10 Описательная статистика
10.1 Описательная статистика и статистика вывода
Статистика делится на описательную статистику (descriptive statistics) и статистику вывода (inferential statistics). Описательная статистика пытается описать нашу выборку (sample, т.е. те данные, что у нас на руках) различными способами. Проблема в том, что описательная статистика может описать только то, что у нас есть, но не позволяет сделать выводы о генеральной совокупности (population) - это уже цель статистики вывода. Цель описательной статистики - “ужать” данные для их обобщенного понимания с помощью статистик.
Заметьте, у выборки (sample) мы считаем статистики (statistics), а у генеральной совокупности (Population) есть параметры (Parameters). Вот такая вот мнемотехника.
Статистики часто выступают в роли точечной оценки (point estimators) параметров, так что в этом легко запутаться. Например, среднее (в выборке) - это оценка среднего (в генеральной совокупности). Да, можно свихнуться. Мы это будем разбирать подробнее в следующие занятия (это действительно важно, поверьте), пока что остановимся только на описании выборки.
10.2 Типы шкал
Перед тем, как начать речь об описательных статистиках, нужно разобраться с существующими типами шкал. Типы шкал классифицируются на основании типа измеряемых данных, которые задают допустимые для данной шкалы отношения.
- Шкала наименований (номинальная шкала) — самая простая шкала, где единственное отношение между элементами — это отношения равенства и неравенства. Это любая качественная шкала, между элементами которой не могут быть установлены отношения “больше — меньше.” Это большинство группирующих переменных (экспериментальная группа, пол, политическая партия, страна), переменные с id. Еще один пример - номера на майках у футболистов.
- Шкала порядка (ранговая шкала) — шкала следующего уровня, для которой можно установить отношения “больше — меньше,” причем если B больше A, а C больше B, то и C должно быть больше A. Если это верно, то мы можем выстроить последовательность значений. Однако мы еще не можем говорить о разнице между значениями. Ответы на вопросы “Как часто вы курите?” по шкале “Никогда,” “Редко” и “Часто” являются примером ранговой шкалы. “Часто” — это чаще, чем “Редко,” “Редко” — это чаще чем “Никогда,” и, соотвественно, “Часто” — это чаще, чем “Никогда.” Но мы не можем сказать, что разница между “Часто” и “Редко” такая же, как и между “Редко” и “Никогда.” Соответственно, даже если мы обозначим “Часто,” “Редко” и “Никогда” как 3, 2 и 1 соответственно, то многого не можем сделать с этой шкалой, Например, мы не можем посчитать арифметическое среднее для такой шкалы.
- Шкала разностей (интервальная шкала) — шкала, для которой мы уже можем говорить про разницы между интервалами. Например, разница между 10 Cº и 20 Cº такая же как и между 80 Cº и 90 Cº. Для шкалы разностей уже можно сравнивать средние, но операции умножения и деления не имеют смысл, потому что ноль в шкале разностей относительный. Например, мы не можем сказать, что 20 Cº — это в два раза теплее, чем 10 Cº, потому что 0 Cº — это просто условно взятая точка — температура плавления льда.
- Шкала отношений (абсолютная шкала) — самая “полноценная” шкала, которая отличается от интервальной наличием естественного и однозначного начала координат. Например, масса в килограммах или та же температура, но в градусах Кельвина, а не Цельсия.
10.3 Меры центральной тенденции
Для примера мы возьмем массу супергероев, предварительно удалив из нее все NA для удобства.
weight <- heroes %>%
drop_na(Weight) %>%
pull(Weight)Мера центральной тенденции - это число для описания центра распределения.
10.3.1 Арифметическое среднее
Самая распространенная мера центральных тенденций - арифметическое среднее, то самое, которые мы считаем с помощью функции mean().
\[\overline{x}= \frac{\sum\limits_{i=1}^{n} x_{i}} {n}\]
Не пугайтесь значка \[\sum\limits_{i=1}^{n}\] - это означает сумму от i = 1 до n. Что-то вроде цикла for!
В качестве упражнения попробуйте самостоятельно превратить эту формулу в функцию mymean() c помощью sum() и length(). Можете убирать NA по дефолту! Сравните с результатом функции mean().
mean(weight)## [1] 112.252510.3.2 Медиана
Медиана - это середина распределения. Представим, что мы расставили значения по порядку (от меньшего к большему) и взяли значение по середине. Если у нас четное количество значений, то берется среднее значение между теми двумя, что по середине. Для расчета медианы есть функция median():
median(weight)## [1] 81Разница медианы со средним не очень существенная. Это значит, что распределение довольно “симметричное.” Но бывает и по-другому.
Представьте себе, что кто-то говорит про среднюю зарплату в Москве. Но ведь эта средняя зарплата становится гораздо больше, если учитывать относительно небольшое количество мультимиллионеров и миллиардеров! А вот медианная зарплата будет гораздо меньше.
Представьте себе, что в среде супергероев поялвяется кто-то, кто весит 9000 килограммов! Тогда среднее сильно изменится:
mean(c(weight, 9000))## [1] 130.1714А вот медиана останется той же.
median(c(weight, 9000))## [1] 81Таким образом, экстремально большие или маленькие значения оказывают сильное влияние на арифметическое среднее, но не на медиану. Поэтому медиана считается более “робастной” оценкой, т.е. более устойчивой к выбросам и крайним значениям.
10.3.3 Усеченное среднее (trimmed mean)
Если про среднее и медиану слышали все, то про усеченное (тримленное) среднее известно гораздо меньше. Тем не менее, на практике это довольно удобная штука, потому что представляет собой некий компромисс между арифметическим средним и медианой.
В усеченном среднем значения ранжируются так же, как и для медианы, но отбрасывается только какой-то процент крайних значений. Усеченное среднее можно посчитать с помощью обычной функции mean(), поставив нужное значение параметра trim =:
mean(weight, trim = 0.1)## [1] 89.56423trim = 0.1 означает, что мы отбросили 10% слева и 10% справа. trim может принимать значения от 0 до 0.5. Что будет, если trim = 0?
mean(weight, trim = 0)## [1] 112.2525Обычное арифметическое среднее! А если trim = 0.5?
mean(weight, trim = 0.5)## [1] 81Медиана!
10.3.4 Мода
Мода (mode) - это самое частое значение. Обычно используется для номинальных переменных, для континуальных данных мода неприменима. Что интересно, в R нет встроенной функции для подсчета моды. Обычно она и не нужна: мы можем посчитать таблицу частот и даже проранжировать ее (и мы уже умеем это делать разными способами).
heroes %>%
count(Gender, sort = TRUE)Можете попробовать написать свою функцию для моды!
10.4 Меры рассеяния
Начинающий статистик пытался перейти в брод реку, средняя глубина которой 1 метр. И утонул.
В чем была его ошибка? Он не учитывал разброс значений глубины!
Мер центральной тенденции недостаточно, чтобы описать выборку. Необходимо знать ее вариабельность.
### Размах {range}
Самое очевидное - посчитать размах (range), то есть разницу между минимальным и максимальным значением. В R есть функция для вывода максимального и минимального значений:
range(weight)## [1] 2 900Осталось посчитать разницу между ними:
diff(range(weight))## [1] 898Естественно, крайние значения очень сильно влияют на этот размах, поэтому на практике он не очень-то используется.
10.4.1 Дисперсия
Дисперсия (variance) вычисляется по следующей формуле:
\[s^2= \frac{\sum\limits_{i=1}^{n} (x_{i} - \overline{x})^2} {n}\]
Попробуйте превратить это в функцию myvar()!
myvar <- function(x) mean((x - mean(x))^2)Естественно, в R уже есть готовая функция var(). Но, заметьте, ее результат немного отличается от нашего:
myvar(weight)## [1] 10825.55var(weight)## [1] 10847.46Дело в том, что встроенная функция var() делит не на \(n\), а на \(n-1\). Это связано с тем, что эта функция пытается оценить дисперсию в генеральной совокупности, т.е. относится уже к статистике вывода. Про это мы будем говорить в дальнейших занятиях, сейчас нам нужно только отметить то, что здесь есть небольшое различие.
10.4.2 Стандартное отклонение
Если вы заметили, значение дисперсии очень большое. Чтобы вернуться к единицам измерения, соответствующих нашим данным используется корень из дисперсии, то есть стандартное отклонение (standard deviation):
\[s= \sqrt\frac{\sum\limits_{i=1}^{n} (x_{i} - \overline{x})^2} {n}\]
Для этого есть функция sd():
sd(weight)## [1] 104.1511Что то же самое, что и:
sqrt(var(weight))## [1] 104.151110.4.3 Медианное абсолютное отклонение
Поскольку стандартное отклонение не устойчиво к выбросам, то иногда используют его альтернативу, которая устойчива к выбросам (особенно если эти выбросы нам как раз и нужно удалить) - медианное абсолютное отклонение (median absolute deviation):
\[mad= median(|x_{i} - median(x)|)\]
Для этого есть функция mad():
mad(weight)## [1] 32.617210.4.4 Межквартильный размах
Другой вариант рабостной оценки вариабельности данных является межквартильный размах (interquartile range, IQR). Это разница между третьим и первым квартилем28 - значением, которое больше 75% значений в выборке, и значением, которое больше 25% значений в выборке.
IQR(weight)## [1] 47Ну а второй квартиль - это медиана!
10.5 Ассиметрия и эксцесс
10.5.1 Ассиметрия
Ассиметрия (skewness) измеряет симметричность распределения. Положительный показатель ассиметрии (“Right-skewed” или positive skewness) означает, что хвосты с правой части распределения длиннее. Негативный показатель ассиметрии (“Left-skewed” или negative skewness) означает, что левый хвост длиннее.
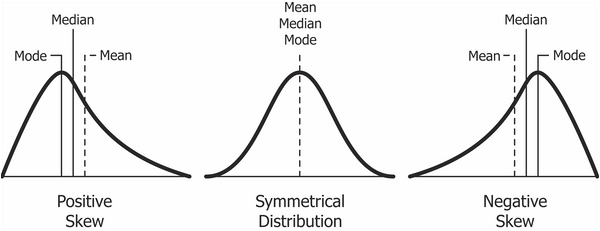
Например, в психологии положительная ассиметрия встречается очень часто. Например, время реакции: оно ограничено снизу 0 мс (а по факту не меньше 100 мс - быстрее сигнал не успеет по нервной системе пройти до пальцев), а вот с другой стороны оно никак не ограничено. Испытуемый может на полчаса перед монитором затупить, ага.
10.5.2 Эксцесс
Эксцесс (kurtosis) - это мера “вытянутости” распределения:
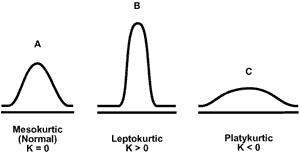
Положительные показатели эксцесса означают “вытянутое” распределение, а отрицательные - “плоское.”
10.5.3 Ассиметрия и эксцесс в R
К сожалению, в базовом R нет функций для ассиметрии и эксцесса. Зато есть замечательный пакет psych (да-да, специально для психологов).
install.packages("psych")library("psych")##
## Присоединяю пакет: 'psych'## Следующие объекты скрыты от 'package:ggplot2':
##
## %+%, alphaВ нем есть функции skew() и kurtosi():
skew(weight)## [1] 3.874557kurtosi(weight)## [1] 19.45699Ассиметрия положительная, это значит что распределение выборки асимметричное, хвосты с правой части длиннее. Эксцесс значительно выше нуля - значит распределение довольно “вытянутое.”
10.6 А теперь все вместе!
В базовом R есть функция summary(), которая позволяет получить сразу неплохой набор описательных статистик.
summary(weight)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 2.0 61.0 81.0 112.3 108.0 900.0Функция
summary()- это универсальная (generic) функция. Это означает, что Вы можете ее применять для разных объектов и получать разные результаты. Попробуйте применить ее к векторам с разными типами данных и даже к дата.фреймам и дата.тейблам. Посмотрите, что получится.
В пакете psych есть еще и замечательная функция describe(), которая даст Вам еще больше статистик, включая ассиметрию и куртозис:
psych::describe(weight)Даже усеченное (trimmed) среднее есть (с trim = 0.1)! Все кроме se мы уже знаем. А про этот se узнаем немного позже.
Эта функция хорошо работает в сочетании с group_by():
heroes %>%
group_by(Gender) %>%
summarise(describe(Weight))Другой интересный пакет для получения описательных статистик для всего датафрейма — skimr.
install.packages("skimr")Его основная функция — skim(), выводит симпатичную сводную таблицу для датафрейма.
skimr::skim(heroes)| Name | heroes |
| Number of rows | 734 |
| Number of columns | 11 |
| _______________________ | |
| Column type frequency: | |
| character | 8 |
| numeric | 3 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| name | 0 | 1.00 | 1 | 25 | 0 | 715 | 0 |
| Gender | 29 | 0.96 | 4 | 6 | 0 | 2 | 0 |
| Eye color | 172 | 0.77 | 3 | 23 | 0 | 22 | 0 |
| Race | 304 | 0.59 | 5 | 18 | 0 | 61 | 0 |
| Hair color | 172 | 0.77 | 3 | 16 | 0 | 29 | 0 |
| Publisher | 0 | 1.00 | 0 | 17 | 15 | 25 | 0 |
| Skin color | 662 | 0.10 | 3 | 14 | 0 | 16 | 0 |
| Alignment | 7 | 0.99 | 3 | 7 | 0 | 3 | 0 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| X1 | 0 | 1.00 | 366.50 | 212.03 | 0.0 | 183.25 | 366.5 | 549.75 | 733 | ▇▇▇▇▇ |
| Height | 217 | 0.70 | 186.73 | 59.25 | 15.2 | 173.00 | 183.0 | 191.00 | 975 | ▇▁▁▁▁ |
| Weight | 239 | 0.67 | 112.25 | 104.15 | 2.0 | 61.00 | 81.0 | 108.00 | 900 | ▇▁▁▁▁ |
Здесь количество и доля пропущенных значений, среднее, стандартное отклонение, минимальное и максимальное значение (p0 и p100 соответственно), квартили. Ну и вишенкой на торте выступает маленькая гистограмма для каждой колонки!
Кроме того, skimr адаптирован под tidyverse. В нем можно выбирать колонки с помощью tidyselect (8.10.2) прямо внутри функции skim().
heroes %>%
skimr::skim(ends_with("color"))| Name | Piped data |
| Number of rows | 734 |
| Number of columns | 11 |
| _______________________ | |
| Column type frequency: | |
| character | 3 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| Eye color | 172 | 0.77 | 3 | 23 | 0 | 22 | 0 |
| Hair color | 172 | 0.77 | 3 | 16 | 0 | 29 | 0 |
| Skin color | 662 | 0.10 | 3 | 14 | 0 | 16 | 0 |
А еще можно сочетать с группировкой с помощью group_by().
heroes %>%
group_by(Gender) %>%
skimr::skim(ends_with("color"))| Name | Piped data |
| Number of rows | 734 |
| Number of columns | 11 |
| _______________________ | |
| Column type frequency: | |
| character | 3 |
| ________________________ | |
| Group variables | Gender |
Variable type: character
| skim_variable | Gender | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|---|
| Eye color | Female | 41 | 0.80 | 3 | 23 | 0 | 14 | 0 |
| Eye color | Male | 121 | 0.76 | 3 | 12 | 0 | 18 | 0 |
| Eye color | NA | 10 | 0.66 | 3 | 23 | 0 | 7 | 0 |
| Hair color | Female | 38 | 0.81 | 3 | 16 | 0 | 18 | 0 |
| Hair color | Male | 123 | 0.76 | 3 | 16 | 0 | 23 | 0 |
| Hair color | NA | 11 | 0.62 | 4 | 14 | 0 | 10 | 0 |
| Skin color | Female | 186 | 0.07 | 4 | 6 | 0 | 7 | 0 |
| Skin color | Male | 449 | 0.11 | 3 | 14 | 0 | 14 | 0 |
| Skin color | NA | 27 | 0.07 | 4 | 4 | 0 | 2 | 0 |
###Описательных статистик недостаточно {#datasaurus}
Я в тайне от Вас загрузил данные в переменную xxx (можете найти этот набор данных здесь, если интересно). Выглядят они примерно так:
head(xxx)str(xxx)## spec_tbl_df [142 × 2] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
## $ x: num [1:142] 55.4 51.5 46.2 42.8 40.8 ...
## $ y: num [1:142] 97.2 96 94.5 91.4 88.3 ...
## - attr(*, "spec")=
## .. cols(
## .. x = col_double(),
## .. y = col_double()
## .. )Надеюсь, Вы уже понимаете, как это интерпретировать - два столбца с 142 числами каждый. Представьте себе, как выглядят эти точки на плоскости, если каждая строчка означают координаты одной точки по осям x и y (это называется диаграмма рассеяния, точечная диаграмма или scatterplot).
Применим разные функции, которые мы выучили:
mean(xxx$x)## [1] 54.26327mean(xxx$y)## [1] 47.83225median(xxx$x)## [1] 53.3333median(xxx$y)## [1] 46.0256Средние и медианы примерно одинаковые, при этом по х они около 53-54, а по у - примерно 46-47. Попытайтесь представить это. Идем дальше:
sd(xxx$x)## [1] 16.76514sd(xxx$y)## [1] 26.9354Похоже, разброс по у несколько больше, верно?
skew(xxx$x)## [1] 0.2807568skew(xxx$y)## [1] 0.2472603kurtosi(xxx$x)## [1] -0.2854912kurtosi(xxx$y)## [1] -1.063552Похоже, оба распределения немного право-ассиметричны и довольно “плоские.”
Давайте еще посчитаем коэффициент корреляции (correlation coefficient). Мы про него будем говорить позже гораздо подробнее. Пока что нам нужно знать, что она говорит о линейной связи двух переменных. Если коэффициент корреляции положительный (максимум равен 1), то чем больше х, тем больше у. Если отрицательный (минимум равен -1), то чем больше х, тем меньше у. Если же коэффициент корреляции равна нулю, то такая линейная зависимость отсутствует.
cor(xxx$x, xxx$y)## [1] -0.06447185Коэффициент корреляции очень близка к нулю (делайте выводы и представляйте).
Давайте напоследок воспользуемся функцией describe() из psych:
psych::describe(xxx)skimr::skim(xxx)| Name | xxx |
| Number of rows | 142 |
| Number of columns | 2 |
| _______________________ | |
| Column type frequency: | |
| numeric | 2 |
| ________________________ | |
| Group variables | None |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| x | 0 | 1 | 54.26 | 16.77 | 22.31 | 44.10 | 53.33 | 64.74 | 98.21 | ▅▇▇▅▂ |
| y | 0 | 1 | 47.83 | 26.94 | 2.95 | 25.29 | 46.03 | 68.53 | 99.49 | ▇▇▇▅▆ |
Готовы узнать, как выглядят эти данные на самом деле?!
Жмите сюда если готовы!
