Статистика делится на описательную статистику (descriptive statistics) и статистику вывода (inferential statistics). Описательная статистика пытается описать нашу выборку (sample, т.е. те данные, что у нас на руках) различными способами. Проблема в том, что описательная статистика может описать только то, что у нас есть, но не позволяет сделать выводы о генеральной совокупности (population) - это уже цель статистики вывода. Цель описательной статистики - “ужать” данные для их обобщенного понимания с помощью статистик.
Заметьте, у выборки (sample) мы считаем статистики (statistics), а у генеральной совокупности (Population) есть параметры (Parameters). Вот такая вот мнемотехника.
Статистики часто выступают в роли точечной оценки (point estimators) параметров, так что в этом легко запутаться. Например, среднее (в выборке) - это оценка среднего (в генеральной совокупности). Да, можно свихнуться. Мы это будем разбирать подробнее в следующие занятия (это действительно важно, поверьте), пока что остановимся только на описании выборки.
12.2 Типы шкал
Перед тем, как начать речь об описательных статистиках, нужно разобраться с существующими типами шкал. Типы шкал классифицируются на основании типа измеряемых данных, которые задают допустимые для данной шкалы отношения.
- Шкала наименований (номинальная шкала) — самая простая шкала, где единственное отношение между элементами — это отношения равенства и неравенства. Это любая качественная шкала, между элементами которой не могут быть установлены отношения “больше — меньше”. Это большинство группирующих переменных (экспериментальная группа, пол, политическая партия, страна), переменные с id. Еще один пример - номера на майках у футболистов.
- Шкала порядка (ранговая шкала) — шкала следующего уровня, для которой можно установить отношения “больше — меньше”, причем если B больше A, а C больше B, то и C должно быть больше A. Если это верно, то мы можем выстроить последовательность значений. Однако мы еще не можем говорить о разнице между значениями. Ответы на вопросы “Как часто вы курите?” по шкале “Никогда”, “Редко” и “Часто” являются примером ранговой шкалы. “Часто” — это чаще, чем “Редко”, “Редко” — это чаще чем “Никогда”, и, соотвественно, “Часто” — это чаще, чем “Никогда”. Но мы не можем сказать, что разница между “Часто” и “Редко” такая же, как и между “Редко” и “Никогда”. Соответственно, даже если мы обозначим “Часто”, “Редко” и “Никогда” как 3, 2 и 1 соответственно, то многого не можем сделать с этой шкалой, Например, мы не можем посчитать арифметическое среднее для такой шкалы.
- Шкала разностей (интервальная шкала) — шкала, для которой мы уже можем говорить про разницы между интервалами. Например, разница между 10 Cº и 20 Cº такая же как и между 80 Cº и 90 Cº. Для шкалы разностей уже можно сравнивать средние, но операции умножения и деления не имеют смысл, потому что ноль в шкале разностей относительный. Например, мы не можем сказать, что 20 Cº — это в два раза теплее, чем 10 Cº, потому что 0 Cº — это просто условно взятая точка — температура плавления льда.
- Шкала отношений (абсолютная шкала) — самая “полноценная” шкала, которая отличается от интервальной наличием естественного и однозначного начала координат. Например, масса в килограммах или та же температура, но в градусах Кельвина, а не Цельсия.
12.3 Квантили
В жизни мы постоянно проходим какие-нибудь тесты, получаем баллы и рано или поздно встает вопрос: ну а как оно у других? Как бы нас ни учили книжки по саморазвитию, что не стоит сравнивать себя с другими, от этого вопроса очень сложно избавиться. А иногда и вовсе не нужно.
Допустим, вы проходите профессиональный тест с задачами одинаковой сложности. Как понять, если вы решили 10 из 20 задач (допустим, что задачи одинаковой сложности), то это много или мало? Мы договорились, что задачи одинаковой сложности, но не сказали какой. Если все 20 задач очень легкие, то 10 – это мало, а если сложные – то много. В этой ситуации может быть важен относительный успех: сколько людей справились с тестом хуже вас, а сколько - лучше вас. Вот это и позволяют посчитать процентили (percentile rank) – процент значений в распределении ниже заданного значения. То есть 90ый процентиль означает, что вы справились лучше, чем 90% людей, который прошли тот же тест. То есть вы находитесь в 10% самых-самых! Поэтому настоящие понторезы должны меряться не абсолютными значениями, а процентилями.
