4 Сложные структуры данных в R
4.1 Матрица
Если вдруг вас пугает это слово, то совершенно зря. Матрица (matrix) — это всего лишь “двумерный” вектор: вектор, у которого есть не только длина, но и ширина. Создать матрицу можно с помощью функции matrix() из вектора, указав при этом количество строк и столбцов.
A <- matrix(1:20, nrow=5,ncol=4)
A## [,1] [,2] [,3] [,4]
## [1,] 1 6 11 16
## [2,] 2 7 12 17
## [3,] 3 8 13 18
## [4,] 4 9 14 19
## [5,] 5 10 15 20Заметьте, значения вектора заполняются следующим образом: сначала заполняется первый столбик сверху вниз, потом второй сверху вниз и так до конца, т.е. заполнение значений матрицы идет в первую очередь по вертикали. Это довольно стандартный способ создания матриц, характерный не только для R.
Если мы знаем сколько значений в матрице и сколько мы хотим строк, то количество столбцов указывать необязательно:
A <- matrix(1:20, nrow=5)
A## [,1] [,2] [,3] [,4]
## [1,] 1 6 11 16
## [2,] 2 7 12 17
## [3,] 3 8 13 18
## [4,] 4 9 14 19
## [5,] 5 10 15 20Все остальное так же как и с векторами: внутри находится данные только одного типа. Поскольку матрица — это уже двумерный массив, то у него имеется два индекса. Эти два индекса разделяются запятыми.
A[2,3]## [1] 12A[2:4, 1:3]## [,1] [,2] [,3]
## [1,] 2 7 12
## [2,] 3 8 13
## [3,] 4 9 14Первый индекс — выбор строк, второй индекс — выбор колонок. Если же мы оставляем пустое поле вместо числа, то мы выбираем все строки/колонки в зависимости от того, оставили мы поле пустым до или после запятой:
A[, 1:3]## [,1] [,2] [,3]
## [1,] 1 6 11
## [2,] 2 7 12
## [3,] 3 8 13
## [4,] 4 9 14
## [5,] 5 10 15A[2:4, ]## [,1] [,2] [,3] [,4]
## [1,] 2 7 12 17
## [2,] 3 8 13 18
## [3,] 4 9 14 19A[, ]## [,1] [,2] [,3] [,4]
## [1,] 1 6 11 16
## [2,] 2 7 12 17
## [3,] 3 8 13 18
## [4,] 4 9 14 19
## [5,] 5 10 15 20Так же как и в случае с обычными векторами, часть матрицы можно переписать:
A[2:4, 2:4] <- 100
A## [,1] [,2] [,3] [,4]
## [1,] 1 6 11 16
## [2,] 2 100 100 100
## [3,] 3 100 100 100
## [4,] 4 100 100 100
## [5,] 5 10 15 20В принципе, это все, что нам нужно знать о матрицах. Матрицы используются в R довольно редко, особенно по сравнению, например, с MATLAB. Но вот индексировать матрицы хорошо бы уметь: это понадобится в работе с датафреймами.
То, что матрица — это просто двумерный вектор, не является метафорой: в R матрица — это по сути своей вектор с дополнительными атрибутами
dimи (опционально)dimnames. Атрибуты — это свойства объектов, своего рода “метаданные.” Для всех объектов есть обязательные атрибуты типа и длины и могут быть любые необязательные атрибуты. Можно задавать свои атрибуты или удалять уже присвоенные: удаление атрибутаdimу матрицы превратит ее в обычный вектор. Про атрибуты подробнее можно почитать здесь или на стр. 99-101 книги “R in a Nutshell” (Adler 2010).
4.2 Массив
Два измерения — это не предел! Структура с одним типом данных внутри, но с тремя измерениями или больше, называется массивом (array). Создание массива очень похоже на создание матрицы: задаем вектор, из которого будет собран массив, и размерность массива.
array_3d <- array(1:12, c(3, 2, 2))
array_3d## , , 1
##
## [,1] [,2]
## [1,] 1 4
## [2,] 2 5
## [3,] 3 6
##
## , , 2
##
## [,1] [,2]
## [1,] 7 10
## [2,] 8 11
## [3,] 9 124.3 Список
Теперь представим себе вектор без ограничения на одинаковые данные внутри. И получим список (list)!
simple_list <- list(42, "Пам пам", TRUE)
simple_list## [[1]]
## [1] 42
##
## [[2]]
## [1] "Пам пам"
##
## [[3]]
## [1] TRUEА это значит, что там могут содержаться самые разные данные, в том числе и другие списки и векторы!
complex_list <- list(c("Wow", "this", "list", "is", "so", "big"), "16", simple_list)
complex_list## [[1]]
## [1] "Wow" "this" "list" "is" "so" "big"
##
## [[2]]
## [1] "16"
##
## [[3]]
## [[3]][[1]]
## [1] 42
##
## [[3]][[2]]
## [1] "Пам пам"
##
## [[3]][[3]]
## [1] TRUEЕсли у нас сложный список, то есть очень классная функция, чтобы посмотреть, как он устроен, под названием str():
str(complex_list)## List of 3
## $ : chr [1:6] "Wow" "this" "list" "is" ...
## $ : chr "16"
## $ :List of 3
## ..$ : num 42
## ..$ : chr "Пам пам"
## ..$ : logi TRUEПредставьте, что список - это такое дерево с ветвистой структурой. А на конце этих ветвей - листья-векторы.