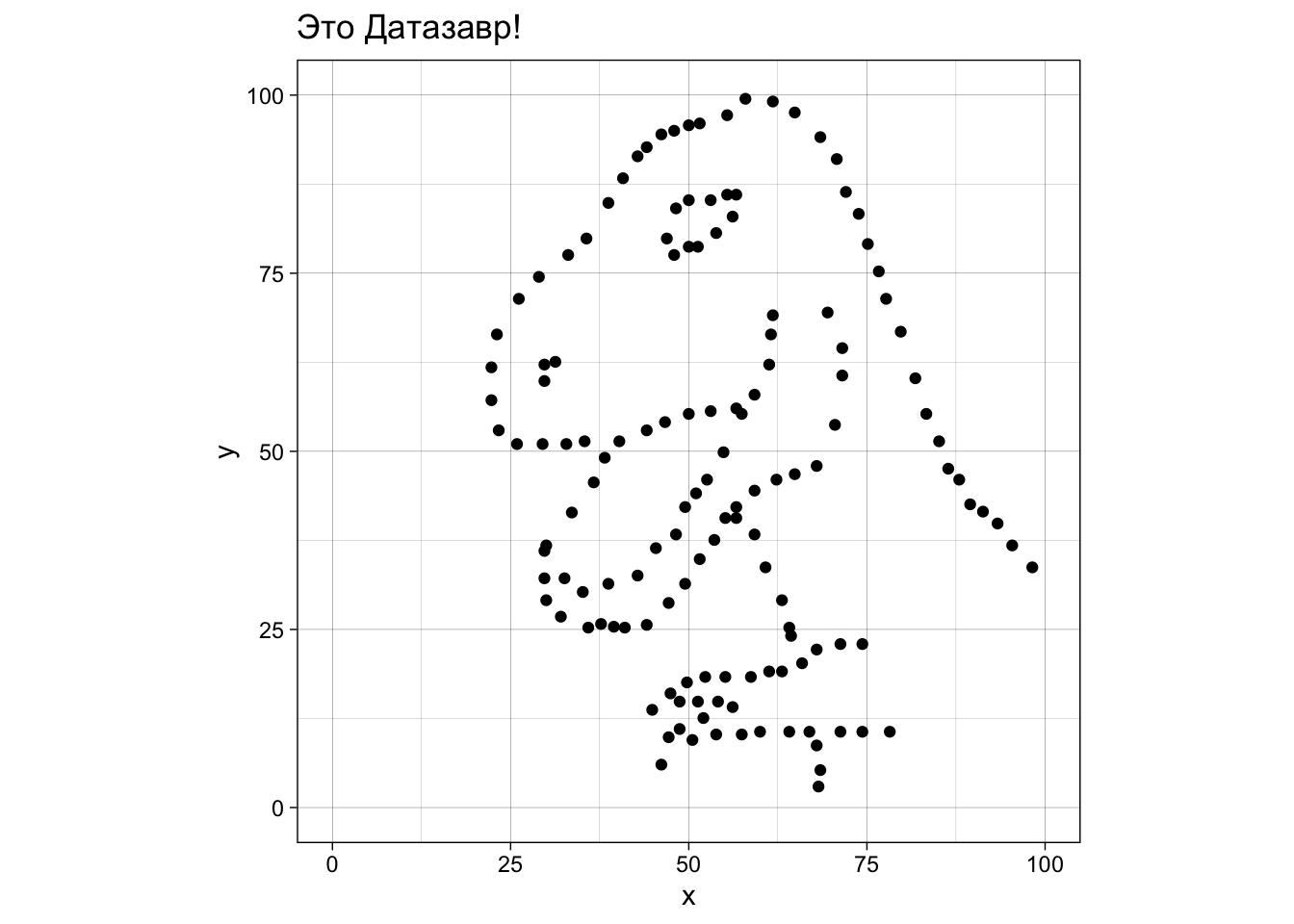
Из этого можно сделать важный вывод: не стоит слепо доверять описательным статистикам. Нужно визуализировать данные, иначе можно попасть в такую ситуацию в реальности. По словам знаменитого статитстика Джона Тьюки, величайшая ценность картинки в том, что она заставляет нас заметить то, что мы не ожидали заметить. Поэтому графики — это не просто метод коммуникации — представления ваших результатов сообществу в понятном виде (хотя и это, конечно, тоже), но и сам по себе очень важный метод анализа данных.
#Визуализация в R {#r_vis} ## Базовые функции для графики {#base_vis}
В R есть достаточно мощный встроенный инструмент для визуализации. Я приведу три простых примера. Во-первых, это та самая диаграмма рассеяния. Здесь все просто: функция plot(), вектора x и у, дополнительные параметры для цвета, размера, формы точек.
Для примера возьмем датасет heroes с Height по оси x и Weight по оси y.
plot(heroes$Height, heroes$Weight)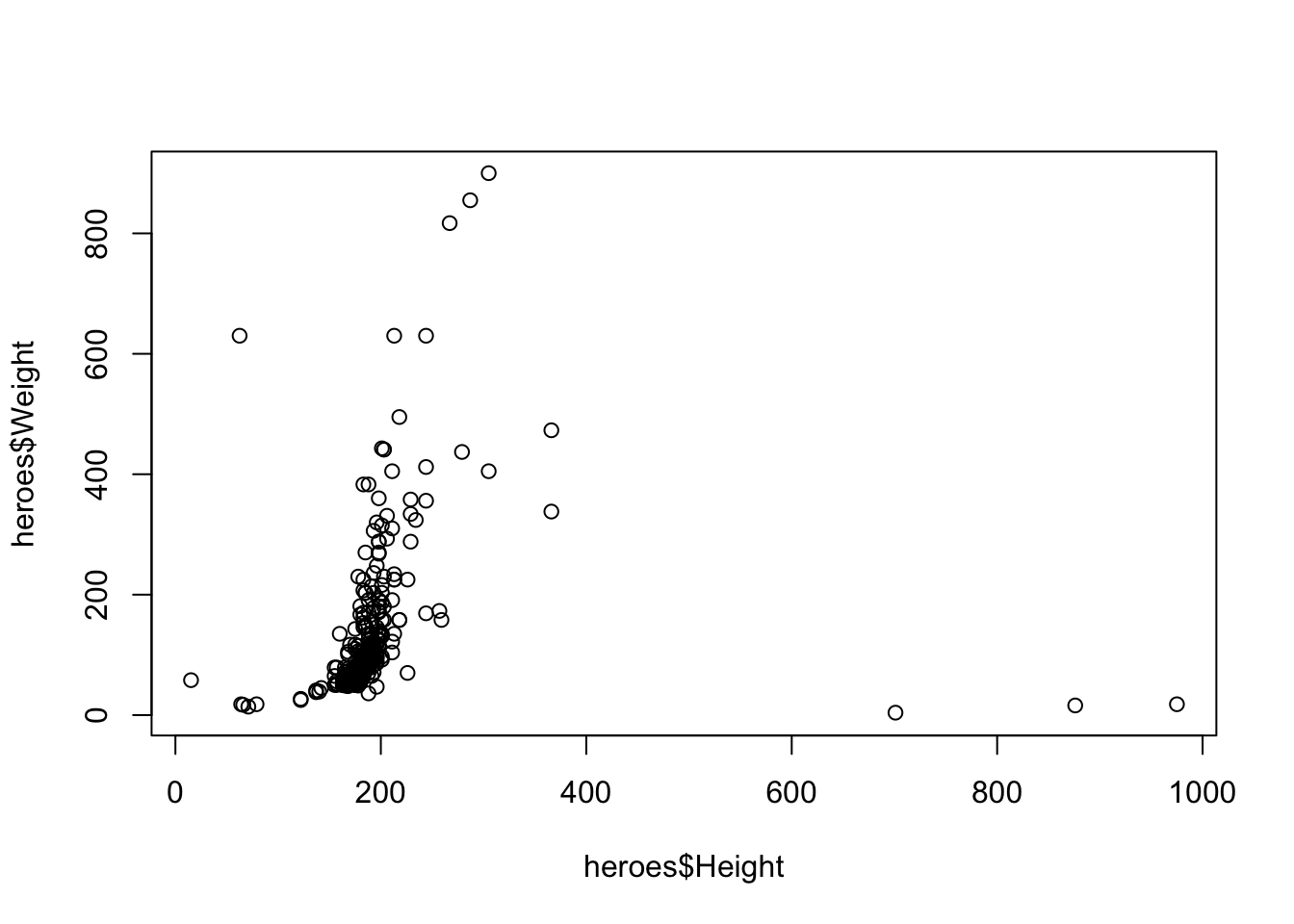
Между прочим, функция
plot()- это тоже универсальная (generic) функция, как иsummary(). В качестве аргумента можете ей скормить просто один вектор, матрицу, датафрейм. Более того, многие пакеты добавляют новые методы plot() для новых объектов из этих пакетов.
Другая распространенная функция — hist() — гистограмма (histogram):
hist(weight)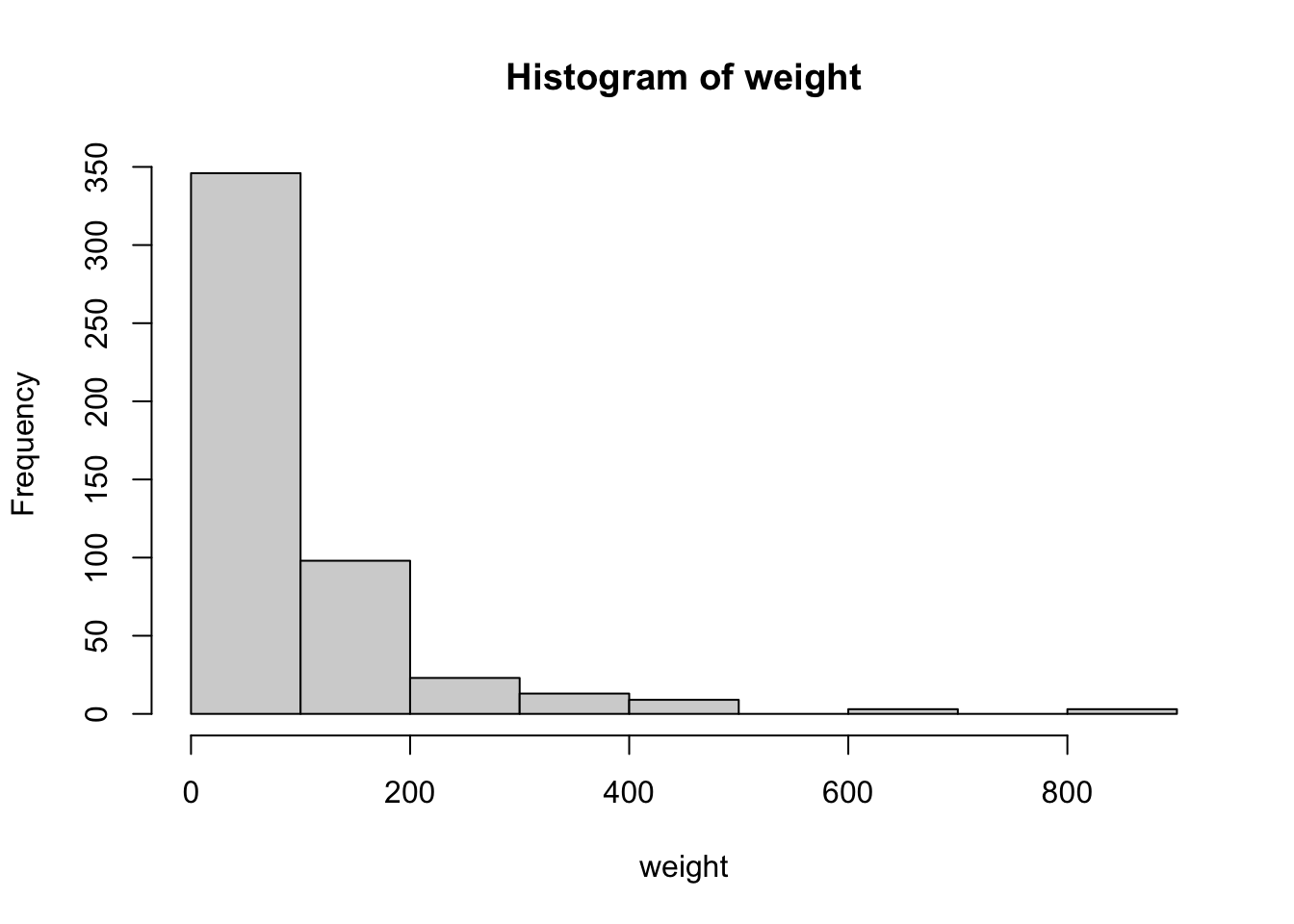
Ну и закончим на суперзвезде прошлого века под названием ящик с усами (boxplot with whiskers):
boxplot(Weight ~ Gender, heroes)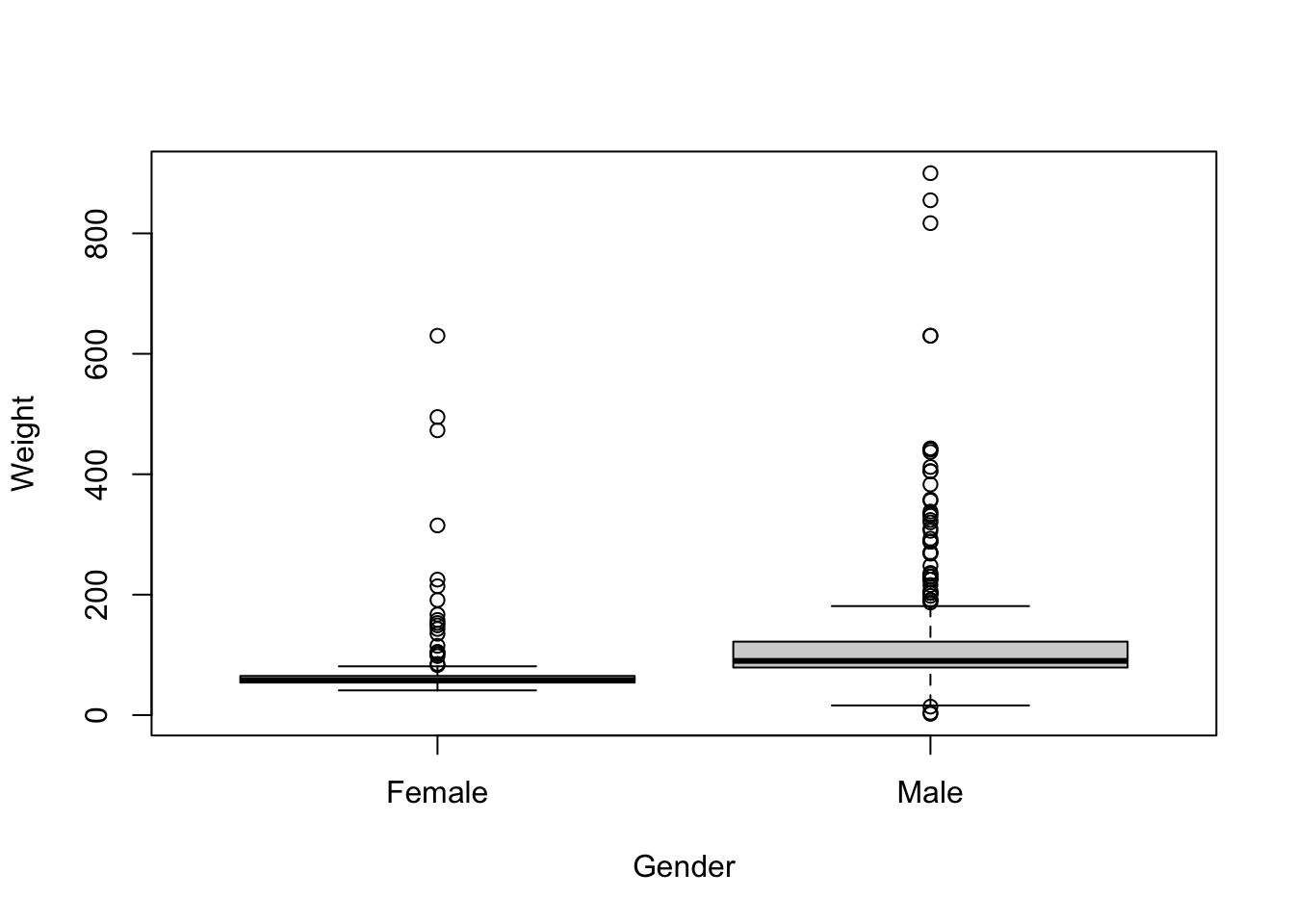
Здесь мы использовали уже знакомый нам класс формул. Они еще будут нам встречаться дальше, обычно они используются следующим образом: слева от ~ находится зависимая переменная, а справа - “предикторы.” Эта интуиция работает и здесь: мы хотим посмотреть, как различается вес в зависимости от пола.
10.7 История грамматики графики
Встроенные возможности для визуализации в R довольно обширны, но дополнительные пакеты значительно ее расширяют. Среди этих пакетов, есть один, который занимает совершенно особенное место – ggplot2.
ggplot2 — это не просто пакет, который рисует красивые графики. Красивые графики можно рисовать и в базовом R. Чтобы понять, почему пакет ggplot2 занимает особенное место среди пакетов для визуализации (и не только среди пакетов для R, а вообще!), нужно расшифровать gg в его названии. gg означает грамматику графики (Grammar of Graphics), язык для описания графиков, изложенный в одноименной книге Леланда Уилкинсона (Wilkinson 2005).
Грамматика графики позволяет описывать графики не в терминах типологии (вот есть пайчарт, есть барплот, есть гистограмма, а есть ящик с усами), а с помощью специального разработанного языка. Этот язык позволяет с помощью грамматики и небольшого количества “слов” языка описывать и создавать практически любые графики и даже придумывать новые! Это дает огромную свободу в создании именно той визуализации, что необходима для текущей задачи.
Хэдли Уикхэм (да, снова он) немного дополнил идею грамматики графики в статье “A Layered grammar of graphics” (Wickham 2010), которую сопроводил пакетом ggplot2 с реализацией идей Уилкинсона и своих.
10.8 Основы грамматики графики
Каждый график состоит из одного или нескольких слоев (layers). Если слоев несколько, то они располагаются один над другим, при этом верхние слои “перекрывают” нижние, примерно как это происходит в программах вроде Adobe Photoshop. У каждого слоя есть три обязательных элемента: данные (data), геом (geom), эстетики (aestetics); и два вспомогательных: статистические трансформации (stat). и регулировка положения (position adjustment).
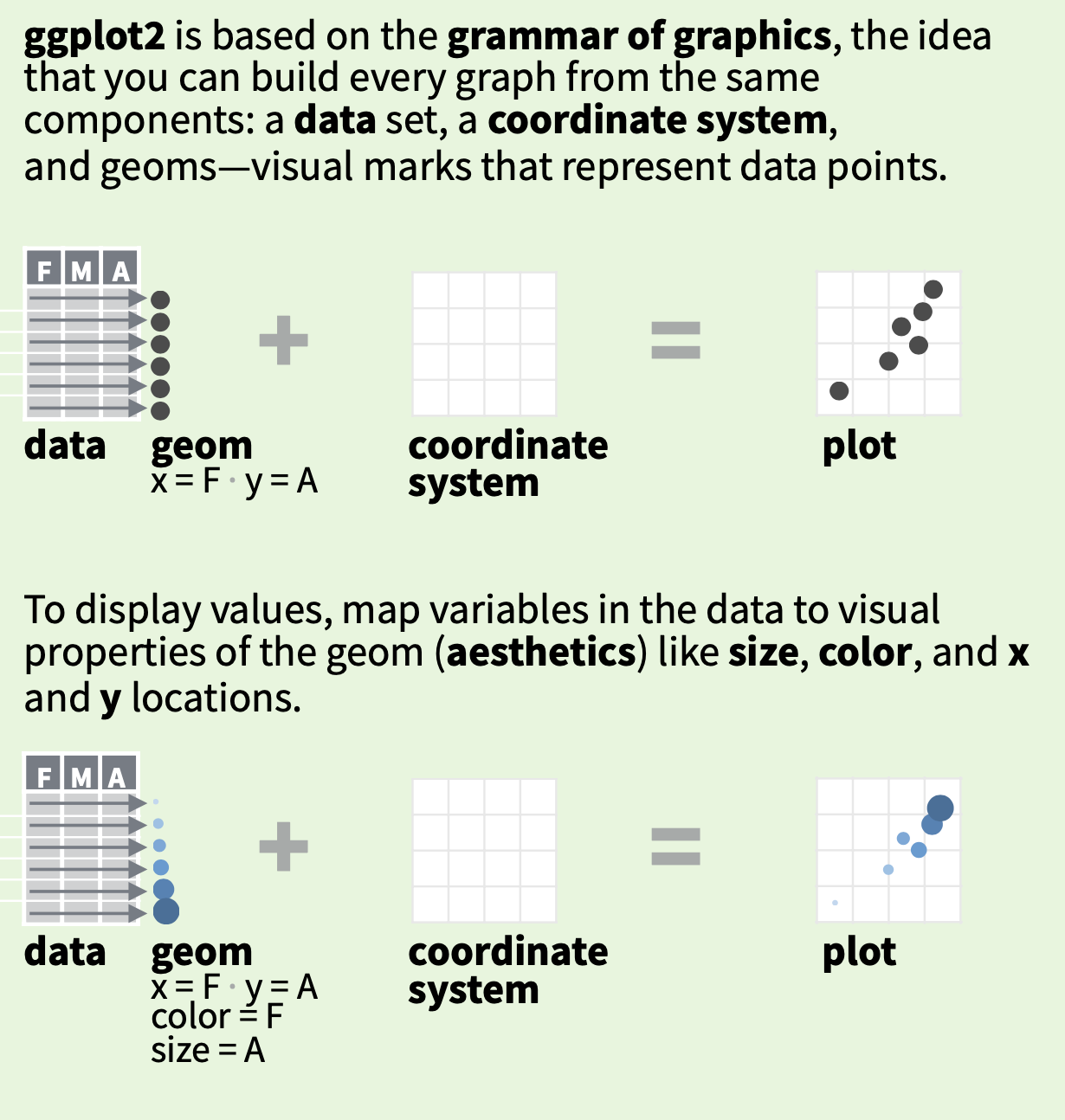
Данные (data). Собственно, сами данные в виде датафрейма, используемые в данном слое.