Здесь сразу нужно оговориться, что понятие процентиля имеет несколько неоднозначностей. В английском принято разделять percentile и percentile rank. Percentile rank – это процент значений в распределении ниже заданного, то просто percentile – это само значение, ниже которого находится соответствующий процент значений. А иногда и вовсе процентилем называют сам интервал между процентильными границами. Все эти понятия взаимосвязаны, поэтому о том, в каком именно значении используется понятие “процентиль” можно догадаться из контекста. Другая неоднозначность понятия процентиля связана с тем, в какой процентиль относить пограничные значения. Эта проблема породила целых девять различных подходов к расчету процентилей! Однако если шкала континуальная и имеет достаточно много значений, то разницы между этими подходами не будет.
Можно делить значения не на 100 интервалов, а на меньшее количество. Например, на 4. Для этого нам нужно три точки: одна отделяет 25% наименьших значений, вторая отделяет нижнее 50% от верхних 50% (то есть это медиана!), третья – верхние 25% отнижних 75%. Эти точки и интервалы, разделяемые ими, называются квартилями.
Кроме процентилей и квартилей есть еще децили, квинтили, секстили, септили и что угодно -тили, хотя и используются они гораздо реже. Общее название для всех них – квантили.
Не пугайтесь значка \(\sum\limits_{i=1}^{n}\) – он означает сумму от \(i = 1\) до \(n\). Что-то вроде цикла for!
Практика: функция my_mean()
В качестве упражнения попробуйте самостоятельно превратить эту формулу в функцию mymean() c помощью sum() и length(). Можете убирать NA по дефолту! Сравните с результатом функции mean().
mean(weight)
[1] 112.2525
12.4.2 Медиана
Представьте себе, что мы считаем среднюю зарплату сотрудников завода. Большинство рабочих получает 30000-40000 рублей в месяц, а директор завода получает 2 миллиона в месяц. Средняя зарплата на заводе в итоге равна 70000 рублей. Никакого подвоха: мы просто применили арифметическое среднее. Что спросили, то и получили, никаких манипуляций с цифрами! На деле же нас интересует обычно не средняя зарплата, а сколько получает средний сотрудник. Не директор, не главный мастер, но и не новичок и не алкоголик Василий, который постоянно опаздывает и плохо справляется с работой. Простой рабочий Иван, нормальный парень. Сколько зарабатывают такие как он? Для ответа на этот вопрос используют не арифметическое среднее, а медиану.
Медиана (median) - это середина распределения. Представим, что мы расставили значения по порядку (от меньшего к большему) и взяли значение посередине.
Если у нас четное количество значений, то берется среднее значение между теми двумя, что по середине.
Для расчета медианы есть функция median():
median(weight)
[1] 81
Разница медианы со средним существенная. Это значит, что распределение довольно асимметричное.
Представьте себе, что кто-то говорит про среднюю зарплату в Москве. Но ведь эта средняя зарплата становится гораздо больше, если учитывать относительно небольшое количество мультимиллионеров и миллиардеров! А вот медианная зарплата будет гораздо меньше.
Представьте себе, что в среде супергероев появляется кто-то с массой 9000 килограммов! Тогда среднее сильно изменится:
mean(c(weight, 9000))
[1] 130.1714
А вот медиана останется той же.
median(c(weight, 9000))
[1] 81
Таким образом, экстремально большие или маленькие значения оказывают сильное влияние на арифметическое среднее, но не на медиану. Поэтому медиана считается более “робастной” оценкой, т.е. более устойчивой к выбросам и крайним значениям.
