martell 7 5
## House Stark 6 29
## House Targaryen 5 14
## House Tully 0 8
## House Tyrell 4 7
## Lannister 12 69
## Martell 7 18
## Night's Watch 0 116
## None 51 202
## Stark 21 52
## Targaryen 1 16
## Tully 2 20
## Tyrell 6 9
## Wildling 16 243.1.2 Subsetting
Как мы обсуждали на прошлом занятии, мы можем сабсеттить (т.е. выделять часть датафрейма) датафрейм, обращаясь к нему и как к матрице: датафрейм[вектор_с_номерами_строк, вектор_с_номерами_колонок]
got[100:115, 1:2]## Name Allegiances
## 100 Blue Bard House Tyrell
## 101 Bonifer Hasty Lannister
## 102 Borcas Night's Watch
## 103 Boremund Harlaw Greyjoy
## 104 Boros Blount Baratheon
## 105 Borroq Wildling
## 106 Bowen Marsh Night's Watch
## 107 Bran Stark House Stark
## 108 Brandon Norrey Stark
## 109 Brenett None
## 110 Brienne of Tarth Stark
## 111 Bronn Lannister
## 112 Brown Bernarr Night's Watch
## 113 Brusco None
## 114 Bryan Fossoway Baratheon
## 115 Bryce Caron Baratheonи используя имена колонок:
got[508:515, "Name"]## [1] "Mance Rayder" "Mandon Moore" "Maric Seaworth" "Marei"
## [5] "Margaery Tyrell" "Marillion" "Maris" "Marissa Frey"и даже используя вектора названий колонок!
got[508:515, c("Name", "Allegiances", "Gender")]## Name Allegiances Gender
## 508 Mance Rayder Wildling 1
## 509 Mandon Moore Baratheon 1
## 510 Maric Seaworth House Baratheon 1
## 511 Marei None 0
## 512 Margaery Tyrell House Tyrell 0
## 513 Marillion Arryn 1
## 514 Maris Wildling 0
## 515 Marissa Frey None 0Мы можем вытаскивать отдельные колонки как векторы:
houses <- got$Allegiances
unique(houses) #посмотреть все уникальные значения - почти как с помощью table()## [1] "Lannister" "None" "House Targaryen"
## [4] "House Greyjoy" "Baratheon" "Night's Watch"
## [7] "Arryn" "House Stark" "House Tyrell"
## [10] "Tyrell" "Stark" "Greyjoy"
## [13] "House Lannister" "Martell" "House Martell"
## [16] "Wildling" "Targaryen" "House Arryn"
## [19] "House Tully" "Tully" "House Baratheon"Итак, давайте решим нашу первую задачу - вытащим в отдельный датасет всех представителей Ночного Дозора. Для этого нам нужно создать вектор логических значений - результат сравнений колонки Allegiances со значением "Night's Watch" и использовать его как вектор индексов для датафрейма.
vectornight <- got$Allegiances == "Night's Watch"
head(vectornight)## [1] FALSE FALSE FALSE FALSE FALSE FALSEТеперь этот вектор с TRUE и FALSE нам надо использовать для индексирования строк. Но что со столбцами? Если мы хотем сохранить все столбцы, то после запятой внутри квадратных скобок нам не нужно ничего указывать:
nightswatch <- got[vectornight, ]
head(nightswatch)## Name Allegiances Death.Year
## 7 Aemon Targaryen (son of Maekar I) Night's Watch 300
## 10 Aethan Night's Watch NA
## 13 Alan of Rosby Night's Watch 300
## 16 Albett Night's Watch NA
## 24 Alliser Thorne Night's Watch NA
## 49 Arron Night's Watch NA
## Book.of.Death Death.Chapter Book.Intro.Chapter Gender Nobility GoT CoK
## 7 4 35 21 1 1 1 0
## 10 NA NA 0 1 0 0 0
## 13 5 4 18 1 1 0 1
## 16 NA NA 26 1 0 1 0
## 24 NA NA 19 1 0 1 1
## 49 NA NA 75 1 0 0 0
## SoS FfC DwD
## 7 1 1 0
## 10 1 0 0
## 13 1 0 1
## 16 0 0 0
## 24 1 0 1
## 49 1 0 1Вуаля! Все это можно сделать проще и в одну строку:
nightswatch <- got[got$Allegiances == "Night's Watch", ]И не забывайте про запятую!
Теперь попробуем вытащить одновременно всех Одичалых (Wildling) и всех представителей Ночного Дозора. Это можно сделать, используя оператор | (ИЛИ) при выборе колонок:
nightwatch_wildling <-
got[got$Allegiances == "Night's Watch" | got$Allegiances == "Wildling", ]
head(nightwatch_wildling)## Name Allegiances Death.Year
## 7 Aemon Targaryen (son of Maekar I) Night's Watch 300
## 10 Aethan Night's Watch NA
## 13 Alan of Rosby Night's Watch 300
## 16 Albett Night's Watch NA
## 24 Alliser Thorne Night's Watch NA
## 49 Arron Night's Watch NA
## Book.of.Death Death.Chapter Book.Intro.Chapter Gender Nobility GoT CoK
## 7 4 35 21 1 1 1 0
## 10 NA NA 0 1 0 0 0
## 13 5 4 18 1 1 0 1
## 16 NA NA 26 1 0 1 0
## 24 NA NA 19 1 0 1 1
## 49 NA NA 75 1 0 0 0
## SoS FfC DwD
## 7 1 1 0
## 10 1 0 0
## 13 1 0 1
## 16 0 0 0
## 24 1 0 1
## 49 1 0 1Кажется очевидным следующий вариант:
got[got$Allegiances == c("Night's Watch", "Wildling"),]. Однако это выдаст не совсем то, что нужно, хотя результат может показаться верным на первый взгляд. Попробуйте самостоятельно ответить на вопрос, что происходит в данном случае и чем результат отличается от предполагаемого. Подсказка: вспомните правило recycling.
Для таких случаев есть удобный оператор %in%, который позволяет сравнить каждое значение вектора с целым набором значений. Если значение вектора хотя бы один раз встречается в векторе справа от %in%, то результат - TRUE:
1:6 %in% c(1, 4, 5)## [1] TRUE FALSE FALSE TRUE TRUE FALSEnightwatch_wildling <- got[got$Allegiances %in% c("Night's Watch", "Wildling"), ]
head(nightwatch_wildling)## Name Allegiances Death.Year
## 7 Aemon Targaryen (son of Maekar I) Night's Watch 300
## 10 Aethan Night's Watch NA
## 13 Alan of Rosby Night's Watch 300
## 16 Albett Night's Watch NA
## 24 Alliser Thorne Night's Watch NA
## 49 Arron Night's Watch NA
## Book.of.Death Death.Chapter Book.Intro.Chapter Gender Nobility GoT CoK
## 7 4 35 21 1 1 1 0
## 10 NA NA 0 1 0 0 0
## 13 5 4 18 1 1 0 1
## 16 NA NA 26 1 0 1 0
## 24 NA NA 19 1 0 1 1
## 49 NA NA 75 1 0 0 0
## SoS FfC DwD
## 7 1 1 0
## 10 1 0 0
## 13 1 0 1
## 16 0 0 0
## 24 1 0 1
## 49 1 0 13.1.3 Создание новых колонок
Давайте создадим новую колонку, которая будет означать, жив ли еще персонаж (по книгам). Заметьте, что в этом датасете, хоть он и посвящен смертям персонажей, нет нужной колонки. Мы можем попытаться “вытащить” эту информацию. В колонках Death.Year, Death.Chapter и Book.of.Death стоит NA у многих персонажей. Например, у "Arya Stark", которая и по книгам, и по сериалу живее всех живых и мертвых:
got[got$Name == "Arya Stark", ]## Name Allegiances Death.Year Book.of.Death Death.Chapter
## 56 Arya Stark Stark NA NA NA
## Book.Intro.Chapter Gender Nobility GoT CoK SoS FfC DwD
## 56 2 0 1 1 1 1 1 1Следовательно, если в Book.of.Death стоит NA, мы можем предположить, что Джордж Мартин еще не занес своей карающей руки над этим героем.
