pow <- function(x, p) {
power <- x ^ p
return(power)
}
pow(3, 2)[1] 9И.С. Поздняков 
Поздравляю, сейчас мы выйдем на качественно новый уровень владения R. Вместо того, чтобы пользоваться теми функциями, которые уже написали за нас, мы можем сами создавать свои функции!
Синтаксис создания функции внешне похож на создание циклов или условных конструкций:
function(параметры) { тело функции }Разберем подробнее все три элемента:
function;return(). А если return() так и не встретится — результат последней команды в теле, как если бы мы выполнили ее в консоли.Созданную функцию нужно присвоить переменной, чтобы потом ее вызывать и использовать.
Сделаем простой пример — функцию pow(), которая возводит число x в степень p:
pow <- function(x, p) {
power <- x ^ p
return(power)
}
pow(3, 2)[1] 9Ту же pow() можно записать и без return() — результат вернется и так:
pow <- function(x, p) {
x ^ p
}
pow(3, 2)[1] 9Именно так и рекомендуется создавать функции, используя return() только в том случае, если нужно вернуть значение из функции досрочно, не дожидаясь завершения ее выполнения.
Если в последней строчке будет присвоение, то функция ничего не вернет обратно. Это очень распространенная ошибка: функция вроде бы работает правильно, но ничего не возвращает. Вспомните: функция возвращает то, что вывелось бы в консоли, — а присваивание в консоли ничего не печатает.
pow <- function(x, p) {
power <- x ^ p # Функция ничего не вернет, потому что в последней строчке присвоение!
}
pow(3, 2) # ничего не возвращается из функцииЕсли функция небольшая, то ее можно записать в одну строчку без фигурных скобок.
pow <- function(x, p) x ^ p
pow(3, 2) [1] 9Мы можем оставить в функции параметры по умолчанию.
pow <- function(x, p = 2) x ^ p
pow(3) [1] 9pow(3, 3) [1] 27Когда стоит создавать функции? Существует “правило трех” — если у вас есть три куска очень похожего кода, то самое время превратить код в функцию. Это очень условное правило, но, действительно, стоит избегать «копипастинга» в коде. В этом случае очень легко ошибиться, а сам код становится нечитаемым.
Есть и другой подход к созданию функций: их стоит создавать не столько для того, чтобы использовать тот же код снова, сколько для абстрагирования от того, что происходит в отдельных строчках кода. Если несколько строчек кода были написаны для того, чтобы решить одну задачу, которой можно дать понятное название (например, подсчет какой-то особенной метрики, для которой нет готовой функции в R), то этот код стоит обернуть в функцию. Если функция работает корректно, то теперь не нужно думать над тем, что происходит внутри нее. Вы можете мысленно представить ее как операцию, которая имеет определенный вход и выход — как и встроенные функции в R.
Отсюда следует важный вывод, что хорошее название для функции — это очень важно. Очень, очень, очень важно. Впрочем, это важно для любых переменных.
Лучший способ не бояться ошибок и предупреждений — научиться прописывать их самостоятельно в собственных функциях. Это позволит понять, что за текстом предупреждений и ошибок, которые у вас возникают, стоит забота разработчиков о пользователях, которые хотят максимально обезопасить нас от наших непродуманных действий.
Хорошо написанные функции не только выдают правильный результат на все возможные адекватные данные на входе, но и не дают получить правдоподобные результаты при неадекватных входных данных. Как вы уже знаете, если на входе у вас имеются пропущенные значения, то многие функции будут в ответ тоже выдавать пропущенные значения. И это вполне осознанное решение, которое позволяет избегать ситуаций вроде той, когда около одной пятой научных статей по генетике содержало ошибки в приложенных данных (Ziemann и др., 2016) и замечать пропущенные значения на ранней стадии. Кроме того, можно проводить проверки на адекватность входящих данных (sanity check).