12.4.3 Усеченное среднее (trimmed mean)
Если про среднее и медиану слышали все, то про усеченное (тримленное) среднее известно гораздо меньше. Тем не менее, на практике это довольно удобная штука, потому что представляет собой некий компромисс между арифметическим средним и медианой.
В усеченном среднем значения ранжируются так же, как и для медианы, но отбрасывается только какой-то процент крайних значений. Усеченное среднее можно посчитать с помощью обычной функции mean(), поставив нужное значение параметра trim =:
mean(weight, trim =0.1)
[1] 89.56423
trim = 0.1 означает, что мы отбросили 10% слева и 10% справа. trim может принимать значения от 0 до 0.5. Что будет, если trim = 0?
mean(weight, trim =0)
[1] 112.2525
Обычное арифметическое среднее! А если trim = 0.5?
mean(weight, trim =0.5)
[1] 81
Медиана!
12.4.4 Мода
Мода(mode) - это самое частое значение. Обычно используется для номинальных переменных, для континуальных данных мода неприменима. Что интересно, в R нет встроенной функции для подсчета моды. Обычно она и не нужна: мы можем посчитать таблицу частот и даже проранжировать ее (и мы уже умеем это делать разными способами).
heroes %>%count(Gender, sort =TRUE)
# A tibble: 3 × 2
Gender n
<chr> <int>
1 Male 505
2 Female 200
3 <NA> 29
Можете попробовать написать свою функцию для моды!
12.5 Меры рассеяния
Начинающий статистик пытался перейти в брод реку, средняя глубина которой 1 метр. И утонул.
В чем была его ошибка? Он не учитывал разброс значений глубины!
Мер центральной тенденции недостаточно, чтобы описать выборку. Необходимо знать ее вариабельность.
12.5.1 Размах
Самое очевидное - посчитать размах(range), то есть разницу между минимальным и максимальным значением. В R есть функция для вывода максимального и минимального значений:
range(weight)
[1] 2 900
Осталось посчитать разницу между ними:
diff(range(weight))
[1] 898
Естественно, крайние значения очень сильно влияют на этот размах, поэтому на практике он не очень-то используется.
12.5.2 Дисперсия
Дисперсия(variance) вычисляется по следующей формуле:
Естественно, в R уже есть готовая функция var(). Но, заметьте, ее результат немного отличается от нашего:
myvar(weight)
[1] 10825.55
var(weight)
[1] 10847.46
Дело в том, что встроенная функция var() делит не на \(n\), а на \(n-1\). Это связано с тем, что эта функция пытается оценить дисперсию в генеральной совокупности, т.е. относится уже к статистике вывода. Про это мы будем говорить в дальнейших занятиях, сейчас нам нужно только отметить то, что здесь есть небольшое различие.
12.5.3 Стандартное отклонение
Если вы заметили, значение дисперсии очень большое. Чтобы вернуться к единицам измерения, соответствующих нашим данным используется корень из дисперсии, то есть стандартное отклонение(standard deviation):
На основе арифметического среднего и стандартного отклонения вычисляются \(z\)-оценки (\(z\)-scores) по простой формуле:
\[z_i = \frac{x_i - \overline{x}}{s}\]
Проще говоря, \(z\)-оценки – это центрированные вокруг нуля значения в единицах стандартного отклонения. Это может понадобится в случае необходимости свести разные шкалы как одной размерности (со средним равным нулю и стандартным отклонением равным одному). \(z\)-преобразование является стандартной процедурой для многих методов, например, для анализа главных компонент (см. Глава 24.2).
Для проведения \(z\)-преобразования можно воспользоваться встроенной функцией scale(), однако она возвращает \(z\)-оценки в довольно неочевидном формате: матрицу (см. Глава 4.1) с атрибутами (см. Глава 4.5) "scaled:center" (среднее изначальной шкалы) и "scaled:scale" (стандартное отклонение изначальной шкалы). Впрочем, функцию для \(z\)-преобразования легко написать самостоятельно:
Поскольку стандартное отклонение не устойчиво к выбросам, то иногда используют его альтернативу, которая устойчива к выбросам (особенно если эти выбросы нам как раз и нужно удалить) - медианное абсолютное отклонение (median absolute deviation):
\[mad= median(|x_{i} - median(x)|)\]
Для этого есть функция mad():
mad(weight)
[1] 32.6172
12.5.5 Межквартильный размах
Другой вариант робастной оценки вариабельности данных является межквартильный размах(interquartile range, IQR). Это разница между третьим и первым квартилем1 - значением, которое больше 75% значений в выборке, и значением, которое больше 25% значений в выборке.