Мы можем создать новую колонку Is.Alive:
got$Is.Alive <- is.na(got$Book.of.Death)Готово! Как легко, просто и элегантно, не так ли? Но в жизни часто бывает все сложнее, поэтому давайте научимся еще некоторым важным инструментам.
3.2 Циклы, условия, создание функций
3.2.1 If, else, else if
Как и во всех “нормальных” языках программирования, в R есть if-else statements.
Например:
na_slovah <- "Лев Толстой"
if (na_slovah == "Лев Толстой"){
na_dele = "Парень простой"
} else {na_dele = na_slovah}
na_dele## [1] "Парень простой"В круглых скобках после if - условие. Если оно TRUE, то выполняется то, что внутри последующих фигурных. Если не выполняется, то выполняется то, что в фигурных скобках после else (если else вообще присутствует).
Можно использовать несколько условий:
na_slovah <- "Алексей Толстой"
if (na_slovah == "Лев Толстой"){
na_dele = "Парень простой"
} else if (na_slovah == "Алексей Толстой") {
na_dele = "Лев Толстой"
} else {na_dele = na_slovah}
na_dele## [1] "Лев Толстой"Тем не менее, с if, else, else if есть одна серьезная проблема - на входе нельзя дать вектор, можно только единственное значение. Какая боль! Для решения этой проблемы можно воспользоваться функцией ifelse() или циклами.
3.2.2 Функция ifelse()
Функция ifelse() принимает три аргумента - 1) условие (т.е., по сути, логический вектор, состоящий из TRUE и FALSE), 2) что выдавать в случае TRUE, 3) что выдавать в случае FALSE. Вот это как раз мы можем применить уже к нашим данным.
Давайте сначала сотрем созданную колонку Is.Alive. Для этого присвоим ей значение NULL:
got$Is.Alive <- NULLЗатем создадим ее заново, но уже как текстовую с помощью ifelse():
got$Is.Alive <- ifelse(is.na(got$Book.of.Death), "Alive", "Dead")К сожалению, аналога
else ifв этой функции нет. Но если у вас больше, чем два варианта, то никто не мешает использоватьifelse()внутриifelse()
3.2.3 For loops
Во многих других языках программирования циклы (типа for и while) - это основа основ. Но не в R. В R они, конечно, есть, но использовать их не рекомендуется. Векторизированные операции в R экономнее - как в плане более короткого и читаемого кода, так и в плане скорости.
Векторизованные функции часто написаны на более низкоуровневом языке (например, С), которые быстрее R.
Поэтому дважды подумайте, прежде чем делать то, что я сейчас покажу! Почти всегда в R можно обойтись без циклов.
got$Is.Alive <- NULL
got$Is.Alive <- character(nrow(got)) #сделаем вектор, заполненный пустыми строками
for (i in 1:nrow(got)) {
if (is.na(got$Book.of.Death[i])) {
got$Is.Alive[i] <- "Alive"
} else {
got$Is.Alive[i] <- "Dead"
}
}Ужас какой! Да еще и легко ошибиться. К тому, чтобы НЕ использовать циклы обычно получается приучиться не сразу у тех, кто пришел из других языков программирования. Часто кажется, что именно в данном случае без циклов не обойтись, но в подавляющем числе случаев это не так. Дело в том, что обычно мы работаем в R с датафреймами, которые представляют собой множество относительно независимых наблюдений. Если мы хотим провести какие-нибудь операции с этими наблюдениями, то они обычно могут быть выполнены параллельно. Скажем, вы хотите для каждого испытуемого пересчитать его массу из фунтов в килограммы. Этот пересчет осуществляется по одинаковой формуле для каждого испытуемого. Эта формула не изменится из-за того, что какой-то испытуемый слишком большой или слишком маленький - для следующего испытуемого формула будет прежняя. Если Вы встречаете подобную задачу (где функцию можно применить независимо для всех значений), то без цикла for вполне можно обойтись.
После этих объяснений кому-то может показаться странным, что я вообще упоминаю про эти циклы. Но для кого-то циклы
forнастолько привычны, что их полное отсутствие в курсе может показаться еще более странным. Поэтому лучше от меня, чем на улице.
Бывают случаи, в которых расчет значения в строчке все-таки зависит от предыдущих, но и тогда можно обойтись без циклов! Например, для подсчета кумулятивной суммы можно использовать функцию cumsum():
cumsum(1:10)## [1] 1 3 6 10 15 21 28 36 45 55Существуют и исключения - некоторые функции не векторизованы. Но и тогда можно обойтись без for. В R есть “скрытые” циклы - семейство функций apply(). Но сначала нам нужно научиться создавать собственные функции.
Вообще, если писать циклы
forкорректно, то они не такие уж и медленные. Главное — заранее создавать переменную нужного размера и не изменять размер объекта при каждой итерации цикла. Это основная причина “тормознутости” циклов в R. Тем не менее, циклов следует избегать по той причине, что они со скрипом вписываются в логику функционального программирования в R, поэтому решения без цикловforобычно оказываются проще и элегантнее.