Геом (geom). Геом — это сокращение от “геометрический объект.” Собственно, в какой геометрический объект мы собираемся превращать данные. Например, в точки, прямоугольники или линии.
Отображение (mapping). Эстетические отображения или просто эстетики (aestetics) — это набор правил, как различные переменные превращаются в визуальные особенности геометрии. Без эстетик остается непонятно, какие именно колонки в используемом датафрейме превращаются в различные особенности геомов: позицию, размер, цвет и т.д. У каждой геометрии свой набор эстетик, но многие из них совпадают у разных геомов, например, x, y, colour, fill, size. Без некоторых эстетик геом не будет работать. Например, геометрия в виде точек не будет работать без двух координат этих точек (x и y). Другие эстетики необязательны и имеют значения по умолчанию. Например, по умолчанию точки будут черными, но можно сделать их цвет зависимым от выбранной колонки в датафрейме с помощью эстетики colour.
Статистические трансформации (stat). Название используемой статистической трансформации (или просто — статистики). Да, статистические трансформации можно делать прямо внутри
ggplot2! Это дает дополнительную свободу в выборе инструментов, потому что обычно те же статистические трансформации можно сделать внеggplot2в процессе препроцессинга. Формально, статистические трансформации — это обязательный элемент геома, но если вы не хотите преобразовывать данные, то можете выбрать “identity” преобразование, которое оставляет все как есть. Вggplot2у каждого геома есть статистика по умолчанию, а у каждой статистики - свой геом по умолчанию. И не всегда статистика по умолчанию — это “identity” статистика. Например, для барплота (geom_barplot()) используется статистика “count,”29 которая считает частоты, ведь именно частоты затем трансформируются в высоту барплотов.
- Регулировка положения (position adjustment). Регуляровка положения — это небольшое улучшение позиции геометрий для части элементов. Например, можно добавить немного случайного шума (“jitter”) в позицию точек, чтобы они не перекрывали друг друга. Или “раздвинуть” (“dodge”) два барплота, чтобы один не загораживал другой. Как и в случае со статистическими трансформациями, в большинстве случаев значение по умолчанию — “identity.”
Кроме слоев, у графика есть:
- Координатная система (coord). Если мы задали координаты, то нам нужно задать и координатную плоскость, верно? Конечно, в большинстве случаев используется декартова система координат (Cartesian coordinate system),30 т.е. стандартная прямоугольная система координат, но можно использовать и другие, например, полярную систему координат или картографическую проекцию.
Шкалы (scales). Шкалы задают то, как именно значения превращаются в эстетики. Например, если мы задали, что разные значения в колонке будут влиять на цвет точки, то какая именно палитра будет использоваться? В какие конкретно цвета будут превращаться числовые, логические или строковые значения в колонке? В
ggplot2есть правила по умолчанию для всех эстестик, и они отличные, но самостоятельная настройка шкал может значительно улучшить график.Фасетки (facets). Фасетки — это одно из нововведений Уикхэма в грамматику графики. Фасетки повзоляют разбить график на множество похожих, задав переменную, по которой график будет разделен. Это очень напоминает использование группировки с помощью
group_by().Тема (theme). Тема — это зрительное оформление “подложки” графика, не относящийся к содержанию графика: размер шрифта, цвет фона, размер и цвет линий на фоне и т.д. и т.п. В
ggplot2есть несколько встроенных тем, а также есть множество пакетов, которые добавляют дополнительные темы. Кроме того, их можно настраивать самостоятельно!Значения по умолчанию (defaults). Если в графике используется несколько слоев, то часто все они используют одни и те же данные и эстетики. Можно задать данные и эстетики по умолчанию для всего графика, чтобы не повторять код.
10.9 Пример №0: пайчарт с распределение по полу
Сейчас мы попробуем сделать простой пример в ggplot2, похожий на пример, который использует в своей книге Леланд Уилкинсон, чтобы показать мощь грамматики графики (Wilkinson 2005). Приготовьтесь, этот пример перевернет ваши представления о графиках!
Но сначала взглянем на структуру кода в ggplot().
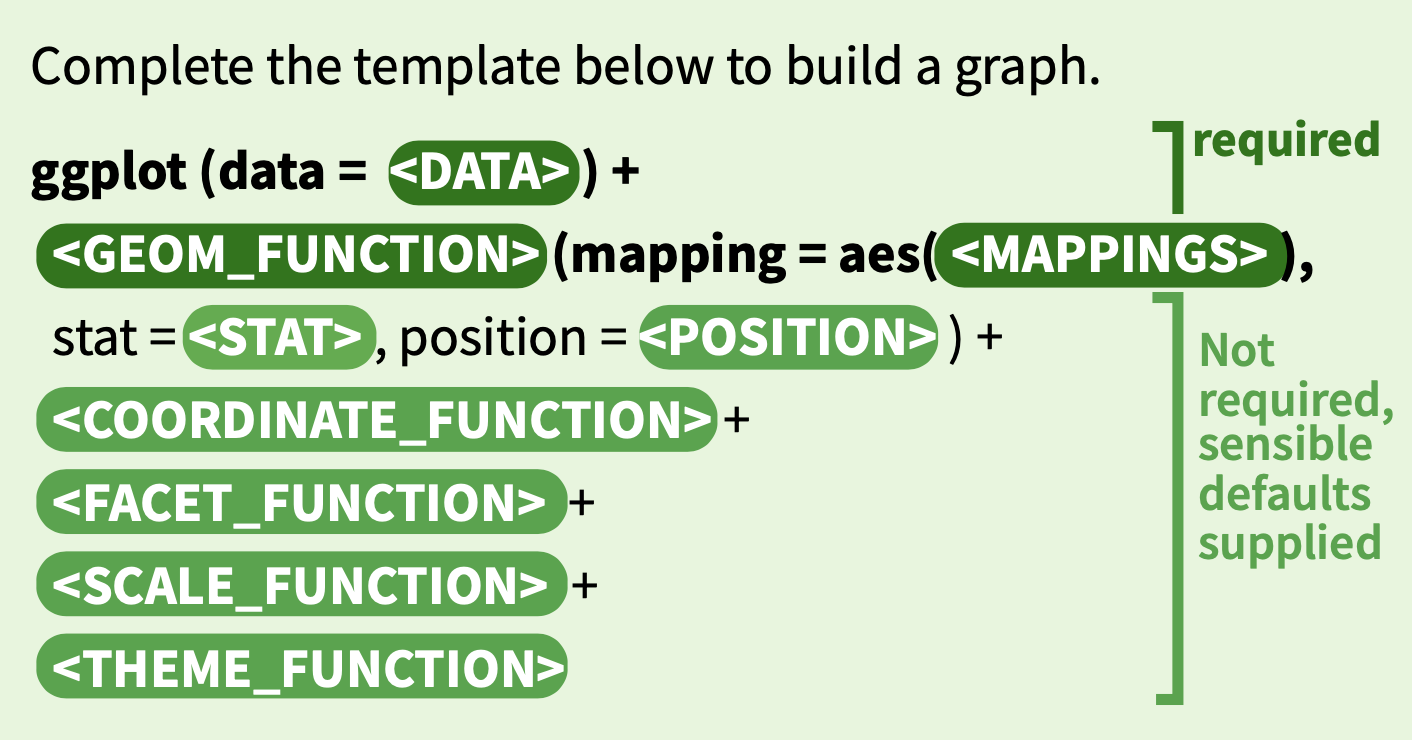
Как видно, код чем-то напоминает стандартный код tidyverse, но с + вместо пайпов. Когда был написан ggplot2, Хэдли Уикхэм еще не знал про %>% из magrittr, хотя по смыслу + означает примерно то же самое.
library(tidyverse)
heroes <- read_csv("data/heroes_information.csv",
na = c("-", "-99"))## Warning: Missing column names filled in: 'X1' [1]##
## ── Column specification ────────────────────────────────────────────────────────
## cols(
## X1 = col_double(),
## name = col_character(),
## Gender = col_character(),
## `Eye color` = col_character(),
## Race = col_character(),
## `Hair color` = col_character(),
## Height = col_double(),
## Publisher = col_character(),
## `Skin color` = col_character(),
## Alignment = col_character(),
## Weight = col_double()
## )Итак, запустим функцию ggplot(), задав наш тиббл heroes в качестве данных.
ggplot(data = heroes)
Мы ничего не получили! Это естественно, ведь мы задали только данные по умолчанию, но не задали геометрию и эстетики.
Функция ggplot() не просто отрисовывает график, эта функция создает объект класса ggplot, который можно сохранить и модифицировать в дальнейшем:
almost_empty_ggplot <- ggplot(data = heroes)
almost_empty_ggplot
Возьмем geom_bar() для отрисовки барплота. В качестве эстетик поставим x = Gender и fill = Gender. Поскольку это эстетики, они обозначаются внутри функции параметра mapping = aes() или просто внутри функции aes(). По умолчанию, geom_bar() имеет статистику “count,” что нас полностью устраивает: geom_bar() сам посчитает табличу частот и использует значения Gender для обозначения позиций и заливки, а посчитанные частоты будет использовать для задания высоты столбцов.
ggplot(data = heroes) +
geom_bar(aes(x = Gender, fill = Gender))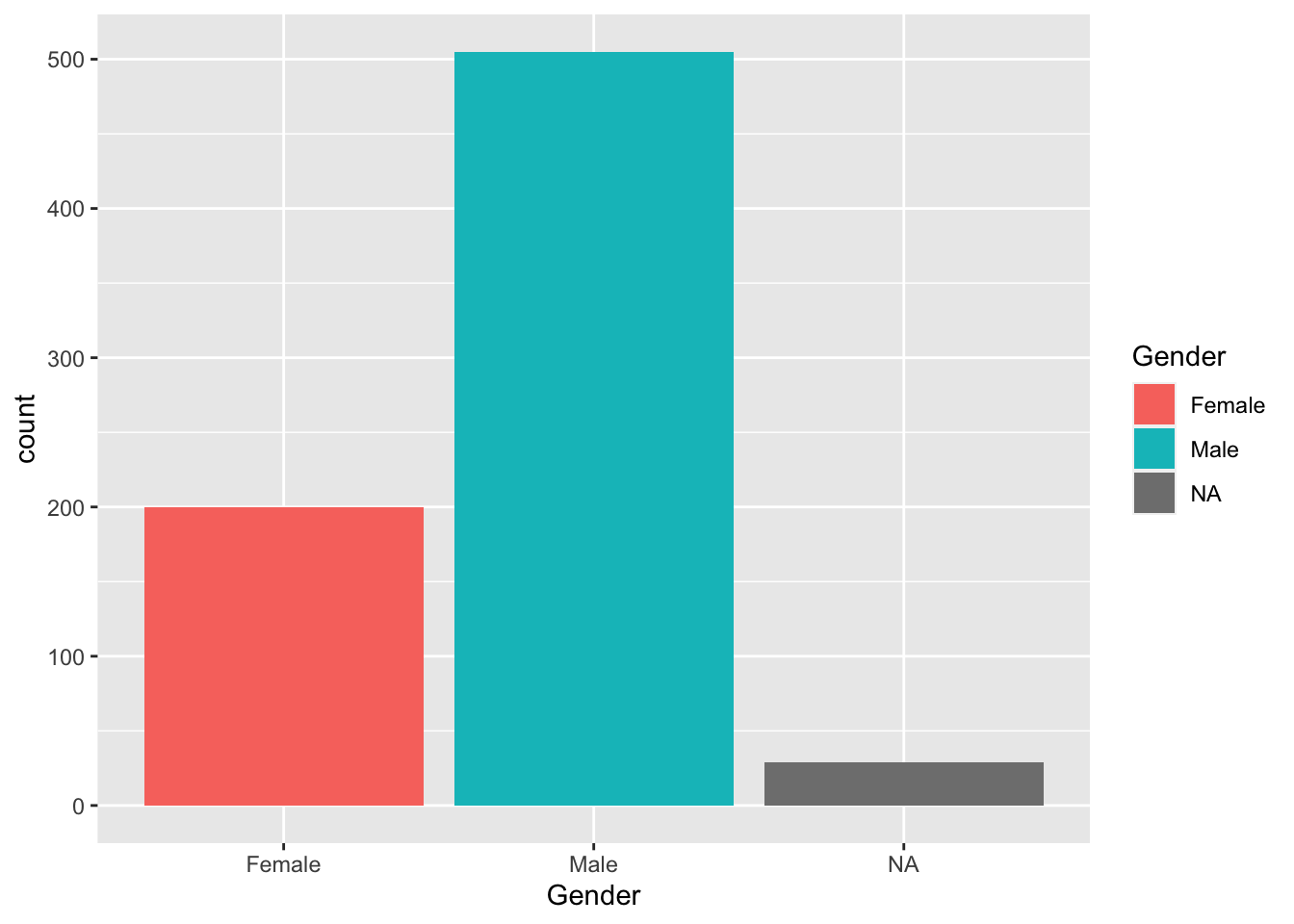
Сейчас мы сделаем один хитрый трюк: поставим значение эстетики x = "", чтобы собрать все столбики в один.
ggplot(data = heroes) +
geom_bar(aes(x = "", fill = Gender))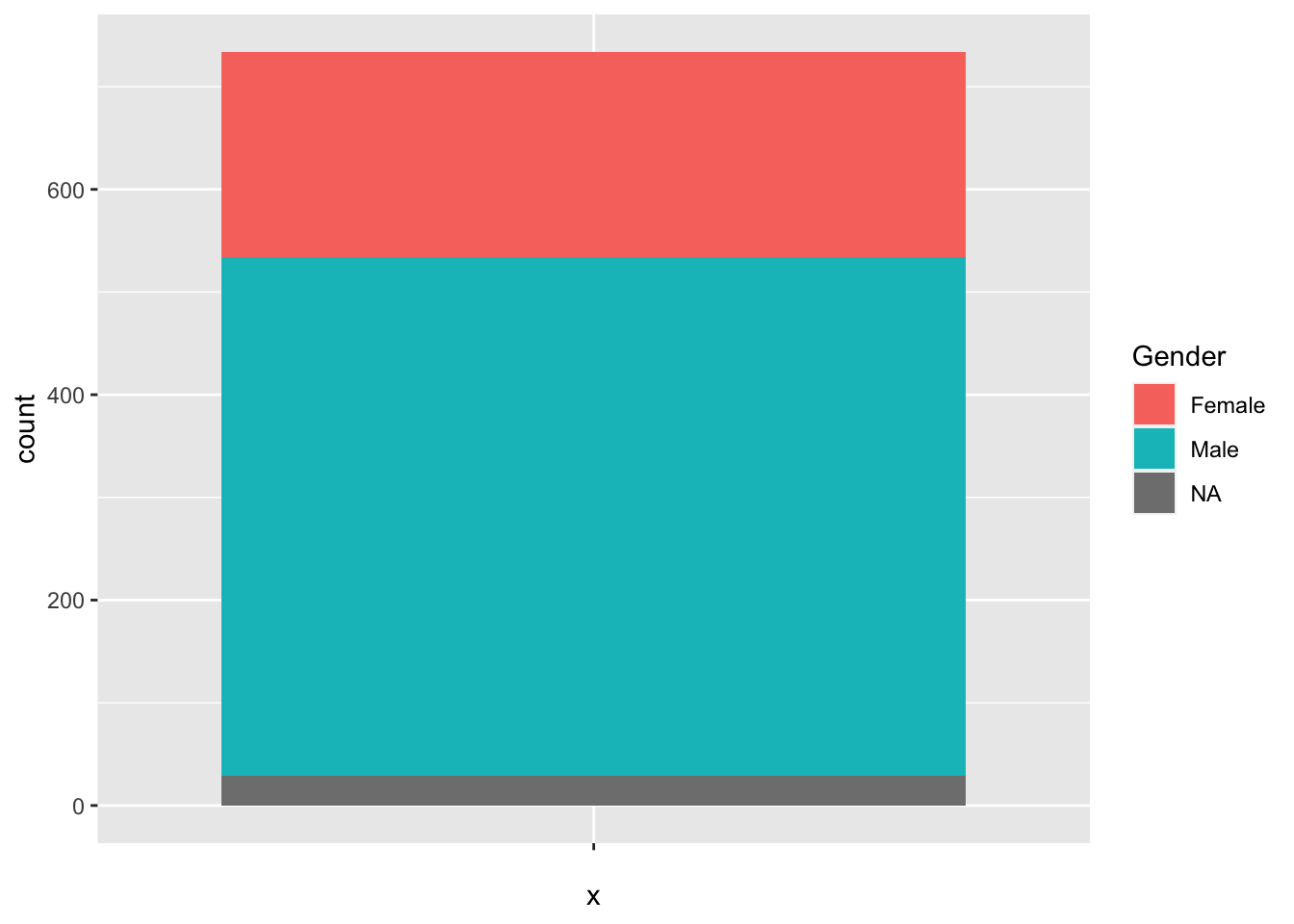
Получилось что-то не очень симпатичное, но вполне осмысленное: доли столбца обозначают относительную частоту.
Можно настроить общие параметры геома, не зависящие от данных. Это нужно делать вне функции aes(), но внутри функции для геома.
ggplot(data = heroes) +
geom_bar(aes(x = "", fill = Gender), width = .2)
Казалось бы, причем здесь Minecraft?
А теперь внимание! Подумайте, какого действия нам не хватает, чтобы из имеющегося графика получить пайчарт?
ggplot(data = heroes) +
geom_bar(aes(x = "", fill = Gender)) +
coord_polar(theta = "y")
Нам нужно было всего-лишь поменять систему координат с декартовой на полярную (круговую)! Иначе говоря, пайчарт - это барплот в полярной системе координат.
Именно в этом основная сила грамматики графики и ее реализации в ggplot2 — вместо того, чтобы описывать и рисовать огромное количество типов графиков, можно описать практически любой график через небольшой количество элементарных элементов и правила их соединения.
Получившийся пайчарт осталось подретушировать, убрав все лишние элементы подложки с помощью самой минималистичной темы theme_void() и добавив название графика:
ggplot(data = heroes) +
geom_bar(aes(x = "", fill = Gender)) +
coord_polar(theta = "y") +
theme_void() +
labs(title = "Gender distributions for superheroes")
Это был интересный, но немного шуточный пример. Все-таки пайчарт — это довольно спорный способ визуализировать данные, вызывающий много вполне справедливой критики. Поэтому сейчас мы перейдем к гораздо более реалистичному примеру.
10.10 Пример №1: Education and IQ meta-analysis
Для этого примера мы возьмем мета-анализ связи количества лет обучения и интеллекта: “How Much Does Education Improve Intelligence? A Meta-Analysis” (Ritchie and Tucker-Drob 2018). Мета-анализ — это группа статистических методов, которые позволяют объединить результаты нескольких исследований с похожим планом исследованием и тематикой, чтобы посчитать средний эффект между несколькими статьями сразу.
Данные и скрипт для анализа данных в этой статье находятся в открытом доступе: https://osf.io/r8a24/
Полный текст статьи доступен по ссылке.