Разберем проверку на адекватность входящих данных на примере самодельной функции imt(), которая выдает индекс массы тела, если на входе задать массу (параметр weight =) в килограммах и рост (параметр height =) в метрах.
imt <- function(weight, height) weight / height ^ 2Проверим, что функция работает верно:
w <- c(60, 80, 120)
h <- c(1.6, 1.7, 1.8)
imt(weight = w, height = h)[1] 23.43750 27.68166 37.03704Очень легко перепутать и написать рост в сантиметрах. Было бы здорово предупредить об этом пользователя, показав ему предупреждающее сообщение, если рост больше, чем, например, 3. Это можно сделать с помощью функции warning().
imt <- function(weight, height) {
if (any(height > 3)) warning("Рост в аргументе height больше 3: возможно, указан рост в сантиметрах, а не в метрах\n")
weight / height ^ 2
}
imt(78, 167)Warning in imt(78, 167): Рост в аргументе height больше 3: возможно, указан рост в сантиметрах, а не в метрах[1] 0.002796802В некоторых случаях ответ будет совершенно точно некорректным, хотя функция все посчитает и выдаст ответ, как будто так и надо. Например, если какой-то из аргументов функции imt() будет меньше или равен 0. В этом случае нужно прописать проверку на это условие. Если это действительно так, то можно поступить еще строже: выдать пользователю ошибку.
imt <- function(weight, height) {
if (any(weight <= 0 | height <= 0)) stop("Индекс массы тела не может быть посчитан для отрицательных значений")
if (any(height > 3)) warning("Рост в аргументе height больше 3: возможно, указан рост в сантиметрах, а не в метрах\n")
weight / height ^ 2
}
imt(-78, 167)Error in `imt()`:
! Индекс массы тела не может быть посчитан для отрицательных значенийКогда проверок несколько, их удобно собрать внутри функции stopifnot(). Эта функция по очереди проверяет переданные условия и останавливает выполнение функции с ошибкой, когда какое-то из них окажется ложным. Условие можно передать с именем, оно станет текстом ошибки:
imt <- function(weight, height) {
stopifnot("масса должна быть положительной" = all(weight > 0),
"рост должен быть положительным" = all(height > 0))
weight / height ^ 2
}
imt(-78, 167)Error in `imt()`:
! масса должна быть положительнойОтдельный случай — когда аргумент должен принимать одно из нескольких допустимых значений. Здесь помогает match.arg(): варианты перечисляют прямо в значении параметра по умолчанию, а внутри функции вызывают match.arg(). Он подставит первый вариант по умолчанию и выдаст понятную ошибку, если передать что-то постороннее:
greet <- function(lang = c("ru", "en")) {
lang <- match.arg(lang)
if (lang == "ru") "Привет" else "Hi"
}
greet() # по умолчанию берется первый вариант[1] "Привет"greet("en")[1] "Hi"greet("de") # недопустимый вариант -- ошибкаError in `match.arg()`:
! 'arg' should be one of "ru", "en"Такой параметр-выбор вы уже встречали — ties.method = в функции rank() (Глава 3.6.3): внутри он устроен именно через match.arg().
Когда вы попробуете самостоятельно прописывать предупреждения и ошибки в функциях, то быстро поймете, что ошибки — это вовсе не обязательно результат того, что где-то что-то сломалось и нужно паниковать. Совсем даже наоборот, прописанная ошибка — чья-то забота о пользователях, которых пытаются максимально проинформировать о том, что и почему пошло не так.
Это естественно в начале работы с R (и вообще с программированием) избегать ошибок и пугаться их. Конечно, в самом начале обучения большая часть из них остается непонятной. Но постарайтесь понять текст ошибки, вспомнить, в каких случаях у вас возникала похожая ошибка. Очень часто этого оказывается достаточно, чтобы понять причину ошибки, даже если вы только-только начали изучать R.