3.2.4 Создание функций
Поздравляю, сейчас мы выйдем на качественно новый уровень владения R. Вместо того, чтобы пользоваться теми функциями, которые уже написали за нас, мы можем сами создавать свои функции! В этом нет ничего сложного. Функция - это такой же объект в R, как и остальные. Давайте разберем на примере создания функции sumofsquares(), которая будет считать сумму квадратичных отклонений от среднего: \(Sum of squares = \sum_{i=1}^{n}(x_i - \bar{x})^2\)
Эта формула будет нам часто встречаться, когда мы перейдем к статистике!
sumofsquares <- function(x) {
centralized_x <- x - mean(x)
squares <- centralized_x ^ 2
sum_of_squares <- sum(squares)
return(sum_of_squares)
}
sumofsquares(1:10)## [1] 82.5Синтаксис создания функции внешне похож на создание циклов. Мы пишем ключевое слово function, в круглых скобках обозначаем переменные, с которыми собираемся что-то делать. Внутри фигурных скобок пишем выражения, которые будут выполняться при запуске функции. У функции есть свое собственное окружение — место, где хранятся переменные. Вот именно те объекты, которые мы передаем в скобочках, и будут в окружении, так же как и “обычные” переменные для нас в глобальном окружении. Это означает, что функция будет искать переменные в первую очередь среди объектов, которые переданы в круглых скобочках. С ними функция и будет работать. На выходе функция выдаст то, что будет закинуто в return(). Однако функция return() часто опускается: если ее нет, то функция будет выводить результат последнего выражения.6 Таким образом, нашу функцию можно написать короче:
sumofsquares <- function(x) {
centralized_x <- x - mean(x)
squares <- centralized_x ^ 2
sum(squares)
}
sumofsquares(1:10)## [1] 82.5Можно еще сократить функцию:
sumofsquares <- function(x) {
sum((x - mean(x)) ^ 2)
}
sumofsquares(1:10)## [1] 82.5На самом деле, если функция занимает всего одну строчку, то фигурные скобки и не нужны.
sumofsquares <- function(x) sum((x - mean(x)) ^ 2)
sumofsquares(1:10)## [1] 82.5Вообще, фигурные скобки используются для того, чтобы выполнить серию выражений, но вернуть только результат выполнения последнего выражения. Это можно использовать, чтобы не создавать лишних временных переменных в глобальном окружении.
Когда стоит создавать функции? Существует “правило трех” - если у вас есть три куска очень похожего кода, то самое время превратить код в функцию. Это очень условное правило, но, действительно, стоит избегать копипастинга в коде. В этом случае очень легко ошибиться, код становится нечитаемым.
Но есть и другой подход к созданию функций. Их стоит создавать не столько для того, чтобы использовать тот же код снова, сколько для абстрагирования от того, что происходит в отдельных строчках кода. Если несколько строчек кода были написаны для того, чтобы решить одну задачу, которой можно дать понятное название (например, подсчет какой-то особенной метрики, для которой нет готовой функции в R), то этот код стоит обернуть в функцию. Если функция работает корректно, то теперь не нужно думать над тем, что происходит внутри нее. Вы ее можете мысленно представить как операцию, которая имеет определенный вход и выход — как и встроенные функции в R.
The reason for writing a function is not to reuse its code, but to name the operation it performs.
— Tim “Agile Otter” Ottinger ((???)) January 22, 2013
3.2.5 Cемейство функций apply()
Семейство? Да, их целое множество: apply(), lapply(),sapply(), vapply(),tapply(),mapply(), rapply()… Ладно, не пугайтесь, всех их знать не придется. Обычно достаточно первых двух-трех. Проще всего пояснить как они работают на простой матрице с числами:
A <- matrix(1:12, 3, 4)
A ## [,1] [,2] [,3] [,4]
## [1,] 1 4 7 10
## [2,] 2 5 8 11
## [3,] 3 6 9 12Теперь представим, что нам нужно посчитать что-нибудь (например, сумму) по каждой из строк. С помощью функции apply() вы можете в буквальном смысле “применить” какую либо функцию к матрице или датафрейму. Правда, эта функция будет пытаться превратить датафрейм в матрицу, так что будьте осторожны. Синтаксис такой: apply(X, MARGIN, FUN, ...), где X — Ваши данные, MARGIN это 1 (для строк), 2 (для колонок), c(1,2) для строк и колонок (т.е. для каждого элемента по отдельности), а FUN — это функция, которую вы хотите применить, но без скобок ()! apply() будет брать строки/колонки из X в качестве первого аргумента для функции.
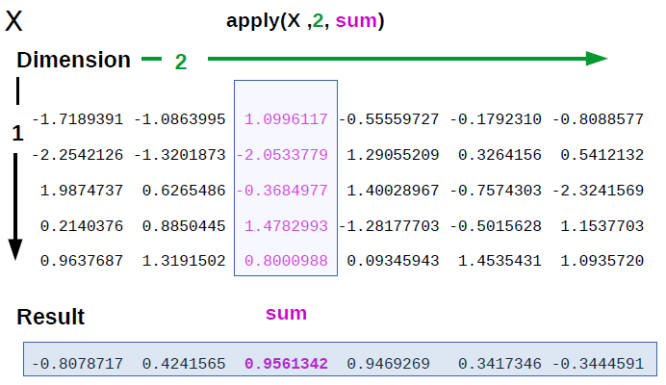
apply
Давайте разберем на примере:
apply(A, 1, sum) #сумма по каждой строчке## [1] 22 26 30apply(A, 2, sum) #сумма по каждой колонке## [1] 6 15 24 33apply(A, c(1,2), sum) #кхм... сумма каждого элемента## [,1] [,2] [,3] [,4]
## [1,] 1 4 7 10
## [2,] 2 5 8 11
## [3,] 3 6 9 12Заметьте, мы вставляем функцию (а не ее аутпут!) как инпут в функцию.

3.2.6 Анонимные функции
Если вдумаетесь, то тут возникает определенная сложность: функция apply() будет работать только в том случае, если функция принимает первым аргументом именно то, что мы ей даем… А если это не так? Тогда мы можем создать анонимные функции!
Еще можно написать нужные аргументы через запятую после аргумента FUN:
apply(A, 1, weighted.mean, w = c(0.2, 0.4, 0.3, 0.1)) ## [1] 4.9 5.9 6.9Анонимные функции - это функциии, которые будут использоваться один раз и без названия.
Питонистам знакомо понятие лямбда-функций. Да, это то же самое
Например, мы можем посчитать сумму квадратичных отклонений от среднего без называния этой функции:
apply(A, 1, function(x) sum((x-mean(x))^2))## [1] 45 45 45apply(A, 2, function(x) sum((x-mean(x))^2))## [1] 2 2 2 2apply(A, c(1,2), function(x) sum((x-mean(x))^2))## [,1] [,2] [,3] [,4]
## [1,] 0 0 0 0
## [2,] 0 0 0 0
## [3,] 0 0 0 0Как и в случае с обычной функцией, в качестве x выступает объект, с которым мы хотим что-то сделать, а дальше следует функция, которую мы собираемся применить к х. Можно использовать не х, а что угодно, как и в обычных функциях:
apply(A, 1, function(whatevername) sum((whatevername-mean(whatevername))^2))## [1] 45 45 45Ок, с apply() разобрались. А что с остальными? Некоторые из них еще проще и не требуют индексов, например, lapply (для применения к каждому элементу списка) и sapply() - упрощенная версия lapply(), которая пытается по возможности “упростить” результат до вектора или матрицы. Давайте теперь сделаем то же самое, что мы и делали (создание колонки got$Is.Alive), но с помощью sapply():
got$Is.Alive <- NA
got$Is.Alive <- sapply(got$Book.of.Death, function (x) ifelse(is.na(x), "Alive", "Dead"))Можно применять функции lapply() и sapply() на датафреймах. Поскольку фактически датафрейм - это список из векторов одинаковой длины (см. 2.6), то итерироваться эти функции будут по колонкам:
lapply(got, class)## $Name
## [1] "character"
##
## $Allegiances
## [1] "character"
##
## $Death.Year
## [1] "integer"
##
## $Book.of.Death
## [1] "integer"
##
## $Death.Chapter
## [1] "integer"
##
## $Book.Intro.Chapter
## [1] "integer"
##
## $Gender
## [1] "integer"
##
## $Nobility
## [1] "integer"
##
## $GoT
## [1] "integer"
##
## $CoK
## [1] "integer"
##
## $SoS
## [1] "integer"
##
## $FfC
## [1] "integer"
##
## $DwD
## [1] "integer"
##
## $Is.Alive
## [1] "character"Еще одна функция из семейства apply() - функция replicate() - самый простой способ повторить одну и ту же операцию много раз. Обычно это используется при симуляции данных и моделировании. Например, давайте сделаем выборку из логнормального распределения:
set.seed(1) #Это сделает выбор случайных чисел воспроизводимым
samp <- rlnorm(30)
hist(samp)
А теперь давайте сделаем 1000 таких выборок и из каждой возьмем среднее:
sampdist <- replicate(1000, mean(rlnorm(30)))
hist(sampdist)
Про функции для генерации случайных чисел и про визуализацию мы поговорим в следующие дни.