Как и в случае с векторами мы можем давать имена элементам списка:
named_list <- list(age = 24, PhDstudent = T, language = "Russian")
named_list## $age
## [1] 24
##
## $PhDstudent
## [1] TRUE
##
## $language
## [1] "Russian"К списку можно обращаться как с помощью индексов, так и по именам. Начнем с последнего:
named_list$age## [1] 24А вот с индексами сложнее, и в этом очень легко запутаться. Давайте попробуем сделать так, как мы делали это раньше:
named_list[1]## $age
## [1] 24Мы, по сути, получили элемент списка — просто как часть списка, т.е. как список длиной один:
class(named_list)## [1] "list"class(named_list[1])## [1] "list"А вот чтобы добраться до самого элемента списка (и сделать с ним что-то хорошее), нам нужна не одна, а две квадратных скобочки:
named_list[[1]]## [1] 24class(named_list[[1]])## [1] "numeric"Indexing lists in #rstats. Inspired by the Residence Inn pic.twitter.com/YQ6axb2w7t
— Hadley Wickham ((hadleywickham?)) September 14, 2015
Как и в случае с вектором, к элементу списка можно обращаться по имени.
named_list[['age']]## [1] 24Хотя последнее — практически то же самое, что и использование знака $.
Списки довольно часто используются в R, но реже, чем в Python. Со многими объектами в R, такими как результаты статистических тестов, удобно работать именно как со списками — к ним все вышеописанное применимо. Кроме того, некоторые данные мы изначально получаем в виде древообразной структуры — хочешь не хочешь, а придется работать с этим как со списком. Но обычно после этого стоит как можно скорее превратить список в датафрейм.
4.4 Датафрейм
Итак, мы перешли к самому главному. Самому-самому. Датафреймы (data.frames). Более того, сейчас станет понятно, зачем нам нужно было разбираться со всеми предыдущими темами.
Без векторов мы не смогли бы разобраться с матрицами и списками. А без последних мы не сможем понять, что такое датафрейм.
name <- c("Ivan", "Eugeny", "Lena", "Misha", "Sasha")
age <- c(26, 34, 23, 27, 26)
student <- c(F, F, T, T, T)
df <- data.frame(name, age, student)
dfstr(df)## 'data.frame': 5 obs. of 3 variables:
## $ name : chr "Ivan" "Eugeny" "Lena" "Misha" ...
## $ age : num 26 34 23 27 26
## $ student: logi FALSE FALSE TRUE TRUE TRUEВообще, очень похоже на список, не правда ли? Так и есть, датафрейм — это что-то вроде проименованного списка, каждый элемент которого является atomic вектором фиксированной длины. Скорее всего, список Вы представляли “горизонтально.” Если это так, то теперь “переверните” его у себя в голове на 90 градусов. Так, чтоб названия векторов оказались сверху, а колонки стали столбцами. Поскольку длина всех этих векторов равна (обязательное условие!), то данные представляют собой табличку, похожую на матрицу. Но в отличие от матрицы, разные столбцы могут имет разные типы данных. В нашем случае первая колонка — character, вторая колонка — numeric, третья колонка — logical. Тем не менее, обращаться с датафреймом можно и как с проименованным списком, и как с матрицей:
df$age[2:3]## [1] 34 23Здесь мы сначала вытащили колонку age с помощью оператора $. Результатом этой операции является числовой вектор, из которого мы вытащили кусок, выбрав индексы 2 и 3.
Используя оператор $ и присваивание можно создавать новые колонки датафрейма:
df$lovesR <- T #правило recycling - узнали?
dfНу а можно просто обращаться с помощью двух индексов через запятую, как мы это делали с матрицей:
df[3:5, 2:3]Как и с матрицами, первый индекс означает строчки, а второй — столбцы.
А еще можно использовать названия колонок внутри квадратных скобок:
df[1:2,"age"]## [1] 26 34И здесь перед нами открываются невообразимые возможности! Узнаем, любят ли R те, кто моложе среднего возраста в группе:
df[df$age < mean(df$age), 4]## [1] TRUE TRUE TRUE TRUEЭту же задачу можно выполнить другими способами:
df$lovesR[df$age < mean(df$age)]## [1] TRUE TRUE TRUE TRUEdf[df$age < mean(df$age), 'lovesR']## [1] TRUE TRUE TRUE TRUEВ большинстве случаев подходят сразу несколько способов — тем не менее, стоит овладеть ими всеми.
Датафреймы удобно просматривать в RStudio. Для это нужно написать команду View(df) или же просто нажать на названии нужной переменной из списка вверху справа (там где Environment). Тогда увидите табличку, очень похожую на Excel и тому подобные программы для работы с таблицами. Там же есть и всякие возможности для фильтрации, сортировки и поиска…9
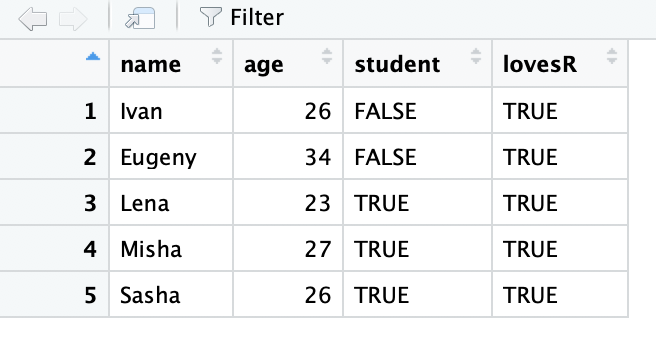
Но, конечно, интереснее все эти вещи делать руками, т.е. с помощью написания кода.
Все, что вы нажмете в этом окошке, никак не повлияет на исходную переменную. Так что можете смело использовать эти функции для исследования содержимого датафрейма.↩︎