IQR(weight)
[1] 47
Ну а второй квартиль - это медиана!
12.6 Асимметрия и эксцесс
12.6.1 Асимметрия
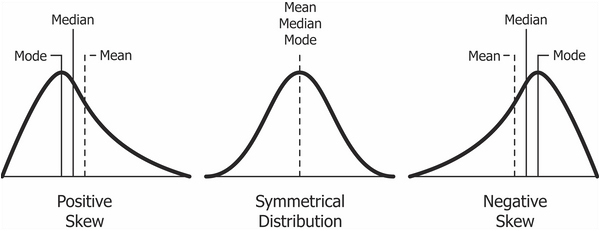
Асимметрия (skewness) измеряет симметричность распределения. Положительный показатель асимметрии(“Right-skewed” или positive skewness) означает, что хвосты с правой части распределения длиннее. Негативный показатель асимметрии (“Left-skewed” или negative skewness) означает, что левый хвост длиннее. Нулевой показатель асимметрии означает симметричное распределение.
В целом, распределения с положительным показателем асимметрии на практике встречаются чаще, чем с отрицательным: очень часто мы сталкиваемся со шкалами, которые ограничены снизу, но не ограничены сверху.
В когнитивистике положительная асимметрия встречается очень часто. Например, время реакции: оно ограничено снизу 0 мс (а по факту не меньше 100 мс – быстрее сигнал не успеет по нервной системе пройти до пальцев), а вот с другой стороны оно никак не ограничено. Испытуемый может на полчаса перед монитором затупить, ага.
Если мы анализируем размеры индивидуальные доходы, то они не могут быть меньше 0, но могут быть невероятно большими для относительно небольшого количества миллионеров и миллиардеров. Доходы остальных людей находятся в относительно небольшом диапазоне (который гораздо ближе к нулю, чем к доходам миллиардеров)
12.6.2 Эксцесс
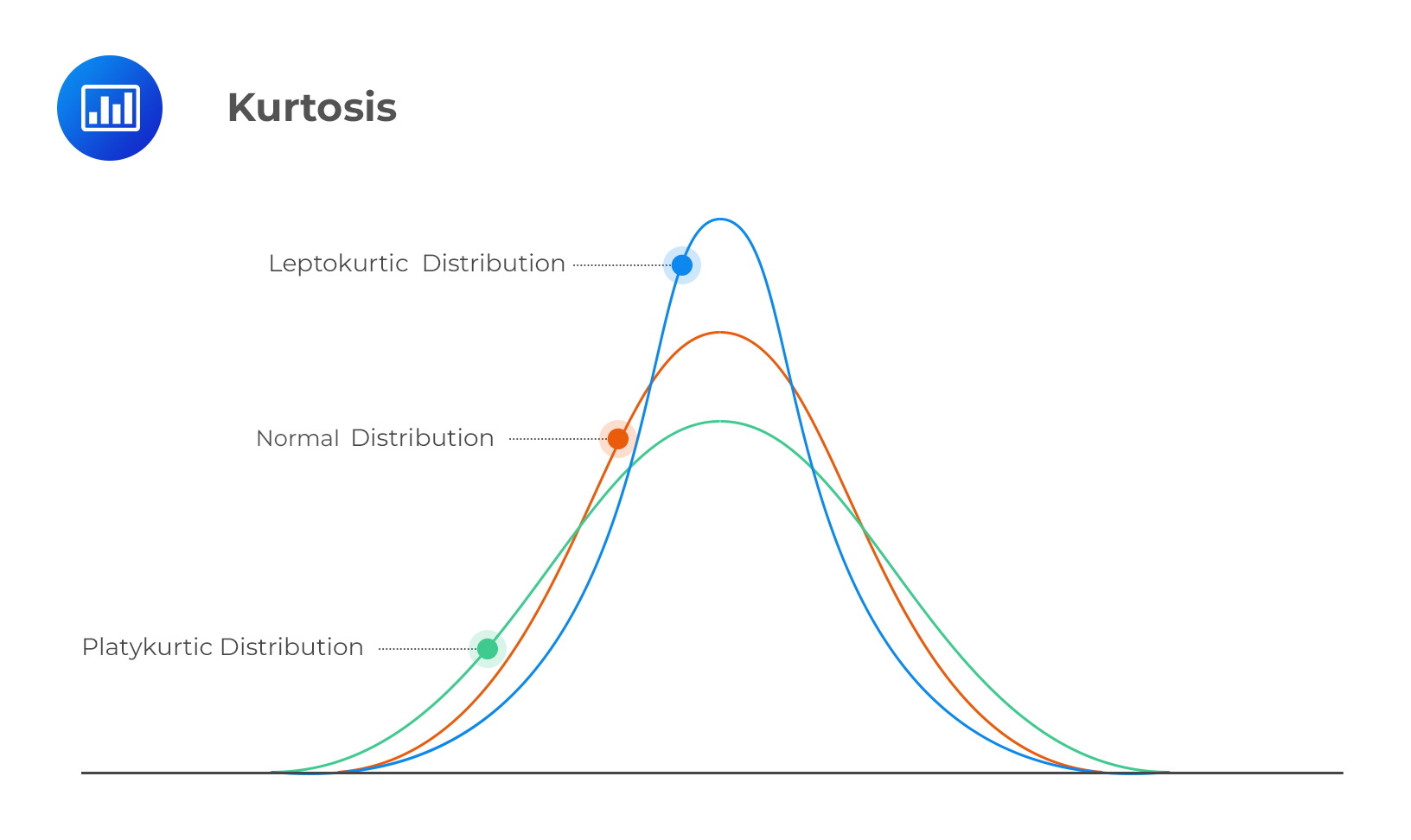
Эксцесс (kurtosis) - это мера “вытянутости” распределения:
Положительные показатели эксцесса означают “вытянутое” распределение, а отрицательные - “плоское”.