Если хотите познакомиться с семейством apply() чуточку ближе, то рекомендую вот этот туториал.
3.3 Работа с текстом
Работа с текстом - это отдельная и сложная задача. И у R есть мощные инструменты для этого!. Для более-менее продвинутой работы с текстом придется выучить специальный язык - “регулярные выражения” (regular expressions, regex, regexp). Регулярные выражения реализованы на многих языках, в том числе в R. Но мы пока обойдемся наиболее простыми функциями, которые покроют большую часть того, что нам нужно уметь делать при работе с текстом.
У нас есть две текстовые переменные - Name (имя персонажа) и Allegiances (дом, которому персонаж принадлежит/лоялен). Давайте попробуем вытащить всех персонажей, лояльных Старкам - как тех, у которых в Allegiances стоит "House Stark", так и тех, у кого стоит "Stark". В этом нам поможет функция grep(). Заметьте, что в этой функции необычного - первым ее аргументом является паттерн, который мы ищем, а не данные (как обычно).
Я рекомендую пока что ставить параметр
fixed = TRUE. Иначе он будет искать по правилам регулярных выражений (да, R по умолчанию работает именно с регулярными выражениями). Сейчас это не создаст нам проблем, а вот если будете искать что-то с математическими или другими знаками - проблемы будут возникать. Регулярные выражения - это специальный язык поиска сложных паттернов в тексте. Типа “Хочу все первые три знака после второго дефиса”. Он выглядит страшным и совершенно не читаемым, но в нем нет ничего сложного. Если Вам нужно много работать с текстом, то уделите один день освоению “регулярок”! По умолчанию с помощью функции grep() идет поиск именно по регулярным выражениям. Чтобы это отключить, мы и используем параметр fixed = TRUE.
grep("Stark", got$Allegiances, fixed = TRUE) ## [1] 17 25 29 30 47 53 56 65 69 85 90 91 107 108 110 127 128
## [18] 133 141 155 161 175 183 194 198 200 209 217 218 227 250 260 262 265
## [35] 272 286 326 328 340 342 343 346 348 353 362 367 381 392 397 398 405
## [52] 411 413 414 417 419 448 464 465 467 471 489 500 518 533 534 539 550
## [69] 561 570 576 581 590 607 613 623 645 647 664 686 697 698 699 702 705
## [86] 706 709 713 717 726 744 775 783 789 799 817 820 856 872 876 879 881
## [103] 894 896 897 898 899 912Результат — индексы, которые мы можем использовать, чтобы вытащить всех Старков:
starks <- got[grep("Stark", got$Allegiances, fixed = TRUE), ]
table(starks$Allegiances)##
## House Stark Stark
## 35 73Остались только Старки!
Если вы вдруг при чтении файла не поставили
stringsAsFactors = FALSE, то в полученной таблице останутся другие дома, пусть и с нулевыми значениями. Так работают факторы в R. Чтобы избавиться от “пустых” уровней факторов (иногда это нужно), можно воспользоваться простой функциейdroplevels(). С character колонками такой магии не нужно.
Хорошо, как находить что-то в текстовых переменных — разобрались. А как заменять? У нас здесь есть очевидная задача: cовместить все "House Stark" и просто "Stark", но для всех домов в оригинальном датасете. Для этого можно поменять все "House " на пустую строку "" с помощью функции gsub(). Она работает примерно так же как и grep(), но сначала ищет искомый паттерн ("House "), затем то, на что мы его меняем (""), потом наш вектор. На выходе мы получим новый вектор, который можно подставить взамен старой колонки got$Allegiances (или создать новую колонку got$Houses):
got$Houses <- gsub("House ", "", got$Allegiances, fixed = TRUE)
table(got$Allegiances)##
## Arryn Baratheon Greyjoy House Arryn
## 23 56 51 7
## House Baratheon House Greyjoy House Lannister House Martell
## 8 24 21 12
## House Stark House Targaryen House Tully House Tyrell
## 35 19 8 11
## Lannister Martell Night's Watch None
## 81 25 116 253
## Stark Targaryen Tully Tyrell
## 73 17 22 15
## Wildling
## 40Другая важная функция для работы с текстом: nchar() - количество знаков. Давайте найдем самое длинное имя в книгах Джорджа Мартина про лед, пламя, насилие и инцест:
max(nchar(got$Name))## [1] 3333 символа! Интересно, у кого же это?
longest <- which.max(nchar(got$Name)) #index of the longest name
got[longest, 1:2]## Name Allegiances
## 7 Aemon Targaryen (son of Maekar I) Night's WatchА, ну, конечно, вот это вот пояснение в скобочках все испортило. Давайте его уберем.
Для этого нам понадобится функция substr(). Она работает как “ножницы”: Сначала берем вектор значений, а потом два числа: откуда и покуда будем вырезать нужный кусок:
aemon <- substr(got$Name[longest], 1, 15)
aemon## [1] "Aemon Targaryen"got$Name[longest] <- aemon Ну и, конечно, нам нужно знать как объединять строки. Не в вектор, а в одно значение. Для этого есть простые функции paste() и paste0(). Для paste() можно выбрать разделить sep =, который по умолчанию является пробелом, а paste0() - это функция paste() с пустым разделителем по умолчанию:
paste("R", "is", "love")## [1] "R is love"paste0("R", "is", "love")## [1] "Rislove"Обратите внимание: функция paste() принимает в качестве аргуметов векторы, чтобы соединить их в один вектор. Если нужно превратить один строковый вектор в одно значение, то можно поставить какое-нибудь значение параметра collapse = (по дефолту это NULL):
phrase <- paste(c("All", "you", "need", "is", "love"), collapse = " <3 ")
phrase## [1] "All <3 you <3 need <3 is <3 love"Функция strsplit() делает наоборот - она разбирает значение на вектор с выбранным разделителем:
strsplit(phrase, split = " <3 ")## [[1]]
## [1] "All" "you" "need" "is" "love"Для тех, кто привык к C format (printf-style formatting), в R это можно сделать с помощью функции
sprintf():
sprintf("%i на кроссовки; Трачу деньги на %s и трачу их без остановки", 20000, "ерунду")## [1] "20000 на кроссовки; Трачу деньги на ерунду и трачу их без остановки"Пока что этого будет нам достаточно для работы с текстом. В принципе, этих функций достаточно в большинстве случаев. Если же вдруг нужно копнуть глубже - придется освоить язык регулярных выражений. Он кажется страшным, но это займет у Вас всего пару часов с вот этим удобным онлайн туториалом и этим онлайн инструментом. Для базовой работы с текстом в R есть вот эта немного занудная, но короткая книжка. В ней примерно все то же самое, что мы сегодня разобрали, но на более глубоком уровне.