Существует положительная корреляция между количеством лет, который человек потратил на обучение, и интеллектом. Это может объясняться по-разному: как то, что обучение повышает интеллект, и как то, что люди с высоким интеллекте стремятся получать больше образования. Напрямую в эксперименте это проверить нельзя, поэтому есть несколько квази-экспериментальных планов, которые косвенно указывают на верность той или иной гипотезу. Например, если в стране изменилось количество лет обязательного школьного образования, то повлияло ли это на интеллект целого поколения? Или все-таки дело в Моргенштерне
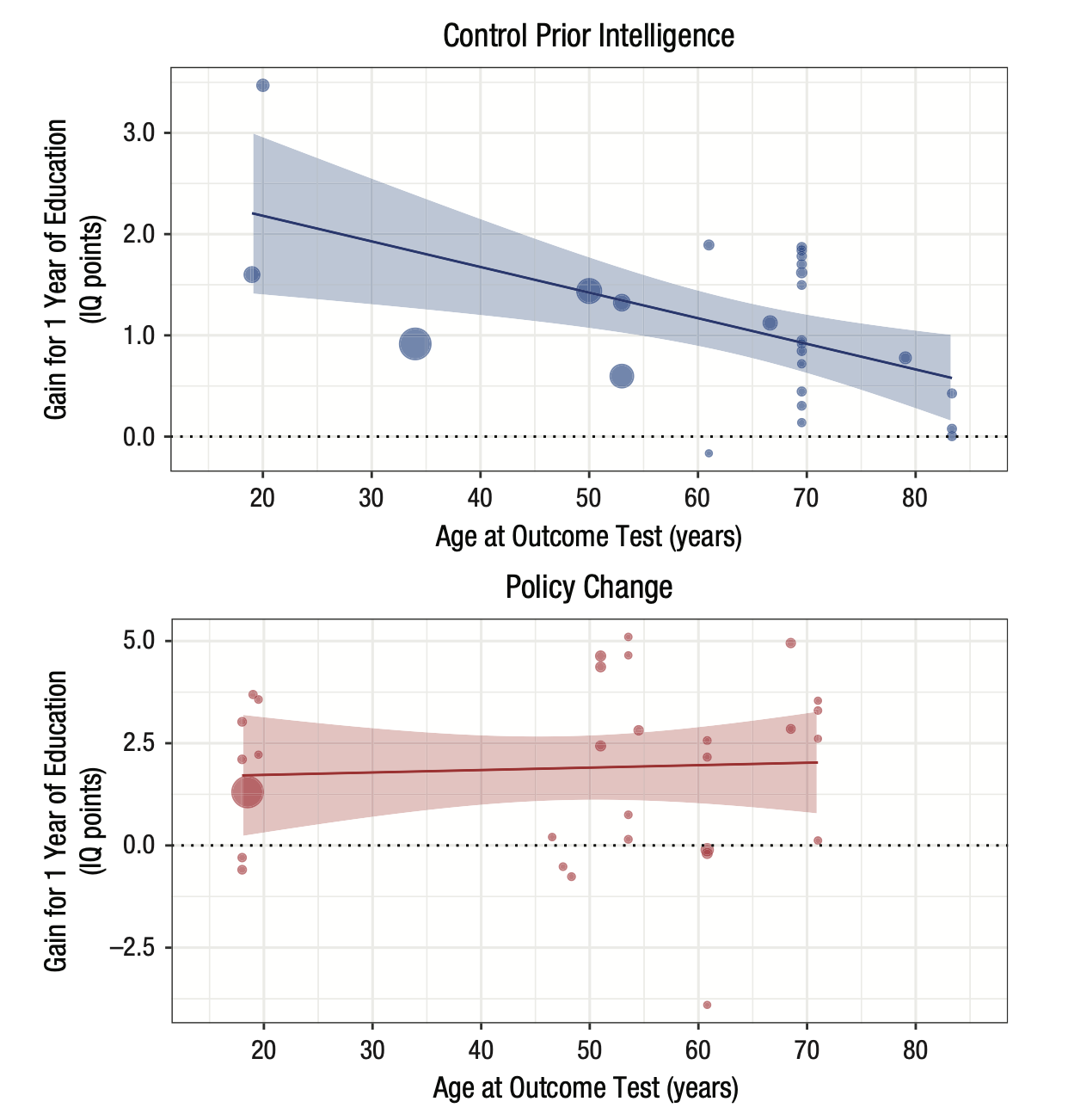
Данная картинка показывает, насколько размер эффекта (выраженный в баллах IQ) зависит от того, какой средний возраст участвоваших в исследовании испытуемых.
Каждая точка на этом графике — это отдельное исследование, положение по оси x — средний возраст респондентов, а положение по оси y - средний прирост интеллекта согласно исследованию. Размер точки отражает “точность” исследования (грубо говоря, чем больше выборка, тем больше точка). Два графика обозначают два квазиэкспериментальных плана.
Мы сфокусируемся на нижней картинке с “Policy change” — это как раз исследования, в которых изучается изменения интеллекта в возрастных группах после изменения количества лет обучения в школе.

Мы полностью воспроизведем код
library(tidyverse)Заметьте, данный датасет использует немного непривычный для нас формат хранения данных. Попытайтесь самостоятельно прочитать его.
df <- read_tsv("https://raw.githubusercontent.com/Pozdniakov/tidy_stats/master/data/meta_dataset.txt")##
## ── Column specification ────────────────────────────────────────────────────────
## cols(
## Study_ID = col_double(),
## Data_ID = col_double(),
## k = col_double(),
## Country = col_character(),
## n = col_double(),
## Design = col_character(),
## outcome_test_cat = col_double(),
## Effect_size = col_double(),
## SE = col_double(),
## Outcome_age = col_double(),
## quasi_age = col_double(),
## cpiq_early_age = col_double(),
## cpiq_age_diff = col_double(),
## ses_funnel = col_double(),
## published = col_double(),
## Male_only = col_double(),
## Achievement = col_double()
## )Давайте посмотрим, как устроен датафрейм df:
dfКаждая строчка — это результат отдельного исследования, при этом одна статья может включать несколько исследований,
В дальнейшем мы будем использовать код авторов статьи и смотреть, строчка за строчкой, как он будет работать.
cpiq <- subset(df, subset=(Design=="Control Prior IQ"))
poli <- subset(df, subset=(Design=="Policy Change"))Авторы исследования используют subset(), это функция базового R, принцип которой очень похож на filter().31
Итак, начнем рисовать сам график. Сначала иницируем объект ggplot с данными poli по умолчанию.
ggplot(data=poli) 
Теперь добавим в качестве эстетик по умолчанию координаты: aes(x=Outcome_age, y=Effect_size).
ggplot(aes(x=Outcome_age, y=Effect_size), data=poli) 
Что изменилось? Появилась координатная ось и шкалы. Заметьте, масштаб неслучаен: он строится на основе разброса значений в выбранных колонках. Однако этого недостаточно для отрисовки графика, нехватает геометрии: нужно задать, в какую географическую сущность отобразятся данные.
ggplot(aes(x=Outcome_age, y=Effect_size), data=poli) +
geom_point() 
Готово! Это и есть основа картинки. Добавляем размер:
ggplot(aes(x=Outcome_age, y=Effect_size, size=1/(SE^2)), data=poli) +
geom_point() 
Перед нами возникла проблема оверплоттинга: некоторые точки перекрывают друг друга, поскольку имеют очень близкие координат. Авторы графика решают эту проблему очевидным способом: добавляют прозрачности точкам. Заметьте, прозрачность задается для всех точек одним значением, поэтому параметр alpha задается вне функции aes().
ggplot(aes(x=Outcome_age, y=Effect_size, size=1/(SE^2)), data=poli) +
geom_point(alpha=.55) 
Совершенно так же задается и цвет. Он задается одинаковым для всех точек с помощью HEX-кода.
ggplot(aes(x=Outcome_age, y=Effect_size, size=1/(SE^2)), data=poli) +
geom_point(alpha=.55, colour="#BA1825")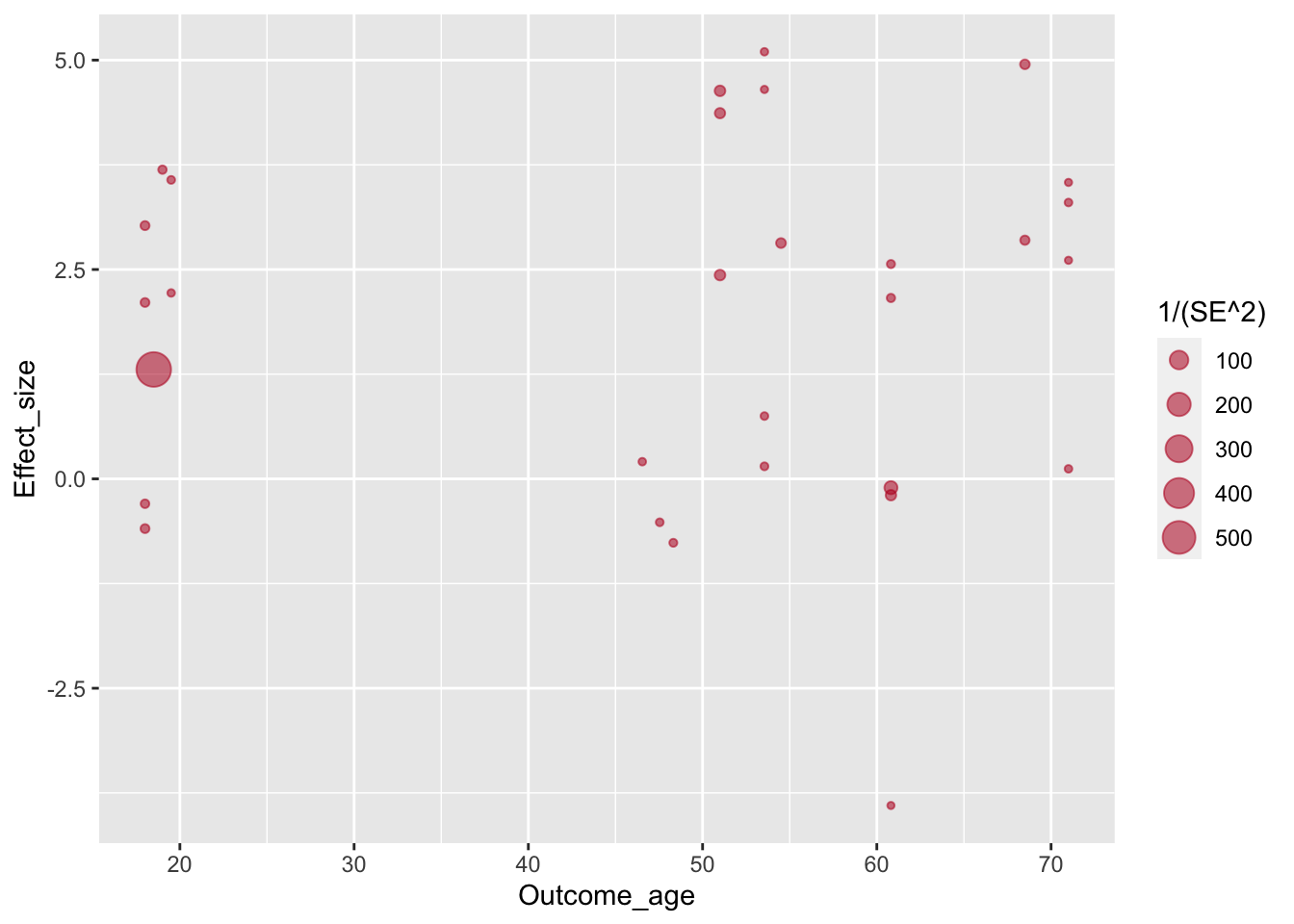
Теперь добавим регрессионную прямую с доверительными интервалами на график. Это специальный геом geom_smooth() со специальной статистикой, который займет второй слой данного графика.
ggplot(aes(x=Outcome_age, y=Effect_size, size=1/(SE^2)), data=poli) +
geom_point(alpha=.55, colour="#BA1825") +
geom_smooth()## `geom_smooth()` using method = 'loess' and formula 'y ~ x'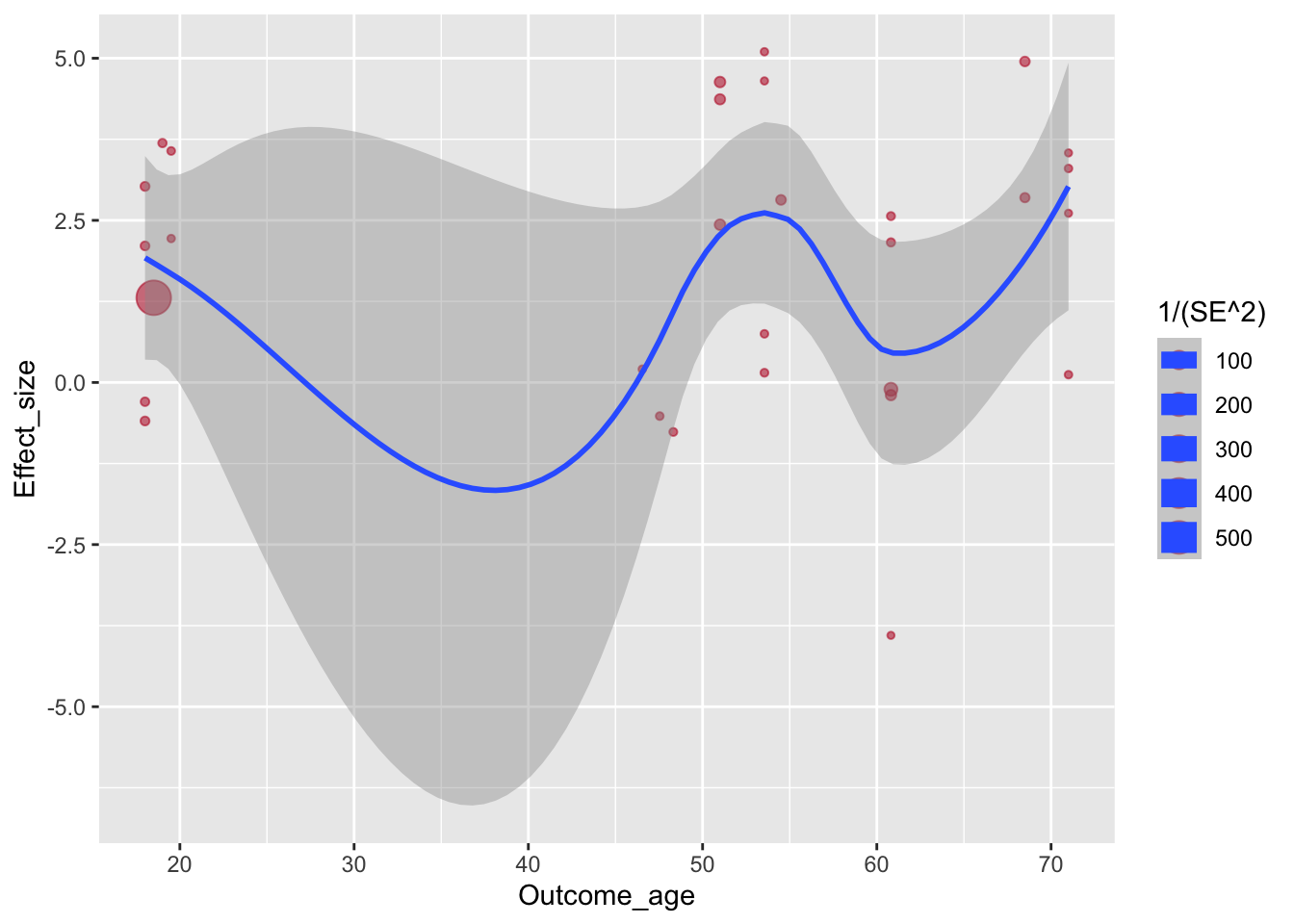
По умолчанию geom_smooth() строит кривую линию. Поставим method = "lm" для прямой.
ggplot(aes(x=Outcome_age, y=Effect_size, size=1/(SE^2)), data=poli) +
geom_point(alpha=.55, colour="#BA1825") +
geom_smooth(method="lm")## `geom_smooth()` using formula 'y ~ x'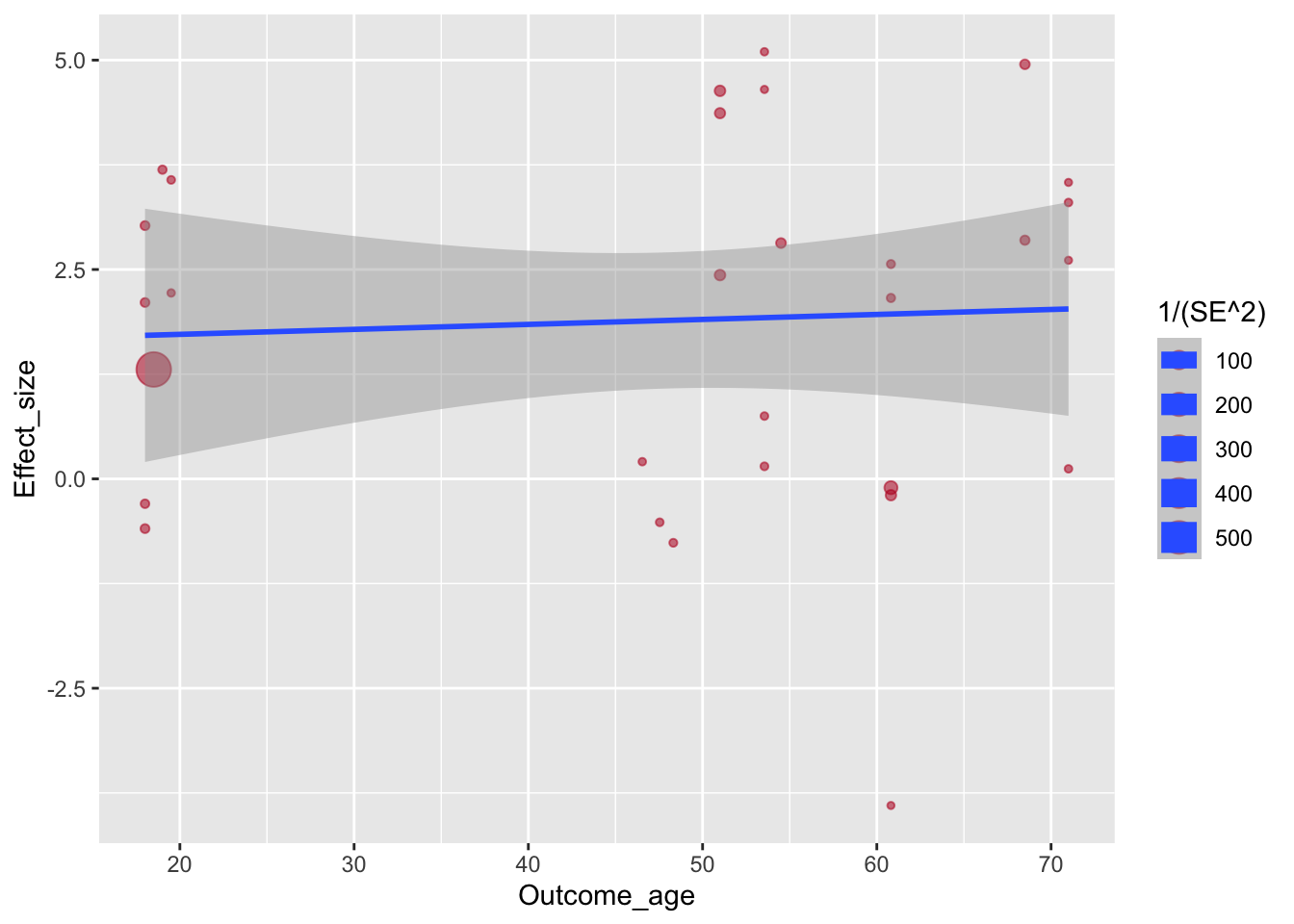
Теперь нужно поменять цвет: ярко синий цвет, используемый по умолчанию здесь попросту мешает восприятию графика.