12.6.3 Ассиметрия и эксцесс в R
К сожалению, в базовом R нет функций для асимметрии и эксцесса. Зато есть замечательный пакет {psych} (да-да, специально для психологов).
install.packages("psych")
library("psych")
Attaching package: 'psych'
The following objects are masked from 'package:ggplot2':
%+%, alpha
В нем есть функции skew() и kurtosi():
skew(weight)
[1] 3.874557
kurtosi(weight)
[1] 19.45699
Асимметрия положительная, это значит что распределение выборки асимметричное, хвосты с правой части длиннее. Эксцесс значительно выше нуля - значит распределение довольно “вытянутое”.
12.7 А теперь все вместе!
В базовом R есть функция summary(), которая позволяет получить сразу неплохой набор описательных статистик.
summary(weight)
Min. 1st Qu. Median Mean 3rd Qu. Max.
2.0 61.0 81.0 112.3 108.0 900.0
Функция summary() - это универсальная (generic) функция (см. Глава 4.5). Это означает, что вы можете ее применять для разных объектов и получать разные результаты. Попробуйте применить ее к векторам с разными типами данных и даже к датафреймам. Посмотрите, что получится.
В пакете psych есть еще и замечательная функция describe(), которая даст вам еще больше статистик, включая ассиметрию и куртозис:
psych::describe(weight)
vars n mean sd median trimmed mad min max range skew kurtosis se
X1 1 495 112.25 104.15 81 89.56 32.62 2 900 898 3.87 19.46 4.68
Даже усеченное (trimmed) среднее есть (с trim = 0.1)! Всё кроме se мы уже знаем. А про этот se узнаем немного позже (см. Глава 17.6).