3.4 Работа с дополнительными пакетами
Пакеты в R - это обычно набор функций (иногда датасетов и т.п.) с документацией по ним. Они нужны для того, чтобы выйти за рамки функциональности базового R или же просто для того, чтобы сделать работу в R еще удобнее. Для R есть более 15000 пакетов (по данным на февраль 2020 года), которые вы можете скачать с зеркал Comprehensive R Archive Network (CRAN) с помощью простой функции install.packages(), где в качестве основного аргумента используется вектор имен скачиваемых пакетов.
install.packages(c("data.table", "dplyr"))Для установки пакетов нужен интернет!
Эти 15000+ пакетов содержат в себе уйму всякого. Некоторые представляют собой буквально одну удобную функцию, некоторые посвящены какой-то узкоспециализированной теме (например, работе с текстом), есть даже просто наборы всякой всячины от того или иного разработчика (например, пакет Hmisc). Кроме того, можно устанавливать пакеты из других источников и делать собственные.
После установки пакета Вы увидете его во вкладке Packages справа внизу
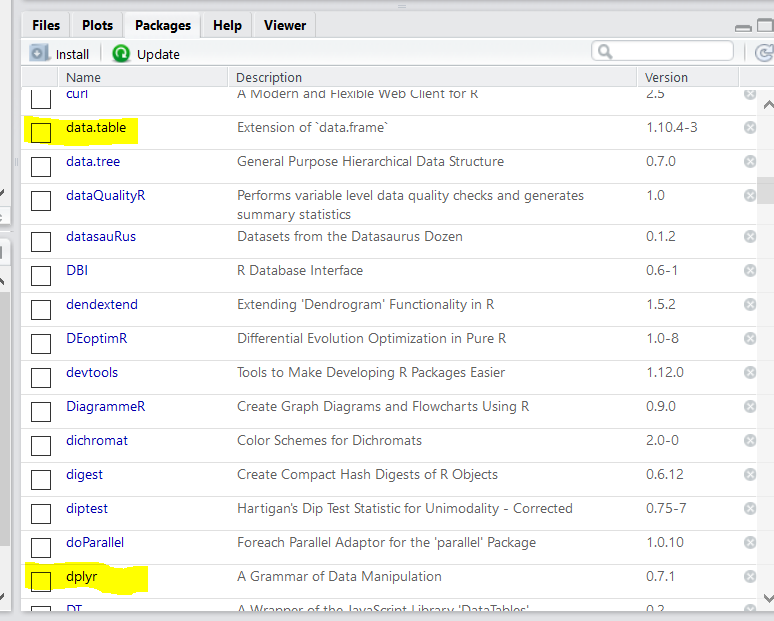
Затем нужно “присоединить” этот пакет. Запомните: устанавливаете пакет всего один раз, а присоединяете его в каждой новой сессии.
library("dplyr")
3.5 Решейпинг данных
Теперь мы возьмем данные по битвам из книг про Игру Престолов. Каждая строчка означает какую-то битву, описанную в книгах нашего любомого пухляша-бородача. Подробную информацию про набор данных можно найти здесь. Скачать данные можно здесь
bat <- read.csv("data/battles.csv")После освоения базовых возможностей датафрейма, становится понятно, что чего-то не хватает. Допустим, мы хотим узнать, в каких годах были наиболее эпичные битвы. Нам нужно посчитать среднее количество бойцов атакующей армии по годам. Зная все года битв, можно сделать так:
mean(bat[bat$year == 298, "attacker_size"], na.rm = T)## [1] 11175mean(bat[bat$year == 299, "attacker_size"], na.rm = T)## [1] 5134.308mean(bat[bat$year == 300, "attacker_size"], na.rm = T)## [1] 19333.33Всякий раз, когда у Вас возникает желание сделать что-нибудь с помощью священного копипаста - задумайтесь: разве ради этого Вы пришли на курс? Конечно, нет! Как говорилось ранее, если появляется желание копипастить одни и те же строчки, это означает, что, скорее всего, это можно сделать быстрее, проще и лучше.
Конечно, стандартными возможностями R, которые мы уже освоили, нашу задачу можно выполнить, но довольно неудобно:
sapply(unique(bat$year), function(x) mean(bat$attacker_size[bat$year == x], na.rm = T))## [1] 11175.000 5134.308 19333.333В принципе, есть много других способов сделать то же самое - функция
aggregate(),split(), но мы на них останавливаться не будем.
Тем не менее, задача аггрегации данных - это то, что необходимо постоянно. Усреднить значения по каждому испытуемому, получить средние значения по каждому из уровней всех переменных… А если нужно не усреднять, а делать что-то более сложное? Очевидно, что тут нам нужны какие-то новые инструменты, которых мы еще не знаем. И здесь у нас появляется важная развилка - есть два разных пакета, которые позволяют удобно делать агрегацию и другие операции, о которых мы говорили раньше (например, сабсеттинг) и о которых мы еще поговорим позднее.
3.5.1 data.table vs. dplyr
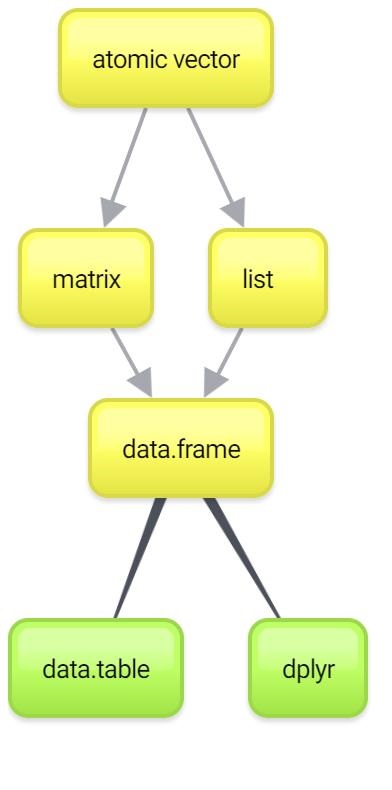
Начнем с пакета dplyr от создателя ggplot2 (а еще tidyr, stringr, lubridate, devtools, httr, readr и много других популярных пакетов для R) Хэдли Уиэкхэма.