ggplot(aes(x=Outcome_age, y=Effect_size, size=1/(SE^2)), data=poli) +
geom_point(alpha=.55, colour="#BA1825") +
geom_smooth(method="lm", colour="#BA1825")## `geom_smooth()` using formula 'y ~ x'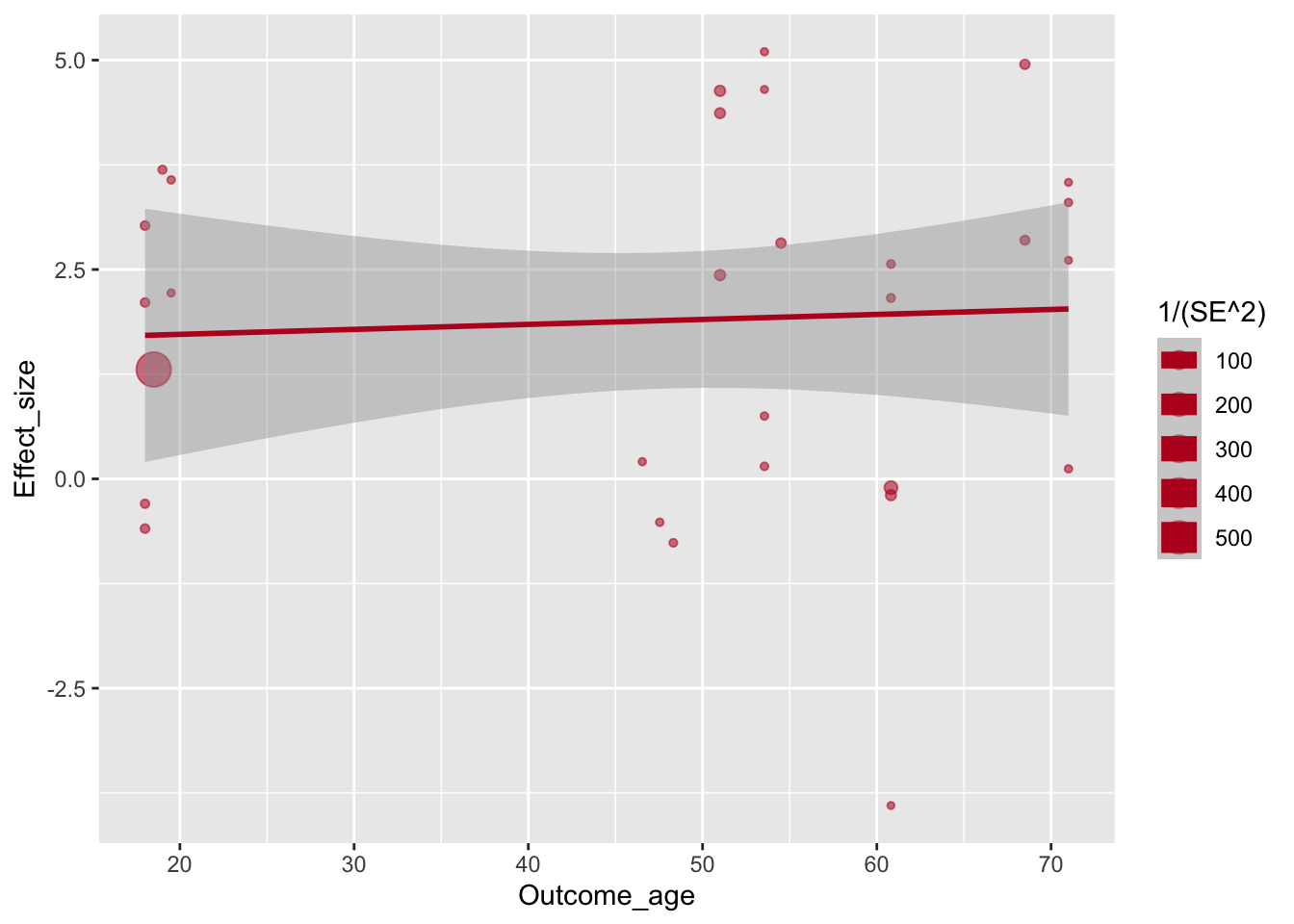
Авторы графика перекрашивают серую полупрозначную область тоже. В этом случае используется параметр fill =, а не colour =, но цвет используется тот же.
ggplot(aes(x=Outcome_age, y=Effect_size, size=1/(SE^2)), data=poli) +
geom_point(alpha=.55, colour="#BA1825") +
geom_smooth(method="lm", colour="#BA1825",fill="#BA1825")## `geom_smooth()` using formula 'y ~ x'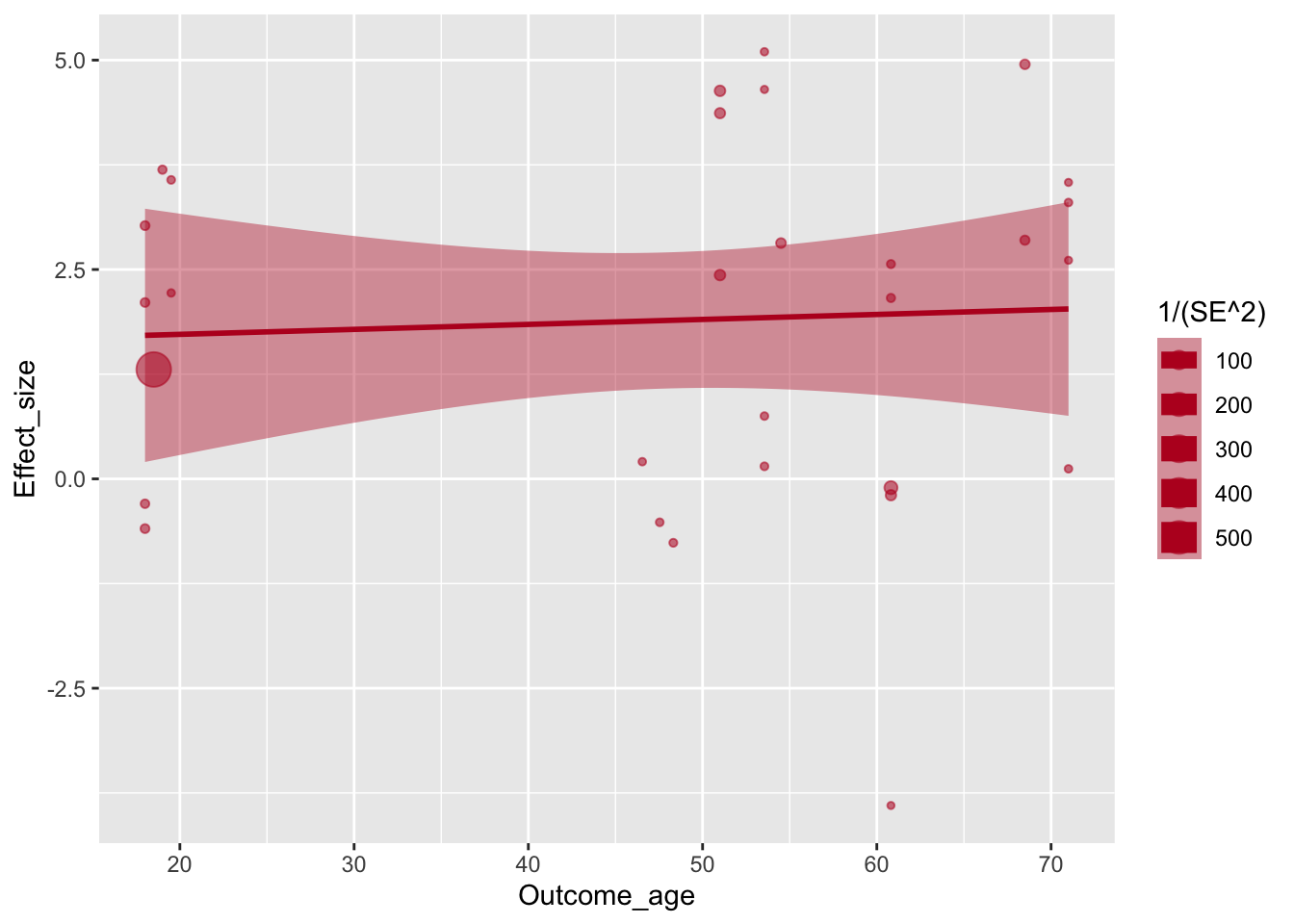
Регрессионную линию авторы немного утоньшают с помощью параметра size =.
ggplot(aes(x=Outcome_age, y=Effect_size, size=1/(SE^2)), data=poli) +
geom_point(alpha=.55, colour="#BA1825") +
geom_smooth(method="lm", colour="#BA1825",fill="#BA1825",size=.5)## `geom_smooth()` using formula 'y ~ x'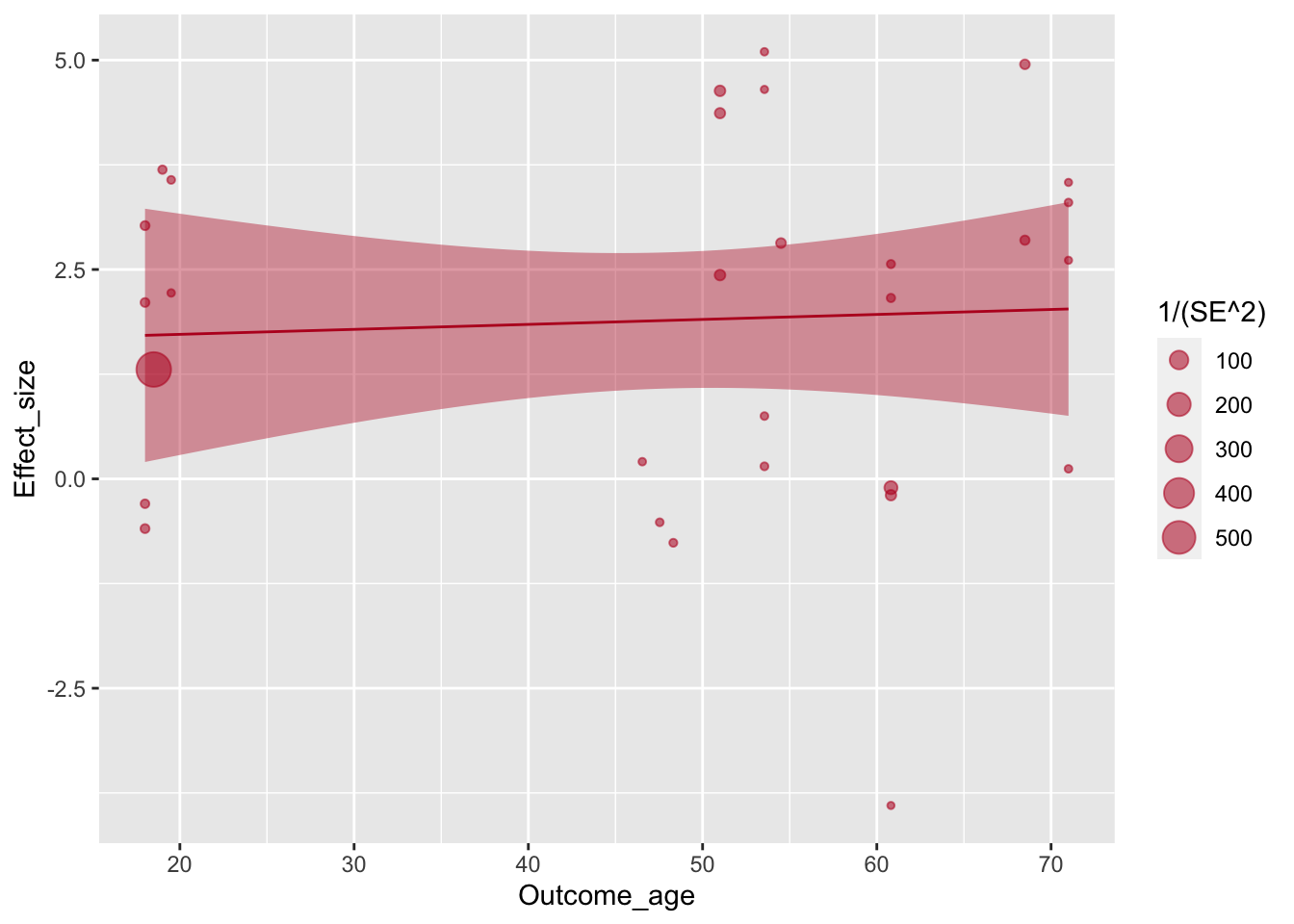
Чтобы сместить фокус в сторону точек, авторы добавляют прозрачности для всего geom_smooth().
ggplot(aes(x=Outcome_age, y=Effect_size, size=1/(SE^2)), data=poli) +
geom_point(alpha=.55, colour="#BA1825") +
geom_smooth(method="lm", colour="#BA1825",fill="#BA1825",size=.5, alpha=.25)## `geom_smooth()` using formula 'y ~ x'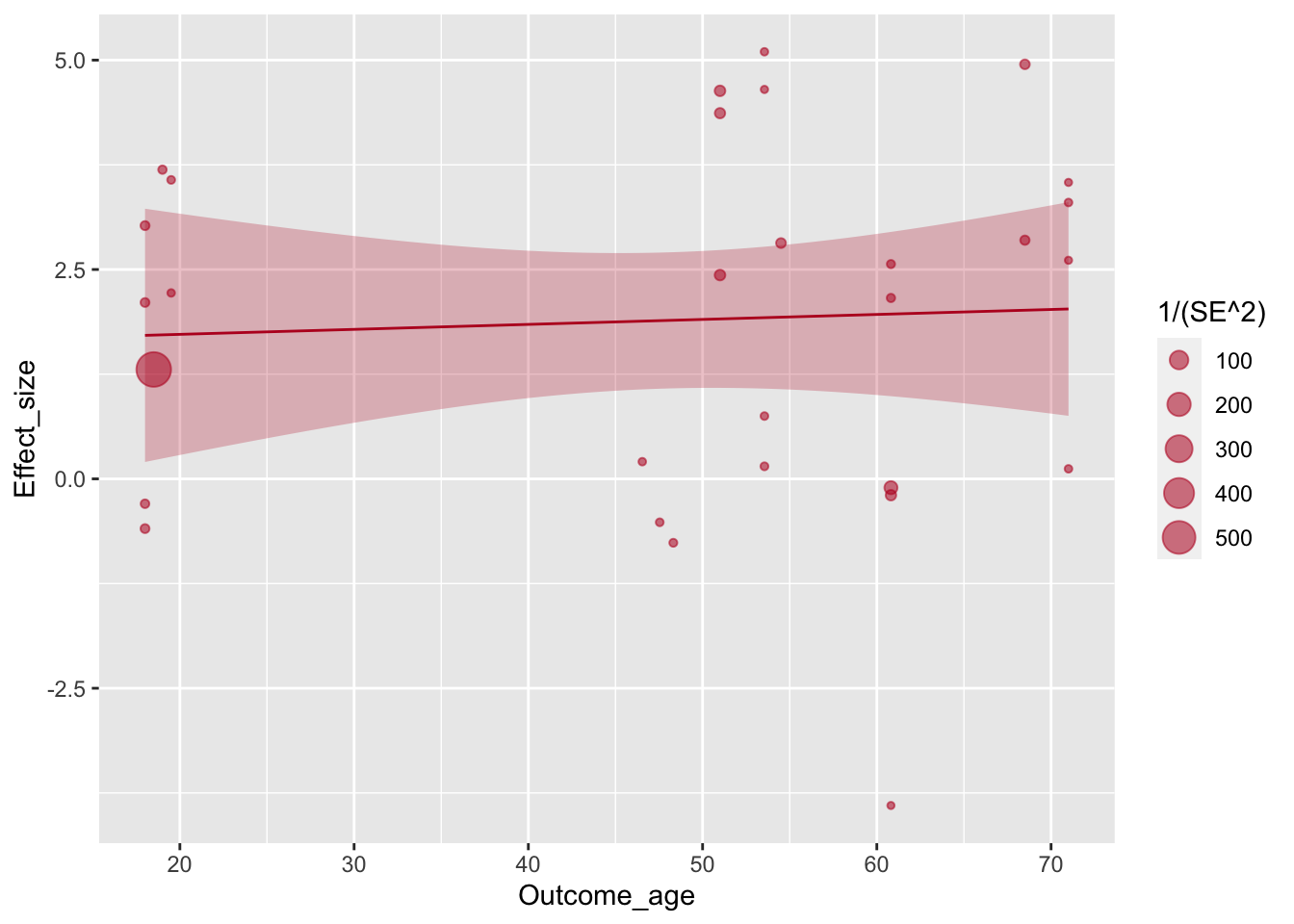
На шкале присутствует 0, и по умолчанию он никак не обозначен. Это легко исправить с помощью вспомогательного геома geom_hline().
ggplot(aes(x=Outcome_age, y=Effect_size, size=1/(SE^2)), data=poli) +
geom_point(alpha=.55, colour="#BA1825") +
geom_hline(yintercept=0) +
geom_smooth(method="lm", colour="#BA1825",fill="#BA1825",size=.5, alpha=.25)## `geom_smooth()` using formula 'y ~ x'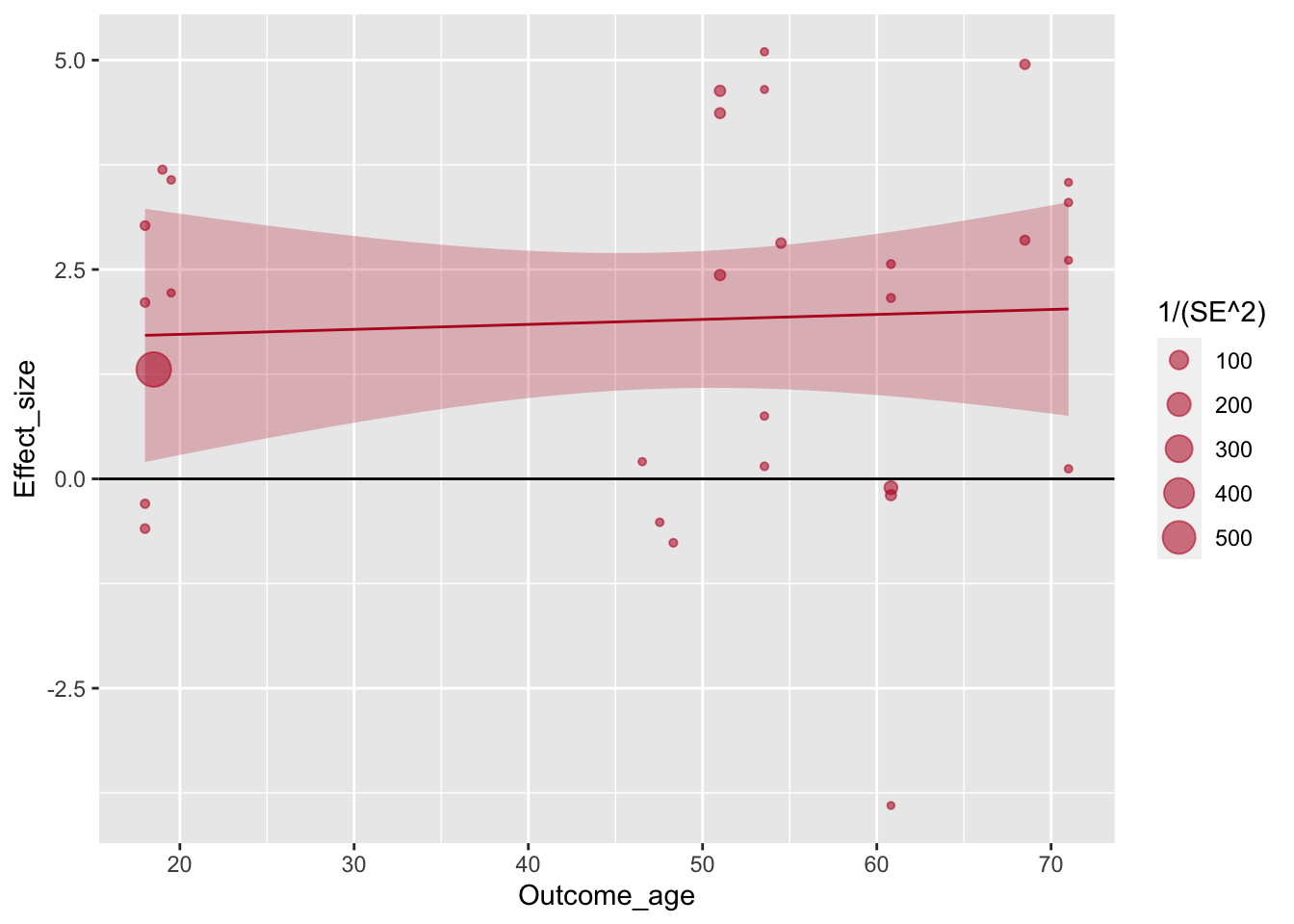
Оттенить эту линию можно, сделав ее пунктирной.