Ну а в дальнейшем я советую ознакомиться со средствами отладки кода в R для того, чтобы научиться справляться с ошибками в своем коде на более продвинутом уровне.
Ранее мы убедились (Глава 2.4), что арифметические операторы — это функции. Да и не только арифметические операторы, но и все остальные операторы типа > или %in%. И даже, например, скобочки для индексирования [ — это тоже функции. Более того, функциями оказываются даже управляющие конструкции: if, for и подобные — это зарезервированные (ключевые) слова (см. Глава 7), но за каждым из них стоит функция, которую можно вызвать и напрямую:
`if`(2 > 1, "да", "нет")[1] "да"Зарезервированное слово — это просто удобный синтаксис для вызова такой функции. В принципе, всё, что происходит в R — это вызов функции.
Чтобы понять вычисления в R, полезны два девиза: всё, что существует, — это объект; всё, что происходит, — это вызов функции.
— Джон Чеймберс, один из создателей R (Chambers, 2008)
А сами функции — это объекты первого порядка в R. Это означает, что с функциями вы можете делать практически все то же самое, что и с другими объектами в R (векторами, датафреймами и т.д.). Небольшой пример, который может взорвать ваш мозг:
list(mean, min, `{`)[[1]]
function (x, ...)
UseMethod("mean")
<bytecode: 0x1385d85f8>
<environment: namespace:base>
[[2]]
function (..., na.rm = FALSE) .Primitive("min")
[[3]]
.Primitive("{")Мы можем создать список из функций! Зачем — это другой вопрос, но ведь можем же! Например, создавать списки из функций может быть удобным для продвинутых операций в across() в пакете {dplyr} (см. Глава 11.3).
Еще можно создавать функции внутри функций1, использовать функции в качестве аргументов функций, сохранять функции как переменные. Пожалуй, самое важное из этого всего — это то, что функция может быть аргументом в функции. Не просто название функции как строковая переменная, не результат выполнения функции, а именно сама функция как объект! Это лежит в основе использования семейства функций apply(), о которых пойдет речь далее, и многих фишек tidyverse.
Один из важных аспектов функциональной парадигмы в программировании — это использование чистых функций (pure functions). У чистых функций две ключевые особенности:
Критерий детерминированности исключает функции для импорта данных (подставив разные файлы с одинаковым названием, мы получим разные результаты) и функции вроде Sys.time() для определения текущего времени. Ну а без функций с побочными эффектами… зачем нам вообще тогда что-то делать в R?
Короче говоря, R не является на 100% функциональным языком: не все функции в нем чистые. Тем не менее в R принято придерживаться функционального стиля и стараться создавать чистые функции там, где это не противоречит здравому смыслу. В первую очередь это означает не создавать переменные в глобальном окружении изнутри функций и полагаться только на переменные в окружении самой функции. Ограничение не такое уж большое, зато благодаря ему функции становятся полностью предсказуемыми, а весь анализ данных можно представить как набор функций, примененных к данным. Этим мы будем активно пользоваться с функциями семейства apply() (Глава 8.6), а особенно — с пайпами и tidyverse (Глава 10).
apply()apply() для матрицСемейство функций apply()? Да, их целое множество: apply(), lapply(), sapply(), vapply(), tapply(), mapply(), rapply()… Ладно, не пугайтесь, всех их знать не придется. Обычно достаточно первых двух-трех. Проще всего пояснить как они работают на простой матрице с числами:
A <- matrix(1:12, 3, 4)
A [,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12Теперь представим, что нам нужно посчитать что-нибудь (например, сумму) по каждой из строк. С помощью функции apply() вы можете в буквальном смысле “применить” функцию к матрице или датафрейму. Синтаксис такой: apply(X, MARGIN, FUN, ...), где X — данные, MARGIN это 1 (для строк), 2 (для колонок), c(1,2) для строк и колонок (т.е. для каждого элемента по отдельности), а FUN — это функция, которую вы хотите применить! apply() будет брать строки/колонки из X в качестве первого аргумента для функции.