Сейчас этот парень работает в RStudio, следы чего вы можете обнаружить. Например, откройте Help - Cheatsheets: Вы обнаружите читшиты для dplyr. Но не для data.table =)
Этот подход сильно перерабатывает синтаксис R, отличается понятностью и читаемостью. Более того, он очень популярен, многие пакеты предполагают, что Вы именно с ним работаете и хорошо им владеете.
library("dplyr")
bat %>% group_by(year) %>% summarise(mean(attacker_size, na.rm = T))## # A tibble: 3 x 2
## year `mean(attacker_size, na.rm = T)`
## <int> <dbl>
## 1 298 11175
## 2 299 5134.
## 3 300 19333.Просто попытайтесь догадаться, что значат эти строчки: берем датафрейм, группируем по году, выводим какую-то суммирующию информацию по каждой группе.
Оператор %>% называется “пайпом” (pipe), т.е. “трубой”. Он означает, что следующая функция принимает на вход в качестве первого аргумента аутпут предыдущей. Фактически, это примерно то же самое, что и вставлять аутпут функции как первый инпут в другую функцию. Просто выглядит это красивее и читабельнее. Как будто данные пропускаются через трубы функций или конвеерную ленту на заводе, если хотите. А то, что первый параметр функции - это почти всегда данные, работает нам на руку. Этот оператор взят из пакета magrittr. Возможно, даже если вы не захотите пользоваться dplyr, использование пайпов Вам понравится. Ну а если нет, то тогда вперед к data.table!
Множество пакетов, опирающихся и дополняющих dplyr (magrittr, purrr, stringr, readr, tidyr, tibble и т.д.), называют “tidyverse”. Эти пакеты предлагают альтернативные варианты для многих операций в R. Например, stringr дает удобные функции для работы со строковыми данными (фактически заменяя стандартные), пакет readr заменяет стандартный импорт данных, а purrr - функции типа apply(). Выходит, что это уже практически новый язык!
Другой подход - пакет data.table. Он не так сильно перерабатывает стиль работы в R, но изменяет датафреймы, “совершенствуя” их. Этот пакет сильно повышает скорость обработки данных, поскольку написан с использованием более совершенных алгоритмов. data.table обладает более “суровым” и лаконичным синтаксисом:
library("data.table")
batdt <- as.data.table(bat)
batdt[,mean(attacker_size, na.rm = T), by = year]## year V1
## 1: 298 11175.000
## 2: 299 5134.308
## 3: 300 19333.333Внешне все очень похоже на работу с обычным data.frame, но если приглядитесь, то увидите, что появился непонятный by = - это как раз-таки группировка. Более того, мы делаем анализ прямо в том месте, где раньше просто выбирали столбцы. Да и столбцы эти (как и строчки) мы выбираем без кавычек.
3.5.2 Так что же выбрать?
Мы остановимся на data.table. В принципе, если Вы освоили один пакет, то альтернативный пакет уже не нужен - про это можете почитать замечательную дискуссию от создателей пакетов. Основной вывод - оба пакета позволяют делать нужные нам вещи, но разными способами.
3.5.3 data.table
Мы начнем с очень милой функции под названием fread(). Эта функция похожа на функцию read.table(), но быстрее (воистину!) и автоматически подбирает параметры чтения файлов (обычно правильно). В большинстве случаев Вы можете просто использовать эту функцию без задания каких-либо параметров для чтения таблицы - и готово!
batdt <- fread("data/battles.csv")Ну, на этом датасете Вы едва ли заметите разницу в скорости, а вот если у вас датасет побольше, скажем, на несколько десятков мегабайт, то разница будет заметна.
Заметьте, теперь это уже не совсем датафрейм:
class(batdt)## [1] "data.table" "data.frame"Одновременно датафрейм и дататейбл! Это означает, что почти все, что мы умеем делать с датафреймом, мы можем делать так же и с дататейблом, но теперь нам открываются новые возможности (и новый синтаксис).
Некоторые используют пакет data.table только для того, чтобы быстрее загружать данные. Если Вы захотите пойти этим путем, то нужно поставить параметр
data.table = FALSE- тогда данные загрузятся как “чистый” датафрейм. Кроме того, в R можно использовать функцию, не подключая весь пакет с помощью оператора::. То есть вот так:
batdataframe <- data.table::fread("data/battles.csv", data.table = FALSE)Этот оператор
::еще рекомендуется использовать, если у Вас есть есть несколько одноименных функций для одного и того же из разных пакетов, и есть риск запутаться в том, какой именно пакет вы используете.
3.5.3.1 Основы data.table
data.table обладает своим синтаксисом, напоминающим SQL (если Вы не знаете, что это, то Вы счастливый человек; ну а если знаете, то быстрее освоитесь). Главная формула звучит так:
DT[i, j, by]
Здесь i - это то, какие Вы выбираете строки. Очень похоже на обычный data.frame, не так ли? j - это то, что Вы считаете. Это тоже похоже на датафрейм - Вы выбираете колонки. Но тут есть важное различие - можно что-то считать прямо внутри j, т.е. внутри квадратных скобочек! by - это аггрегация по подгруппам.
“General form: DT[i, j, by] “Take DT, subset rows using
i, then calculatejgrouped byby” (из читшита по data.table). Если проводить аналогии с SQL, то i = WHERE, j = SELECT | UPDATE, by = GROUP BY.
Естественно, далеко не всегда используются сразу все три i, j и by. Но это дает прекрасные возможности делать сложные операции с данными в одну строчку. Как и в датафрейме, если Вы хотите выбрать все строчки, просто оставляете поле перед первой запятой пустым. Если не хотите делать группировку, то можете просто не писать вторую запятую. Если же не писать вообще запятых внутри квадратных скобок, то все внутри будет считаться как i, т.е. Вы будете выбирать только строки. Но я советую все-таки ставить одну запятую, чтобы не запутаться с тем, где выбираются строки (i), а где производятся манипуляции с колонками (j).
Скажем, мы хотим посчитать средний размер защищающихся армий только для битв, где победили атакующие, группируя по регионам:
batdt[attacker_outcome == "win", mean(attacker_size, na.rm = TRUE), by = region]## region V1
## 1: The Westerlands 9000.000
## 2: The Riverlands 4425.000
## 3: The North 1107.667
## 4: The Stormlands 3500.000
## 5: The Reach NaNГотово!
Давайте разберем этот пример подробнее:
i: выбираем только те строки, гдеattacker_outcomeравен"win". Заметьте, мы тут используем не вектор (как если бы это была переменная), а название колонки и без кавычек!j: прямо вjсчитаем средний размер атакующей армии. Опять же - без кавычек используем название столбца.by: группируем по региону. То есть как бы делим дататейбл на пять дататейблов и применяем функцию среднего для каждого.
В итоге мы получили новый дататейбл!