ggplot(aes(x=Outcome_age, y=Effect_size, size=1/(SE^2)), data=poli) +
geom_point(alpha=.55, colour="#BA1825") +
geom_hline(yintercept=0, linetype="dotted") +
geom_smooth(method="lm", colour="#BA1825",fill="#BA1825",size=.5, alpha=.25)## `geom_smooth()` using formula 'y ~ x'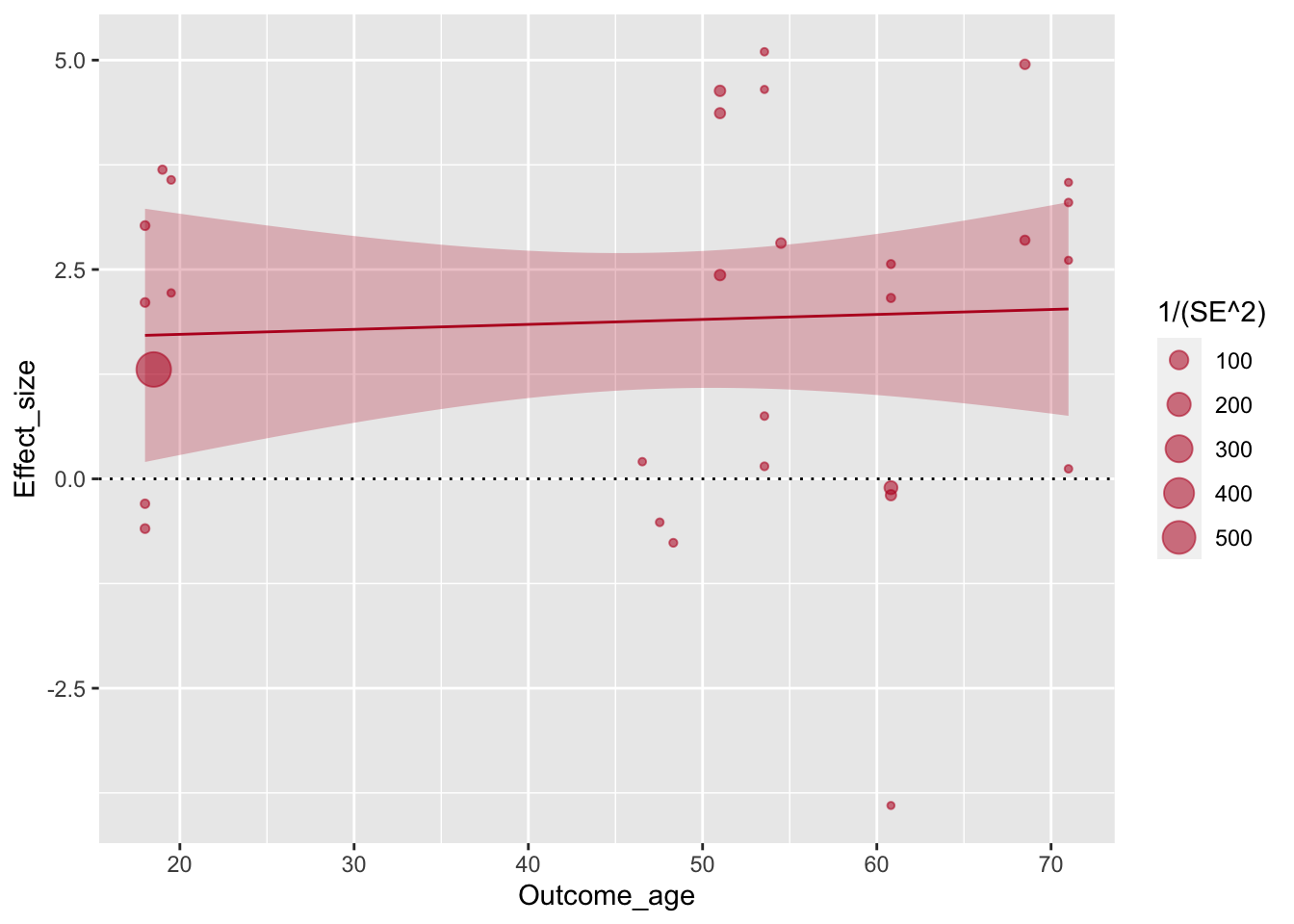
Авторы графика вручную задают деления шкалы по оси x.
ggplot(aes(x=Outcome_age, y=Effect_size, size=1/(SE^2)), data=poli) +
geom_point(alpha=.55, colour="#BA1825") +
geom_hline(yintercept=0, linetype="dotted") +
scale_x_continuous(breaks=c(20,30,40,50,60,70,80)) +
geom_smooth(method="lm", colour="#BA1825",fill="#BA1825",size=.5, alpha=.25)## `geom_smooth()` using formula 'y ~ x'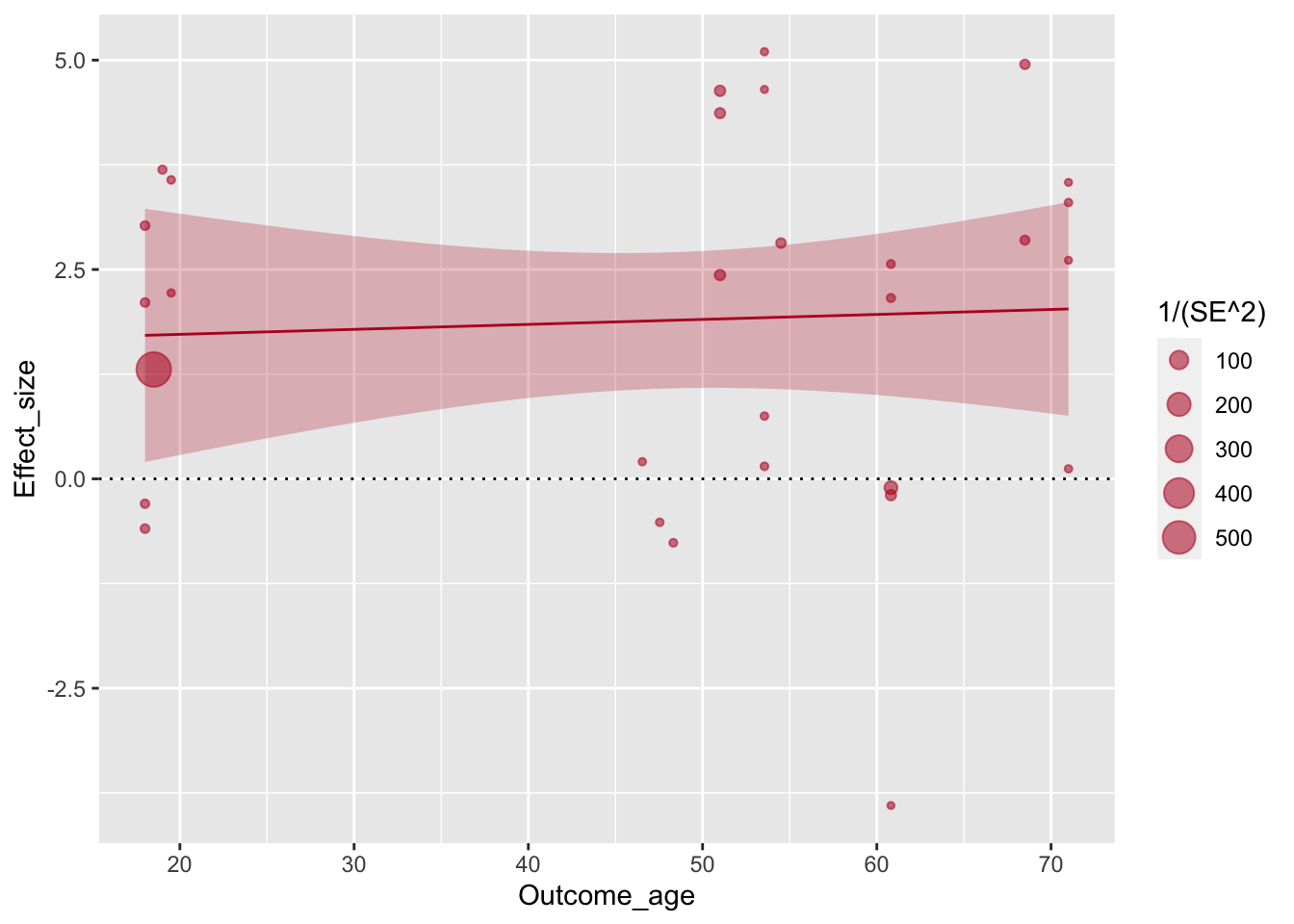
С помощью функции guides() убирают легенду с картинки.
ggplot(aes(x=Outcome_age, y=Effect_size, size=1/(SE^2)), data=poli) +
geom_point(alpha=.55, colour="#BA1825") +
geom_hline(yintercept=0, linetype="dotted") +
scale_x_continuous(breaks=c(20,30,40,50,60,70,80)) +
guides(size=F) +
geom_smooth(method="lm", colour="#BA1825",fill="#BA1825",size=.5, alpha=.25)## `geom_smooth()` using formula 'y ~ x'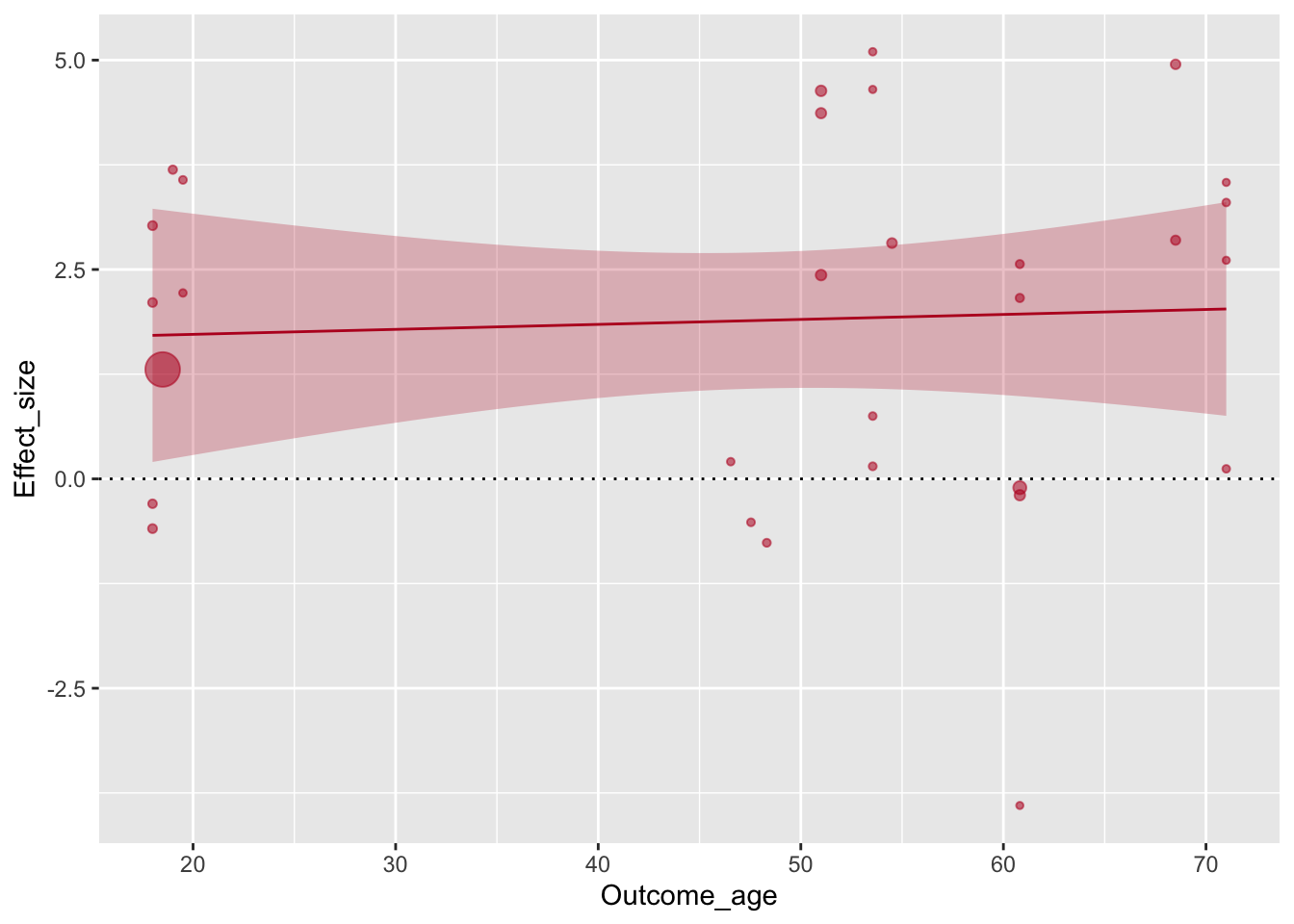
Следующим этапом авторы добавляют подписи шкал и название картинки. Обратите внимание на \n внутри подписи к оси y, которая задает перенос на следующую строку.
ggplot(aes(x=Outcome_age, y=Effect_size, size=1/(SE^2)), data=poli) +
geom_point(alpha=.55, colour="#BA1825") +
geom_hline(yintercept=0, linetype="dotted") +
scale_x_continuous(breaks=c(20,30,40,50,60,70,80)) +
xlab("Age at outcome test (years)") +
ylab("Gain for 1 year of education\n(IQ points)") +
guides(size=F) +
geom_smooth(method="lm", colour="#BA1825",fill="#BA1825",size=.5, alpha=.25) + ggtitle("Policy Change")## `geom_smooth()` using formula 'y ~ x'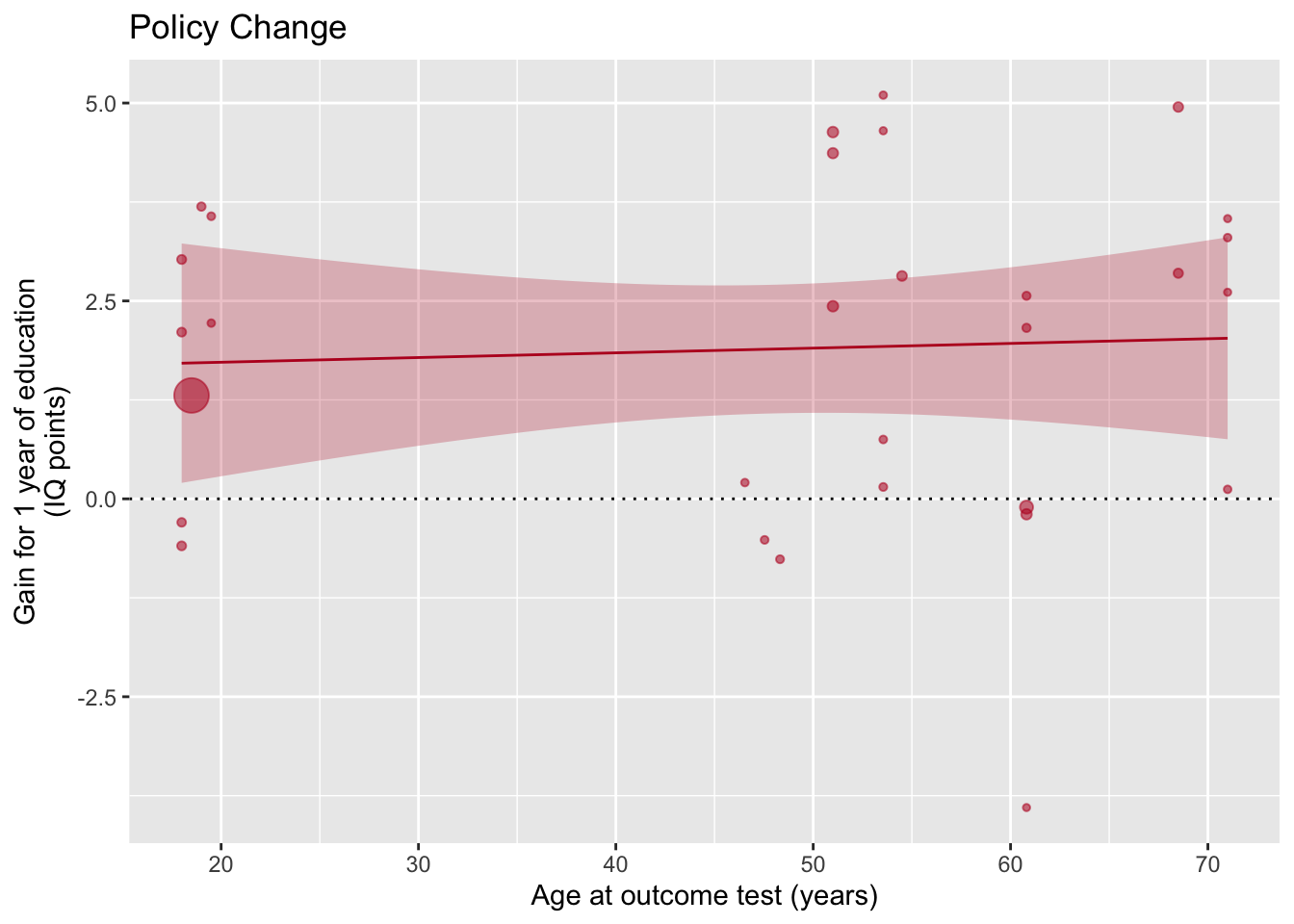
Теперь пришло время сделать график более красивым и понятным с помощью изменения подложки, т.е. работы с темой графика. Здесь тема задается сначала как theme_bw() — встроенная в ggplot2 минималистичная тема, а потом через функцию theme(), через которую можно управлять конкретными элементами темы. Здесь это сделано, чтобы передвинуть название графика к центру.
ggplot(aes(x=Outcome_age, y=Effect_size, size=1/(SE^2)), data=poli) +
geom_point(alpha=.55, colour="#BA1825") +
geom_hline(yintercept=0, linetype="dotted") +
theme_bw() +
scale_x_continuous(breaks=c(20,30,40,50,60,70,80)) +
xlab("Age at outcome test (years)") +
ylab("Gain for 1 year of education\n(IQ points)") +
guides(size=F) +
geom_smooth(method="lm", colour="#BA1825",fill="#BA1825",size=.5, alpha=.25) + ggtitle("Policy Change")+
theme(plot.title = element_text(hjust=0.5))## `geom_smooth()` using formula 'y ~ x'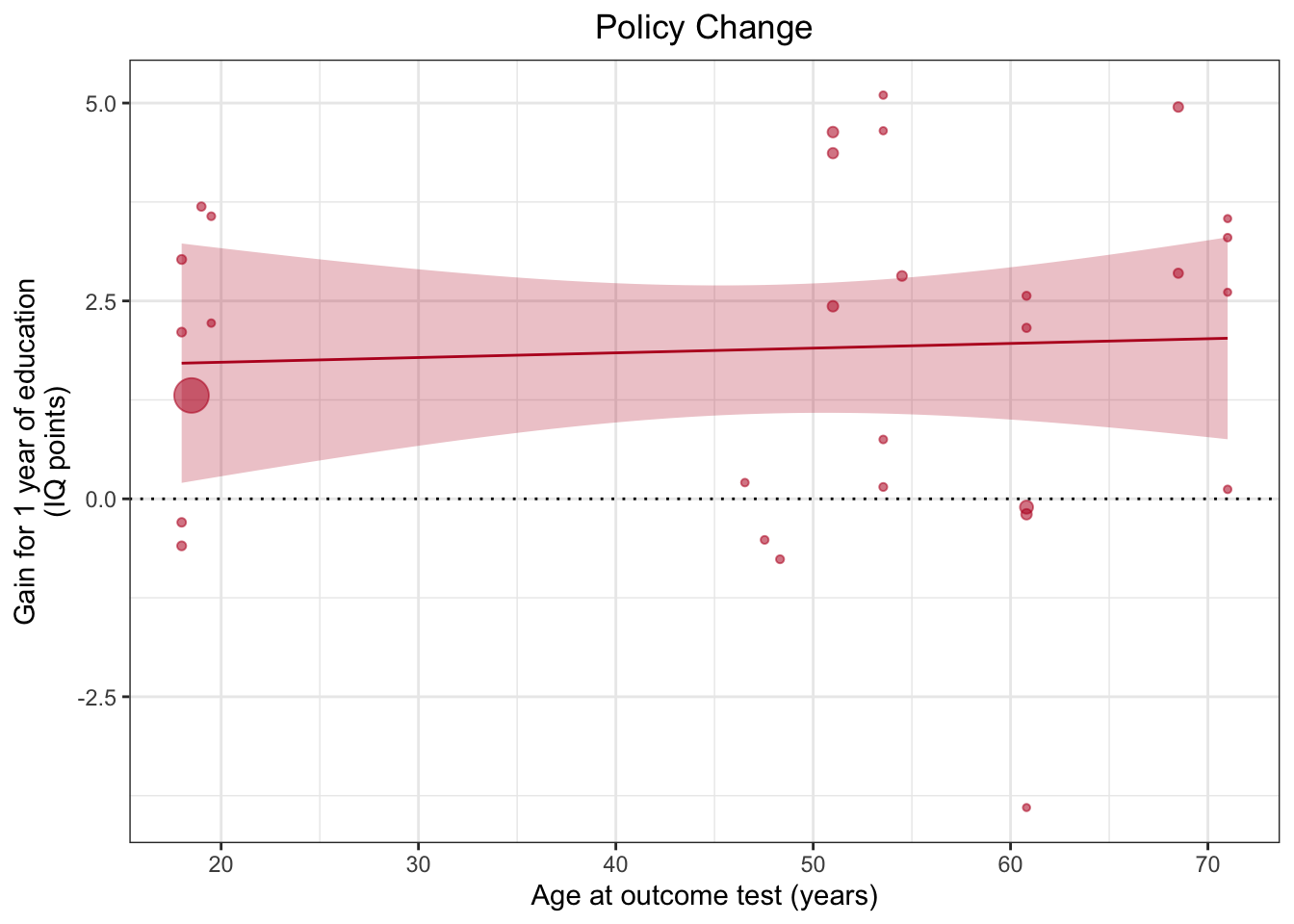
Готово! Мы полностью воспроизвели график авторов статьи с помощью их открытого кода.