Эта функция хорошо работает в сочетании с group_by():
# A tibble: 3 × 14
Gender vars n mean sd median trimmed mad min max range skew
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Female 1 142 78.8 77.0 58 60.9 7.41 41 630 589 4.97
2 Male 1 339 126. 111. 90 103. 23.7 2 900 898 3.76
3 <NA> 1 14 129. 107. 94 115. 43.0 39 383 344 1.55
# ℹ 2 more variables: kurtosis <dbl>, se <dbl>
Другой интересный пакет для получения описательных статистик для всего датафрейма — {skimr}.
install.packages("skimr")
Его основная функция — skim(), выводит в консоли симпатичную сводную таблицу:
skimr::skim(heroes)
Data summary
Name
heroes
Number of rows
734
Number of columns
11
_______________________
Column type frequency:
character
8
numeric
3
________________________
Group variables
None
Variable type: character
skim_variable
n_missing
complete_rate
min
max
empty
n_unique
whitespace
name
0
1.00
1
25
0
715
0
Gender
29
0.96
4
6
0
2
0
Eye color
172
0.77
3
23
0
22
0
Race
304
0.59
5
18
0
61
0
Hair color
172
0.77
3
16
0
29
0
Publisher
0
1.00
0
17
15
25
0
Skin color
662
0.10
3
14
0
16
0
Alignment
7
0.99
3
7
0
3
0
Variable type: numeric
skim_variable
n_missing
complete_rate
mean
sd
p0
p25
p50
p75
p100
hist
…1
0
1.00
366.50
212.03
0.0
183.25
366.5
549.75
733
▇▇▇▇▇
Height
217
0.70
186.73
59.25
15.2
173.00
183.0
191.00
975
▇▁▁▁▁
Weight
239
0.67
112.25
104.15
2.0
61.00
81.0
108.00
900
▇▁▁▁▁
В зависимости от типа данных колонки функция skim() показывает различные статистики. Для числовых колонок мы можем увидеть количество и долю пропущенных значений, среднее и стандартное отклонение. А еще мы видим некие p0, p25, p50, p75 и p100. Это процентили! И совсем не с потолка взятые:
p0 – минимальное значение,
p25 – первый квартиль (Q1),
p50 – второй квартиль (Q2), т.е. медиана,
p75 – третий квартиль (Q3),
p100 – максимальное значение.
Ну и вишенкой на торте выступает маленькая гистограмма (см. для каждой колонки!
Кроме того, skimr адаптирован под tidyverse. В нем можно выбирать колонки с помощью tidyselect (Глава 10.6.2) прямо внутри функции skim().
heroes %>% skimr::skim(ends_with("color"))
Data summary
Name
Piped data
Number of rows
734
Number of columns
11
_______________________
Column type frequency:
character
3
________________________
Group variables
None
Variable type: character
skim_variable
n_missing
complete_rate
min
max
empty
n_unique
whitespace
Eye color
172
0.77
3
23
0
22
0
Hair color
172
0.77
3
16
0
29
0
Skin color
662
0.10
3
14
0
16
0
А еще можно сочетать с группировкой с помощью group_by().