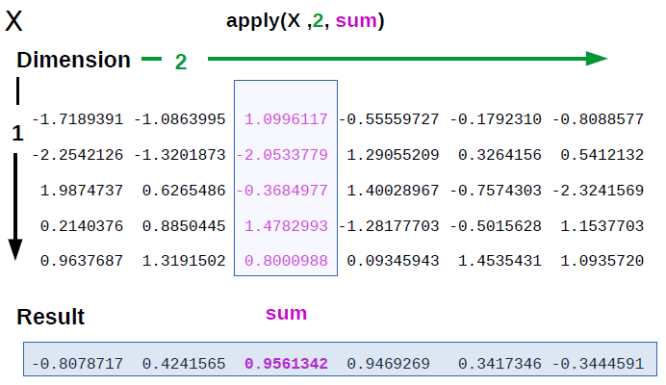
Давайте разберем на примере:
apply(A, 1, sum) # сумма по каждой строчке[1] 22 26 30apply(A, 2, sum) # сумма по каждой колонке[1] 6 15 24 33apply(A, c(1,2), sum) # кхм... сумма каждого элемента [,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12Если же мы хотим прописать дополнительные аргументы для функции, то их можно перечислить через запятую после функции:
A[2, 2] <- NA
A [,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 NA 8 11
[3,] 3 6 9 12apply(A, 1, sum)[1] 22 NA 30apply(A, 1, sum, na.rm = TRUE)[1] 22 21 30Что это за многозначительное ... в параметрах функции apply(X, MARGIN, FUN, ...)? Это многоточие (dot-dot-dot) — особенный параметр, который принимает сколько угодно аргументов — как именованных, так и нет. Мы уже знакомы с функциями, у которых есть параметр .... Взять, к примеру, функцию c(), которая соединяет произвольное количество векторов вместе (Глава 3.1): многоточие как раз и является основным параметром этой функции. Если переданные в ... аргументы не именованы, то мы получаем обычный atomic вектор, а если именованы — именованный вектор (Глава 3.5). И c() — отнюдь не единственный встречавшийся нам пример: аналогичным образом работают list(), data.frame(), а еще paste(), sum() и многие другие.
У apply() роль многоточия другая: оно пробрасывает аргументы дальше, в функцию, которую мы передаем в FUN =. Именно так na.rm = TRUE из примера выше добрался до sum().
Многоточие можно использовать и в собственных функциях. Допустим, мы хотим сделать функцию, которая считает средний индекс массы тела по векторам массы и роста:
imt_mean <- function(weight, height) mean(weight / height ^ 2)
imt_mean(c(60, 80, NA), c(1.6, 1.7, 1.8))[1] NAЧто делать с NA? Можно прописать у своей функции параметр na.rm = и вручную передать его в mean():
imt_mean <- function(weight, height, na.rm = FALSE) {
imt <- weight / height ^ 2
mean(imt, na.rm = na.rm)
}
imt_mean(c(60, 80, NA), c(1.6, 1.7, 1.8), na.rm = TRUE)[1] 25.55958И это сработало. Но что, если таких параметров будет много? Тогда нам придется вручную «прокладывать» каждый параметр, который может понадобиться. А можно вместо этого объявить параметр ... и внутри тела функции передать ... в функцию mean(). Тогда дополнительные аргументы, переданные в нашу функцию, будут проброшены в mean():
imt_mean <- function(weight, height, ...) mean(weight / height ^ 2, ...)
imt_mean(c(60, 80, NA), c(1.6, 1.7, 1.8), na.rm = TRUE)[1] 25.55958Причем работать это будет не только с na.rm =, но и с любым другим дополнительным аргументом!
Что делать, если мы хотим сделать что-то более сложное, чем просто применить одну функцию? А если функция принимает не первым, а вторым аргументом данные из матрицы? В этом случае нам помогут анонимные функции (anonymous function).