Если вы помните, то в изначальном графике было две картинки. Авторы делают их отдельно, с помощью почти идентичного кода. Нечто похожее можно сделать по-другому, применяя фасетки.
Для этого мы возьмем неотфильтрованный датасет df, а с помощью колонки Design, на основании которой разделялся датасет для графиков, произведем разделение графиков внутри самого ggplot объекта. Для этого нам понадобится функция facet_wrap(), в которой с помощью формулы можно задать колонки, по которым будут разделены картинки по вертикали (слева от ~) и горизонтально (справа от ~). Пробуем разделить графики горизонтально:
ggplot(aes(x=Outcome_age, y=Effect_size, size=1/(SE^2)), data=df) +
geom_point(alpha=.55, colour="#BA1825") +
geom_hline(yintercept=0, linetype="dotted") +
theme_bw() +
scale_x_continuous(breaks=c(20,30,40,50,60,70,80)) +
xlab("Age at outcome test (years)") +
ylab("Gain for 1 year of education\n(IQ points)") +
guides(size=F) +
geom_smooth(method="lm", colour="#BA1825",fill="#BA1825",size=.5, alpha=.25) + ggtitle("Policy Change")+
theme(plot.title = element_text(hjust=0.5)) +
facet_wrap(~Design)## `geom_smooth()` using formula 'y ~ x'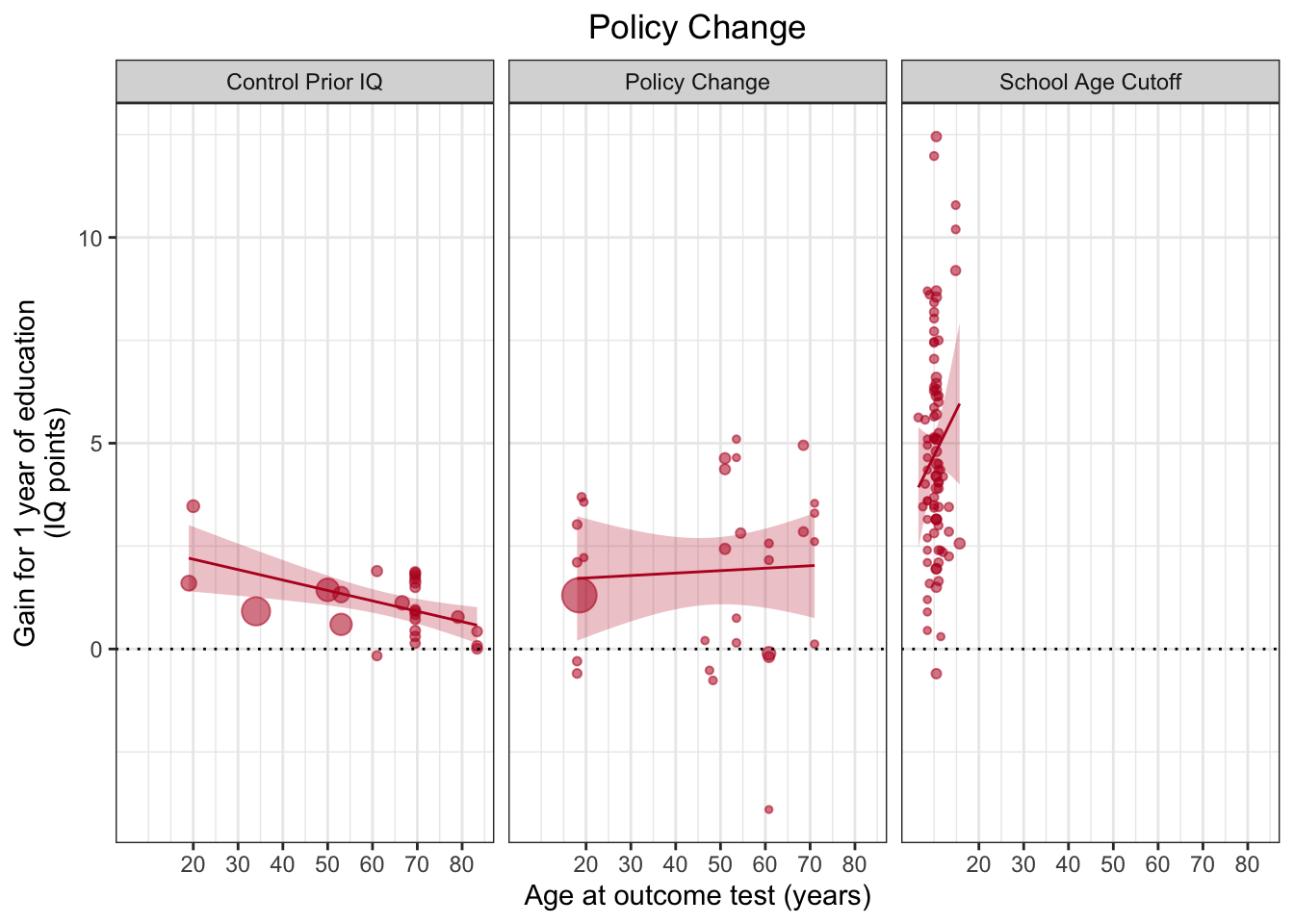
Здесь становится очевидно, почему авторы не включали данные "School Age Cutoff" третьим графиком: средний возраст участников этих исследований сильно отличается.
ggplot(aes(x=Outcome_age, y=Effect_size, size=1/(SE^2)), data=df %>% filter(Design != "School Age Cutoff")) +
geom_point(alpha=.55, colour="#BA1825") +
geom_hline(yintercept=0, linetype="dotted") +
theme_bw() +
scale_x_continuous(breaks=c(20,30,40,50,60,70,80)) +
xlab("Age at outcome test (years)") +
ylab("Gain for 1 year of education\n(IQ points)") +
guides(size=F) +
geom_smooth(method="lm", colour="#BA1825",fill="#BA1825",size=.5, alpha=.25) + ggtitle("Policy Change")+
theme(plot.title = element_text(hjust=0.5)) +
facet_wrap(~Design)## `geom_smooth()` using formula 'y ~ x'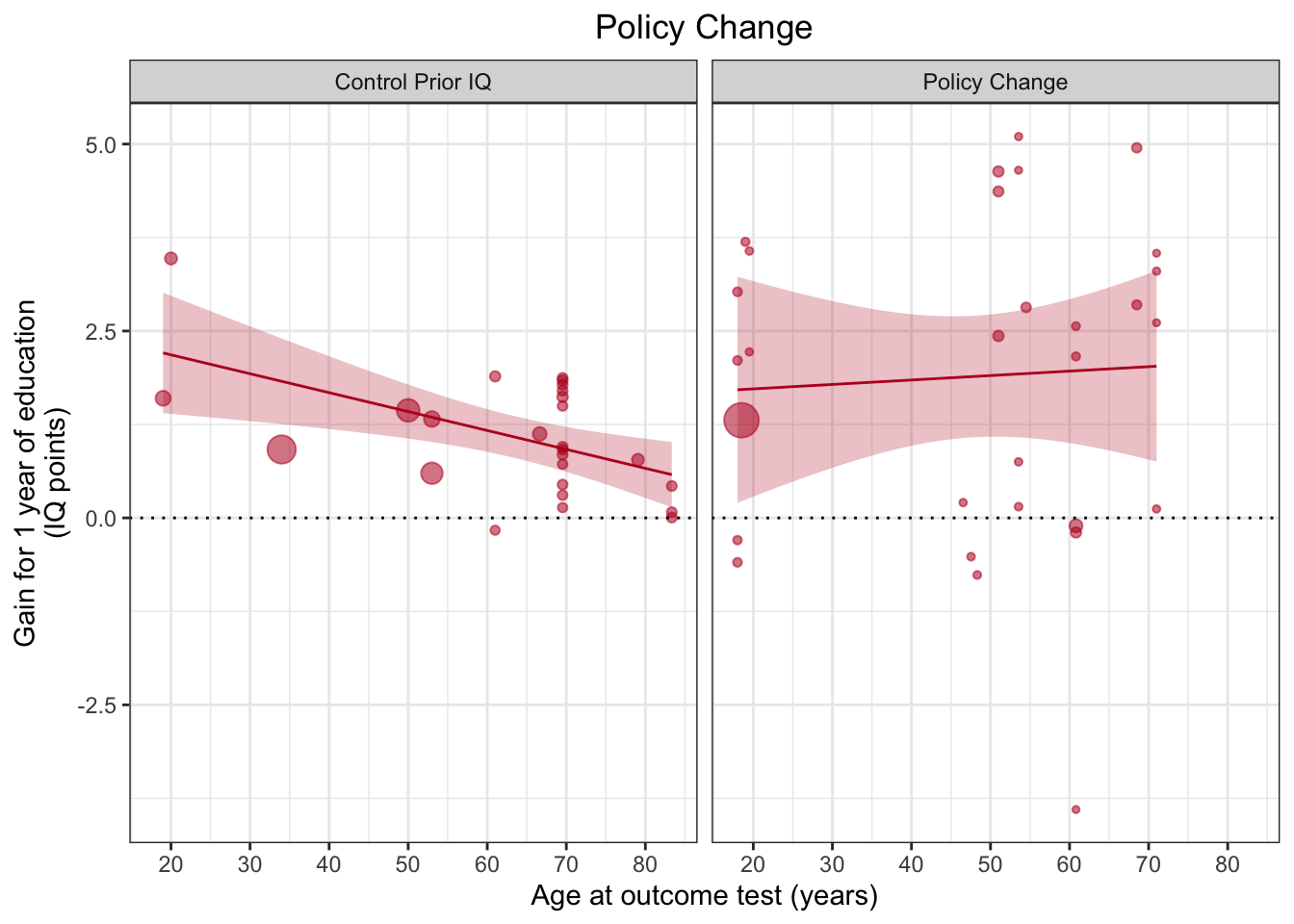
Теперь поставим два графика друг над другом, поместив Design слева от ~ внутри facet_wrap(). Справа нужно добавить точку.
ggplot(aes(x=Outcome_age, y=Effect_size, size=1/(SE^2)), data=df %>% filter(Design != "School Age Cutoff")) +
geom_point(alpha=.55, colour="#BA1825") +
geom_hline(yintercept=0, linetype="dotted") +
theme_bw() +
scale_x_continuous(breaks=c(20,30,40,50,60,70,80)) +
xlab("Age at outcome test (years)") +
ylab("Gain for 1 year of education\n(IQ points)") +
guides(size=F) +
geom_smooth(method="lm", colour="#BA1825",fill="#BA1825",size=.5, alpha=.25) + ggtitle("Policy Change")+
theme(plot.title = element_text(hjust=0.5)) +
facet_grid(Design~.)## `geom_smooth()` using formula 'y ~ x'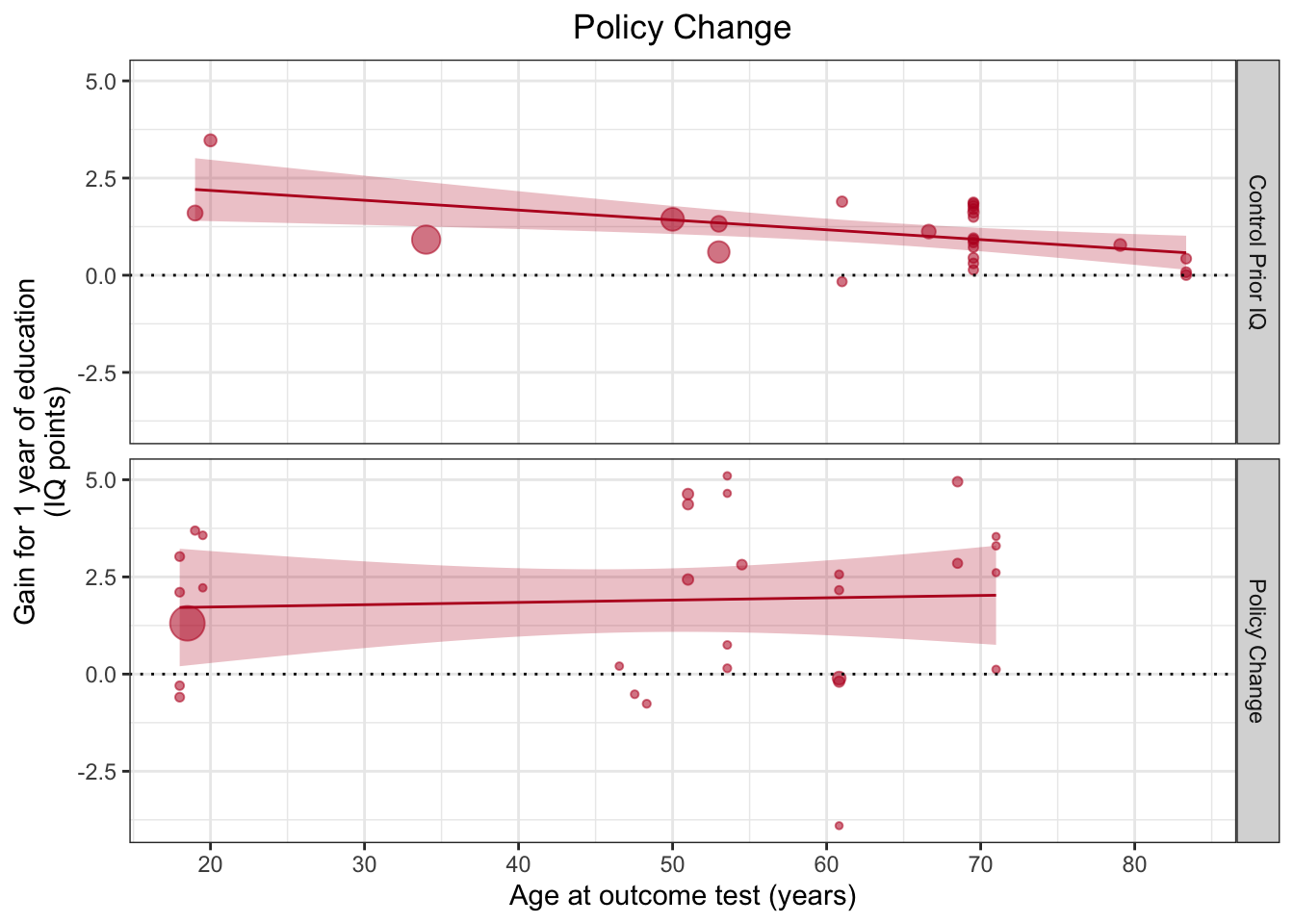
Теперь нужно изменить подписи.
ggplot(aes(x=Outcome_age, y=Effect_size, size=1/(SE^2)), data=df %>% filter(Design != "School Age Cutoff")) +
geom_point(alpha=.55, colour="#BA1825") +
geom_hline(yintercept=0, linetype="dotted") +
theme_bw() +
scale_x_continuous(breaks=c(20,30,40,50,60,70,80)) +
xlab("Age at outcome test (years)") +
ylab("Gain for 1 year of education\n(IQ points)") +
guides(size=F) +
geom_smooth(method="lm", colour="#BA1825",fill="#BA1825",size=.5, alpha=.25) +
ggtitle("Effect of education as a function of age at the outcome test")+
theme(plot.title = element_text(hjust=0.5)) +
facet_grid(Design~.)## `geom_smooth()` using formula 'y ~ x'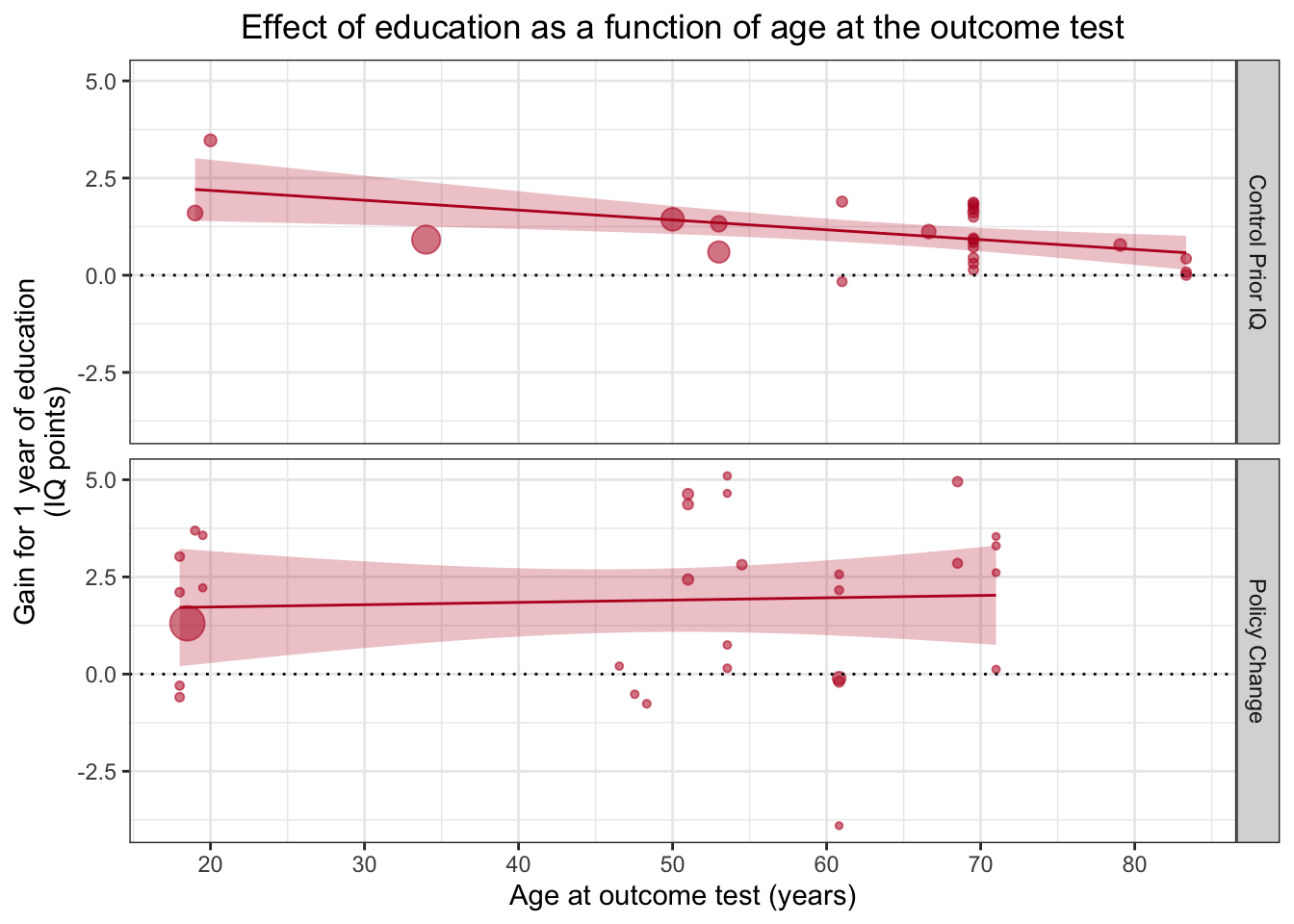
Чтобы акцентировать графики, можно раскрасить их в разные цвета в дополнение к фасеткам. Для этого мы переносим colour = и fill = из параметров соответствующих геомов внутрь эстетик и делаем зависимыми от Design. Поскольку эти эстетики (точнее, colour =) одинаковы заданы для двух геомов (geom_point() и geom_smooth()), то мы спокойно можем вынести их в эстетики по умолчанию — в параметры aes() внутри ggplot().