По умолчанию новому столбцу будет присваиваться название V1 (а если такая колонка есть, то V2 и т.д.), но можно присвоить и свое название колонки. Для этого используйте круглые скобки и точку перед ними:
batdt[attacker_outcome == "win",
.(mean_attack = mean(attacker_size, na.rm = TRUE)),
by = region]## region mean_attack
## 1: The Westerlands 9000.000
## 2: The Riverlands 4425.000
## 3: The North 1107.667
## 4: The Stormlands 3500.000
## 5: The Reach NaN.() - это то же самое, что и list(). То есть мы создаем список, а это значит, что мы можем сделать сразу несколько операций:
batdt[attacker_outcome == "win",
.(mean_attack = mean(attacker_size, na.rm = TRUE),
max_attacker = max(attacker_size, na.rm = TRUE)),
by = region]## Warning in gmax(attacker_size, na.rm = TRUE): No non-missing values found
## in at least one group. Coercing to numeric type and returning 'Inf' for
## such groups to be consistent with base## region mean_attack max_attacker
## 1: The Westerlands 9000.000 15000
## 2: The Riverlands 4425.000 15000
## 3: The North 1107.667 4500
## 4: The Stormlands 3500.000 5000
## 5: The Reach NaN -InfЧтобы аггрегировать по двум условиям, нужно использовать конструкцию с .() в by:
batdt[,.(mean_attack = mean(attacker_size, na.rm = TRUE)), by = .(region, attacker_outcome)]## region attacker_outcome mean_attack
## 1: The Westerlands win 9000.000
## 2: The Riverlands win 4425.000
## 3: The Riverlands loss 19000.000
## 4: The North win 1107.667
## 5: The Stormlands win 3500.000
## 6: The Crownlands loss 12000.000
## 7: Beyond the Wall loss 100000.000
## 8: The Reach win NaN
## 9: The North 5000.0003.5.3.2 Создание новых колонок
В data.table есть специальный оператор := для создания новых колонок.
Давайте создадим новую колонку, по которой будет проще понять, кто победил в битве:
batdt[,outcome:=ifelse(attacker_outcome == "win",
"Победа атакующих",
ifelse(attacker_outcome == "loss",
"Победа защищающихся",
"Исход неизвестен"))]Оператор
:=создает поверхностную копию, т.е. не копирует физически данные.
Заметьте, мы даже не присваиваем результат выполнения этой операции новой переменной: просто в нашем batdt появилась новая колонка.
Если мы хотим создать сразу несколько столбцов за раз, то можно использовать оператор
:=как функцию:
batdt[, ':='(all_army = attacker_size + defender_size,
ratio_army = attacker_size / defender_size)]3.5.3.3 Chaining
Chaining (формирование цепочки) - это что-то вроде альтернативы пайпам. В принципе, это можно делать и с обычным датафреймом или матрицей, но именно с data.table это становится удобным и клевым инструментом. А также способом “сделать весь анализ в одну очень длинную строчку”. Все просто - результатом вычислений в data.table обычно является новый data.table. И ничто не мешает нам делать несколько квадратных скобочек, превращая код в паравозик со множеством вагонов. Это позволяет избежать промежуточных присвоений переменных, как и в случае с пайпами.
Давайте шаг за шагом создадим такой паровозик для того, чтобы сделать таблицу частот битв по регионам.
Для начала нам нужно посчитать длину столбцов. Для этого в data.table есть .N, и это гораздо удобнее, чем считать length() какого-нибудь столбца:
batdt[.N,]## name year battle_number attacker_king
## 1: Siege of Winterfell 300 38 Stannis Baratheon
## defender_king attacker_1 attacker_2 attacker_3 attacker_4
## 1: Joffrey/Tommen Baratheon Baratheon Karstark Mormont Glover
## defender_1 defender_2 defender_3 defender_4 attacker_outcome
## 1: Bolton Frey NA NA
## battle_type major_death major_capture attacker_size defender_size
## 1: NA NA 5000 8000
## attacker_commander defender_commander summer location region note
## 1: Stannis Baratheon Roose Bolton 0 Winterfell The North
## outcome all_army ratio_army
## 1: Исход неизвестен 13000 0.625Заметьте, мы используем
.Nв j (т.е. после первой запятой). Если мы используем.Nвi, то получим просто последнюю строчку дататейбла.
Если же мы аггрегируем по регионам, то получим таблицу частот регионов - что нам и нужно:
batdt[,.N, by = region]## region N
## 1: The Westerlands 3
## 2: The Riverlands 17
## 3: The North 10
## 4: The Stormlands 3
## 5: The Crownlands 2
## 6: Beyond the Wall 1
## 7: The Reach 2Отличная альтернатива функции table()!
Можно было сохранить результат в новой переменной, а можно просто продолжить работать с получившимся дататейблом, “дописывая” его.
batdt[,.N, by = region][order(-N),]## region N
## 1: The Riverlands 17
## 2: The North 10
## 3: The Westerlands 3
## 4: The Stormlands 3
## 5: The Crownlands 2
## 6: The Reach 2
## 7: Beyond the Wall 1Теперь мы отсортировали регионы по количеству битв. Мы используем функцию order(), чтобы посчитать ранг каждого значения нового столбца N, а потом использовать значения этого столбца для выбора строк в нужном порядке. Добавление минуса позволяет “инвертировать” этот порядок, чтобы получилось от большего к меньшему.
batdt[,.N, by = region][order(-N),][N>2,]## region N
## 1: The Riverlands 17
## 2: The North 10
## 3: The Westerlands 3
## 4: The Stormlands 3Продолжая наш паровозик, мы “отрезали” от получившегося дататейбла только те регионы, где N больше двух.
Для лучшей читаемости можно организовать цепочку таким образом:
batdt[,.N, by = region
][order(-N),
][N>2,]## region N
## 1: The Riverlands 17
## 2: The North 10
## 3: The Westerlands 3
## 4: The Stormlands 33.5.4 Широкий и длинный форматы данных
Что если есть несколько измерений по одному испытуемому? Например, вес до и после прохождения курса. Как это лучше записать - как два числовых столбца (один испытуемый - одна строка) или же создать отдельную “группирующую” колонку, в которой будет написано время измерения, а в другой - измеренные значения (одно измерение - одна строка)? На самом деле, оба варианта приемлимы, оба варианта возможны в реальных данных, а разные функции и статистические пакеты могут требовать от вас как “длинный”, так и “широкий” форматы.
3.5.4.1 “Широкий” формат
| Студент | До курса по R | После курса по R |
|---|---|---|
| Маша | 70 | 63 |
| Рома | 80 | 74 |
| Антонина | 86 | 71 |
3.5.4.2 “Длинный” формат
| Студент | Время измерения | Вес (кг) |
|---|---|---|
| Маша | До курса по R | 70 |
| Рома | До курса по R | 80 |
| Антонина | До курса по R | 86 |
| Маша | После курса по R | 63 |
| Рома | После курса по R | 74 |
| Антонина | После курса по R | 71 |
3.5.5 Решейпинг в data.table: melt() и dcast()
Таким образом, нам нужно научиться переводить из широкого формата в длинный и наоборот. Это может показаться довольно сложной задачей, но для это в data.table есть специальные функции:
melt()(= “плавление”): из широкого в длинный форматdcast()(= “литье”): из длинного в широкий формат
3.5.5.1 Пример 1: melt() для размера армий
В нашем дататейбле batdt у нас есть две колонки, которые содержат информацию про размер армий: attacker_size и defender_size.
head(batdt[, .(name, year, attacker_size, defender_size)])## name year attacker_size defender_size
## 1: Battle of the Golden Tooth 298 15000 4000
## 2: Battle at the Mummer's Ford 298 NA 120
## 3: Battle of Riverrun 298 15000 10000
## 4: Battle of the Green Fork 298 18000 20000
## 5: Battle of the Whispering Wood 298 1875 6000
## 6: Battle of the Camps 298 6000 12625Это пример широкого формата: у нас два измерения на каждую битву. Допустим, мы хотим сделать длинный формат. В новом дататейбле будет “группирующая” колонка battle_role, а все размеры армий будут в новой колонке army_size:
batlong <- melt(batdt,
measure.vars = c("attacker_size", "defender_size"),
variable.name = "battle_role",
value.name = "army_size")Теперь новый дататейбл batlong в два раза длиннее оригинального, а названия колонок attacker_size и defender_size превратились в значения колонки battle_role.