Анонимные функции — это функции, которые будут использоваться один раз и без названия.
Например, мы можем посчитать общее количество знаков по строкам и столбцам без называния этой функции:
B <- matrix(c("Всем", "привет", "Я", "строковая", "матрица", "и", "такое", "тоже", "бывает"), nrow = 3)
apply(B, 1, function(x) sum(nchar(x)))[1] 18 17 8apply(B, 2, function(x) sum(nchar(x)))[1] 11 17 15Начиная с R 4.1.0 (май 2021) можно использовать сокращенный вариант написания анонимных функций с \ вместо ключевого слова function:
apply(B, 1, \(x) sum(nchar(x)))[1] 18 17 8apply(B, 2, \(x) sum(nchar(x)))[1] 11 17 15apply()ОК, с apply() разобрались. А что с остальными? Некоторые из функций семейства *apply() еще проще и не требуют индексов, например, lapply() (для применения к каждому элементу списка) и sapply() — упрощенная версия lapply(), которая пытается по возможности “упростить” результат до вектора или матрицы.
some_list <- list(some = 1:10, list = letters)
lapply(some_list, length)$some
[1] 10
$list
[1] 26sapply(some_list, length)some list
10 26 Применение sapply() к вектору приводит к тем же результатам, что и просто применить векторизованную функцию обычным способом.
sapply(1:10, sqrt) [1] 1.000000 1.414214 1.732051 2.000000 2.236068 2.449490 2.645751 2.828427
[9] 3.000000 3.162278sqrt(1:10) [1] 1.000000 1.414214 1.732051 2.000000 2.236068 2.449490 2.645751 2.828427
[9] 3.000000 3.162278Зачем вообще тогда нужен sapply(), если мы можем просто применить векторизованную функцию? Ключевое слово здесь векторизованная функция. Если функция не векторизована, то sapply() становится удобным вариантом для того, чтобы избежать итерирования с помощью циклов for. Если же у вас уже есть векторизованная функция, то лучше применять напрямую именно её: такой код будет не только более читаемым, но и в большинстве случаев более быстрым.
Можно применять функции lapply() и sapply() на датафреймах. Поскольку фактически датафрейм — это список из векторов одинаковой длины (см. Глава 4.4), то итерироваться эти функции будут по колонкам:
heroes <- read.csv("https://raw.githubusercontent.com/Pozdniakov/tidy_stats/master/data/heroes_information.csv",
na.strings = c("-", "-99", "NA", " "))
sapply(heroes, class) X name Gender Eye.color Race Hair.color
"integer" "character" "character" "character" "character" "character"
Height Publisher Skin.color Alignment Weight
"numeric" "character" "character" "character" "integer" Еще одна функция из семейства apply() — функция replicate() — самый простой способ повторить одну и ту же операцию много раз. Обычно эта функция используется при симуляции данных и моделировании. Например, давайте сделаем выборку из логнормального распределения (подробнее про распределения см. в Глава 17.2):
samp <- rlnorm(30)
hist(samp)
А теперь давайте сделаем 1000 таких выборок и из каждой возьмем среднее:
sampdist <- replicate(1000, mean(rlnorm(30)))
hist(sampdist)
Про функции для генерации случайных чисел и про визуализацию будет в следующих главах: Глава 17.2 и Глава 13 соответственно.
В заключение стоит сказать, что семейство функций apply() — это очень сильное колдунство, но в tidyverse оно практически полностью перекрывается функциями из пакета {purrr}, за исключением самого apply() и некоторых других функций, которые работают с матрицами и массивами (tidyverse с ними принципиально не дружит). Впрочем, если вы поняли логику apply(), то при желании вы легко сможете переключиться на альтернативы из пакета {purrr} (см. Глава 11.4).
Функция, которая создает другие функции, называется фабрикой функций (function factory).↩︎