При этом сразу выключим легенды для новых эстетик, потому они избыточны.
ggplot(aes(x=Outcome_age, y=Effect_size, size=1/(SE^2), colour = Design, fill = Design), data=df %>% filter(Design != "School Age Cutoff")) +
geom_point(alpha=.55) +
geom_hline(yintercept=0, linetype="dotted") +
theme_bw() +
scale_x_continuous(breaks=c(20,30,40,50,60,70,80)) +
xlab("Age at outcome test (years)") +
ylab("Gain for 1 year of education\n(IQ points)") +
guides(size=FALSE, colour = FALSE, fill = FALSE) +
geom_smooth(method="lm", size=.5, alpha=.25) +
ggtitle("Effect of education as a function of age at the outcome test")+
theme(plot.title = element_text(hjust=0.5)) +
facet_grid(Design~.)## `geom_smooth()` using formula 'y ~ x'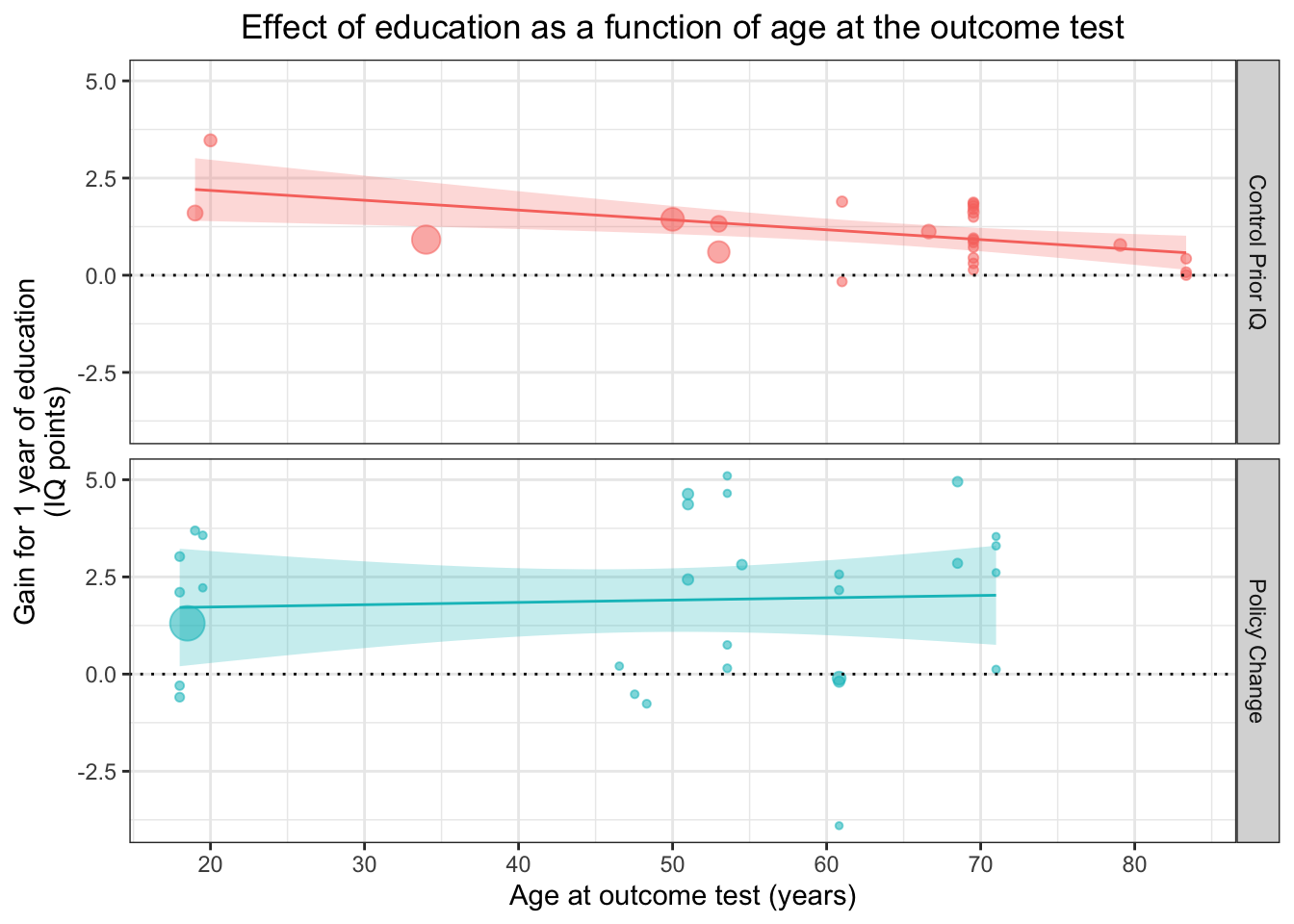
Слишком блеклая палитра? Не беда, можно задать палитру вручную! В ggplot2 встроены легендарные Brewer’s Color Palettes, которыми мы и воспользуемся.
Функции для шкал устроены интересным образом: они состоят из трех слов, первое из которых scale_*_*(), второе — эстетика, например, scale_color_*(), а последнее слово — тип самой шкалы, в некоторых случаях - специальное название для используемой шкалы, как и в случае с scale_color_brewer().
meta_2_gg <- ggplot(aes(x=Outcome_age, y=Effect_size, size=1/(SE^2), colour = Design, fill = Design), data=df %>% filter(Design != "School Age Cutoff")) +
geom_point(alpha=.55) +
geom_hline(yintercept=0, linetype="dotted") +
theme_bw() +
scale_x_continuous(breaks=c(20,30,40,50,60,70,80)) +
xlab("Age at outcome test (years)") +
ylab("Gain for 1 year of education\n(IQ points)") +
guides(size=FALSE, colour = FALSE, fill = FALSE) +
geom_smooth(method="lm", size=.5, alpha=.25) +
ggtitle("Effect of education as a function of age at the outcome test")+
theme(plot.title = element_text(hjust=0.5)) +
facet_grid(Design~.)+
scale_colour_brewer(palette = "Set1")+
scale_fill_brewer(palette = "Set1")
meta_2_gg## `geom_smooth()` using formula 'y ~ x'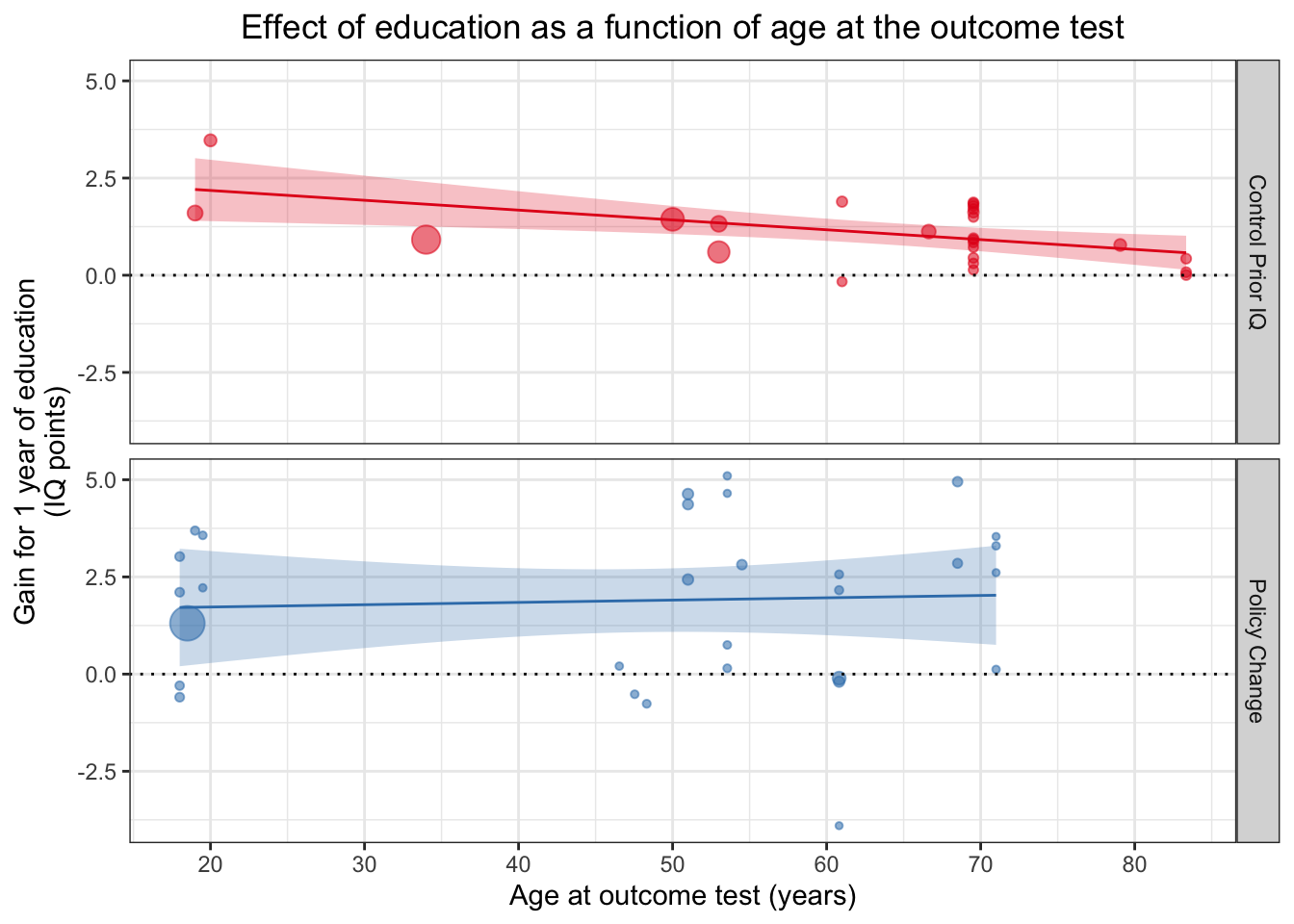
10.11 Расширения ggplot2
ggplot2 стал очень популярным пакетом и быстро обзавелся расширениями - пакетами R, которые являются надстройками над ggplot2. Эти расширения бывают самого разного рода, например, добавляющие дополнительные геомы или просто реализующие отдельные типы графиков на языке ggplot2.
Я рекомендую посмотреть самостоятельно галерею расширений ggplot2: https://exts.ggplot2.tidyverse.org/gallery/
Для примера мы возьмем пакет hrbrthemes, который предоставляет дополнительные темы для ggplot2, компоненты тем и шкалы.
install.packages("hrbrthemes")library(hrbrthemes)
meta_2_gg +
theme_ipsum_tw()## `geom_smooth()` using formula 'y ~ x'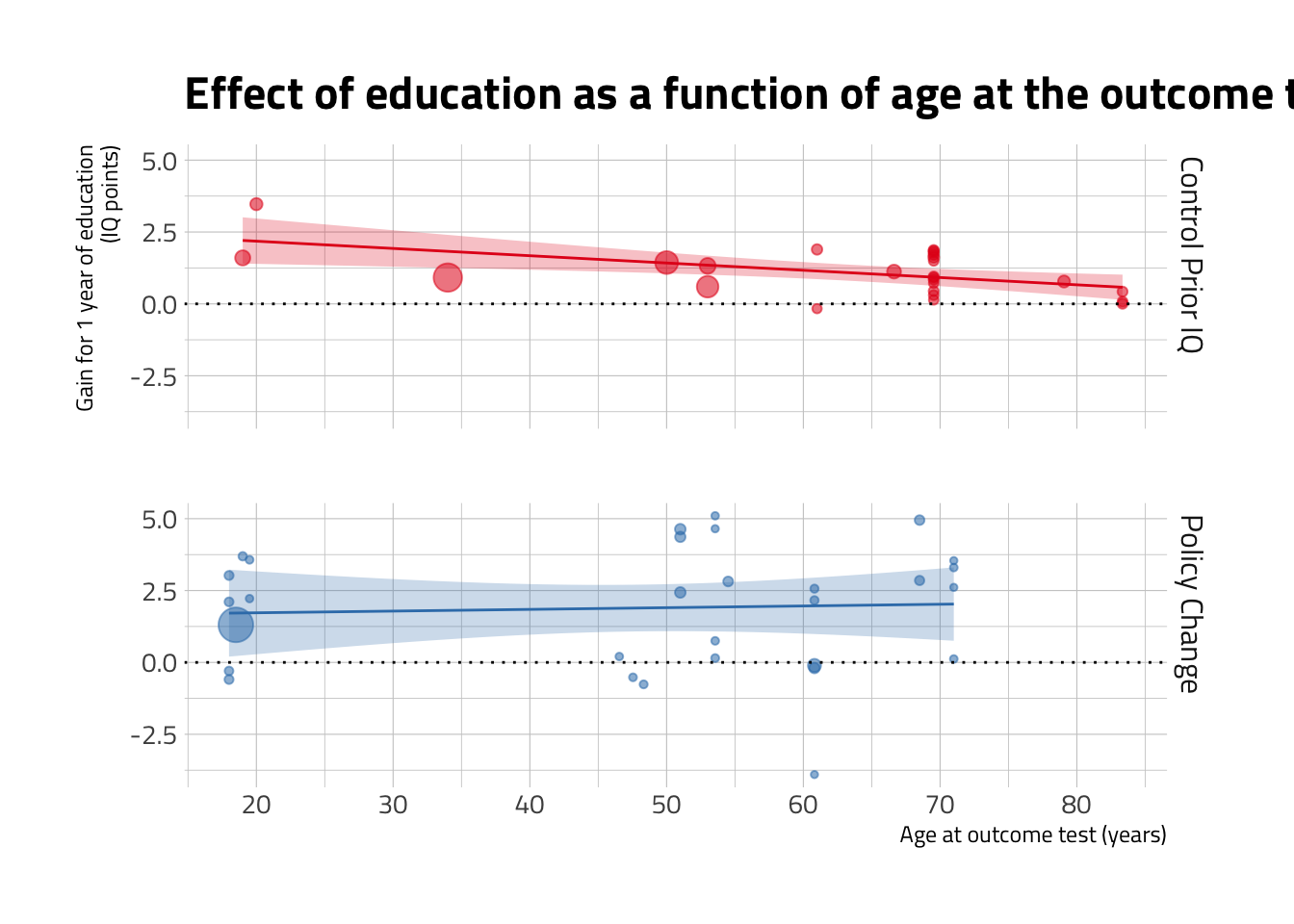
10.12 Динамические визуализации в R
10.12.1 Интерфейс для JavaScript фреймворков: пакет htmlwidgets
До этого мы делали только статические картинки, но в R можно делать динамические визуализации с интерактивными элементами! Делаются такие визуализации на основе JavaScript, в первую очередь, на основе фреймворка D3.js. Существует пакет для R htmlwidgets, который предоставляет интерфейс для работы с JavaScript визуализациями из R и вставлять их в RMarkdown HTML-документы и веб-приложения Shiny. htmlwidgets — это пакет, в первую очередь, для разработчиков R пакетов, которые делают на его основе очень простые и удобные в использовании R пакеты для создания динамических визуализаций и прочих динамических элементов.
10.12.2 Динамические визуализации в plotly
Один из самых распространенных средств для динамических визуализаций — это пакет plotly.
install.packages("plotly")library(plotly)##
## Присоединяю пакет: 'plotly'## Следующий объект скрыт от 'package:ggplot2':
##
## last_plot## Следующий объект скрыт от 'package:stats':
##
## filter## Следующий объект скрыт от 'package:graphics':
##
## layoutЕсть два базовых способа использовать plotly в R. Первый — это просто оборачивать готовые графики ggplot2 с помощью функции ggplotly().
ggplotly(meta_2_gg)## `geom_smooth()` using formula 'y ~ x'Не всегда это получается так, как хотелось бы, но простота этого способа подкупляет: теперь наведение на курсора на точки открывает небольшое окошко с дополнительной информацией о точке (конечно, если вы читаете эту книгу в PDF или ePUB, то этого не увидите).
Другой способ создания графиков — создание вручную с помощью plot_ly(). Такой способ частично напоминает ggplot2 использованием пайпов (обычных %>%, а не +), задание эстетик здесь происходит с помощью ~.
plot_ly(poli,
x = ~Outcome_age,
y = ~Effect_size,
size = ~1/(SE^2),
color = ~Effect_size,
sizes = c(40, 400),
text = ~paste("N: ", n, '<br>Country:', Country)) %>%
add_markers()## Warning: `arrange_()` is deprecated as of dplyr 0.7.0.
## Please use `arrange()` instead.
## See vignette('programming') for more help
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_warnings()` to see where this warning was generated.## Warning: `line.width` does not currently support multiple values.10.12.3 Другие пакеты для динамической визуализации
Кроме plotly есть и множество других HTML-виджетов для динамической визуализации. Я рекомендую посмотреть их самостоятельно на
http://gallery.htmlwidgets.org/
Выделю некоторые из них:
echarts4r— один из основных конкурентов дляplotly. Симпатичный, работает довольно плавно, синтаксис тоже пытается вписаться в логику tidyverse.leaflet— основной (но не единственный!) пакет для работы с картами. Leaflet — это очень популярная библиотека JavaScript, используемая во многих веб-приложениях, а пакетleaflet- это довольно понятный интерфейс к ней с широкими возможностями.networkD3— пакет для интерактивной визуализации сетей. Подходит для небольших сетей.
Квартиль — это частный пример квантиля. Другой известный квантиль — процентиль. Процентили часто используют для сравнения значения с другими значениями. Например, 63ий процентиль означает, что данное значение больше 63% значений в выборке.↩︎
идентична по своему смыслу функции
dplyr::count, которая считает частоты по выбранной колонке тиббла @ref(tidy_count)↩︎Декартова система координат названа в честь великого математика и философа Рене Декарта, на латинском — Renatus Cartesius, отсюда и название cartesian coordinate system.↩︎
Кстати, именно функция
subset()вдохновила Уикхема на созданиеfilter().↩︎