Важные параметры функции melt():
data- Ваш data.tableid.vars- вектор имен id. Можно не ставить, если у нас “чистый” длинный формат.measure.vars- вектор названий колонок (т.е. в кавычках!), которые содержат измерения Note:melt()удалит в новом дататейбле все колонки, которые вы написали вid.varsиmeasure.vars.variable.name- название новой “группирующей” колонкиvalue.name- название новой колонки с измерениями
3.5.5.2 Пример 2: dcast() для размера армий
А теперь обратно к широкому формату!
Функция dcast() использует формулы. Это новый для нас тип данных, но мы с ним еще столкнемся, когда перейдем к статистическим тестам и моделям, поэтому давайте немного ознакомимся с ними. Собственно, для задания статистических моделей формулы в R и существуют, но иногда они используются и в других случаях.
class(y ~ x1 + x2 * x3)## [1] "formula"В формуле обязательно присутствует тильда (~ - в клавиатуре на кнопке “ё”), которая разделяет левую и правую часть.
Давайте вернемся к dcast()
batwide <- dcast(batlong,
... ~ battle_role,
value.var = "army_size")Мы практически вернулись к исходному batdt, разве что колонки в другой последовательности.
3.5.6 Объединение с помощью rbind(), cbind() и merge()
Допустим, у нас есть два дататейбла. Мы создадим немного искусственную ситуацию, разделив длинный дататейбл на два:
bat_at <- batlong[battle_role == "attacker_size",]
bat_def <- batlong[battle_role == "defender_size",]Ну а теперь попробуем склеить их обратно!
Для этого есть три замечательные функции: rbind(), cbind() и merge().
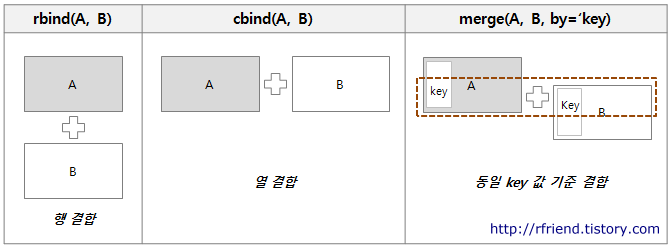
С первымии двумя все просто. rbind() соединяет вертикально, а cbind() - горизонтально.
verylong_bat <-cbind(bat_at, bat_def) #c stands for columnsh_bat это результат вертикального соединения. По сути, мы почти вернулись к batlong
verywide_bat <- rbind(bat_at, bat_def) #r stands for rowsА теперь мы сделали горизонтальное соединение, получив ооочень широкий дататейбл с повторяющимися колонками.
Самое сложное (и самое интересное!) - это merge().
На практике часто случается, что нужно объединить два датасета. Например, поведенческие данные с какими-нибудь метриками ЭЭГ. Скажем, время реакции на задачу и мощность альфа-ритма. Или, например, мы хотим добавить в набор данных информацию о поле и возрасте, которая у нас хранится в отдельной табличке. Все, что объединяет два датасета - это id испытуемых, по которым нужно составить новую табличку.
Другая проблема может возникнуть, когда мы сделали какой-то анализ с данными, что-то аггрегировали, посчитали, а теперь это нужно вставить в оригинальный датасет. Давайте решим такую задачу: создадим сабсет из нашего batdt, в котором будут только битвы, которые проходили в регионах, где было больше двух битв.
Первую часть этой задачи мы уже делали сегодня: считали частоты по регионам, а потом оставляли только регионы с больше чем двумя битвами:
batdt[,.N, by = region][order(-N),][N>2,]## region N
## 1: The Riverlands 17
## 2: The North 10
## 3: The Westerlands 3
## 4: The Stormlands 3Сохраним этот результат в переменную hot_regions.
hot_regions <- batdt[,.N, by = region][order(-N),][N>2,]Теперь воспользуемся merge():
subset_batdt <- merge(hot_regions, batdt,
by = "region",
all.x = TRUE, all.y = FALSE)Получилось! А теперь чуть подробнее, о том, что мы сделали.
Первые два аргумента в merge() - это дататейблы. by = это тот самый айди, который должен совпадать у обоих дататейблов. Это может быть не одна, а сразу несколько колонок. В качестве значения по умолчанию используются все общие колонки двух дататейблов. Если названия не совпадают, то их можно прописать в by.x = и by.y = отдельно.
Следующие важные варианты - это all.x = и all.y =. С помощью этих параметров мы прописываем, что нужно сделать, если список айдишников (в нашем случае - регионов) не совпадает. Они могут принимать значения TRUE и FALSE, в зависимости от этого есть 4 варианта:
all = T: добавит новые строки, если в каком-то из дататейблов каких-то значений нет. Что-то вроде логического “ИЛИ” для выбора строк: если хотя бы в одном дататейбле есть строки с каким-то айди, то они добавятся в получившийся дататейбл.
all.x = T, all.y = F: возьмет все строки из первого дататейбла, но проигнорирует все строки с айдишниками, которых нет во втором дататейбле.
all.x = F, all.y = T: возьмет все строки из второго дататейбла, но проигнорирует лишние строки из первого.
all.x = F, all.y = F: возьмет только строчки, айдишники которых пересекаются в обоих дататейблах.
Мы взяли именно второй вариант. Взяли все регионы из hot_regions и проигнорировали те регионы, что встречаются только в batdt.
3.6 Заключение
Итак, мы научились делать самые сложные штуки в R (из тех, которые жизненно необходимы вне зависимости от данных). Сабсетить данные, агрегировать, вертеть их, соединять… На самом деле, подобные вещи отнимают большую часть времени, и они не раз нам понадобятся в будущем. С другой стороны, какие-то сложные вещи, например, melt(), dcast() и merge() сложно запомнить сразу. И это нормально, главное - понимать, в какую сторону гуглить и какие заметки смотреть в случае необходимости.
Кстати говоря, для более глубокого погружения в data.table есть замечательный туториал, переведенный на русский язык.
Если в последней строчке будет присвоение, то функция ничего не вернет обратно. Это очень распространенная ошибка: функция вроде бы работает правильно, но ничего не возвращает. Нужно писать так, как будто бы в последней строчке результат выполнения выводится в консоль.↩