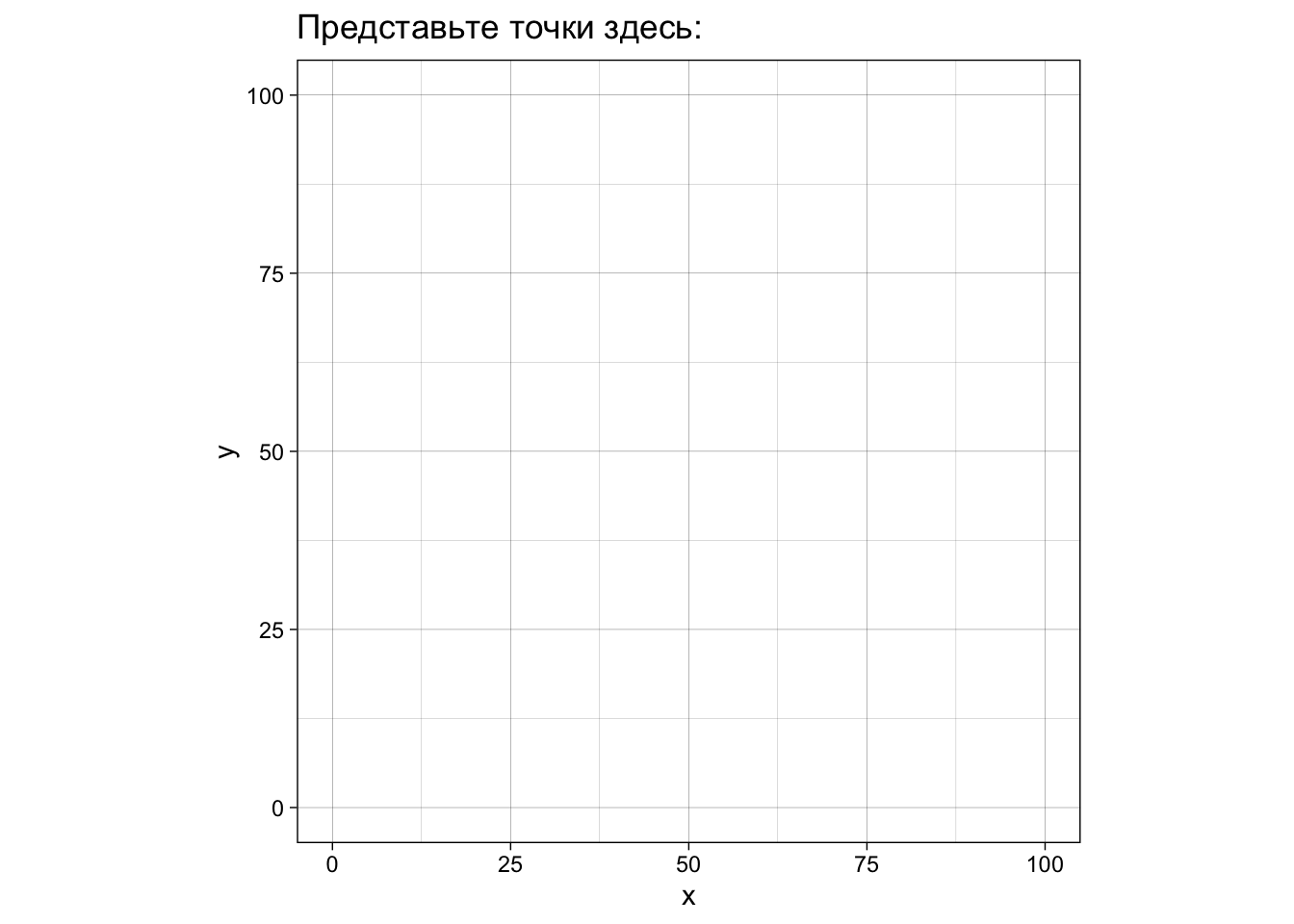
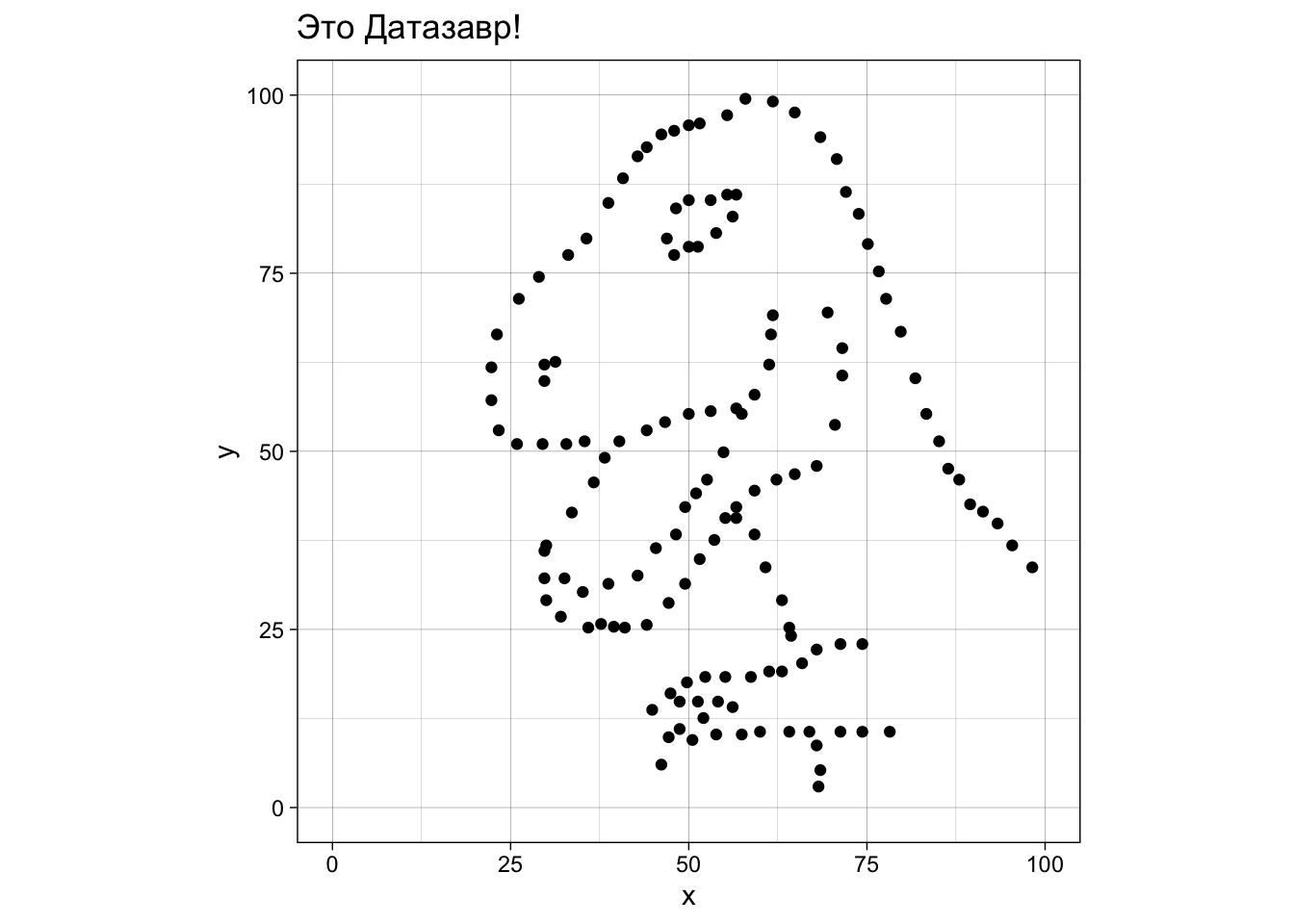
Надеюсь, вы уже понимаете, как это интерпретировать - два столбца с 142 числами каждый. Представьте себе, как выглядят эти точки на плоскости, если каждая строчка означают координаты одной точки по осям x и y (это называется диаграмма рассеяния, точечная диаграмма или scatterplot).
Применим разные функции, которые мы выучили:
mean(xxx$x)
[1] 54.26327
mean(xxx$y)
[1] 47.83225
median(xxx$x)
[1] 53.3333
median(xxx$y)
[1] 46.0256
Средние и медианы примерно одинаковые, при этом по х они около 53-54, а по у - примерно 46-47. Попытайтесь представить это. Идем дальше:
sd(xxx$x)
[1] 16.76514
sd(xxx$y)
[1] 26.9354
Похоже, разброс по у несколько больше, верно?
skew(xxx$x)
[1] 0.2807568
skew(xxx$y)
[1] 0.2472603
kurtosi(xxx$x)
[1] -0.2854912
kurtosi(xxx$y)
[1] -1.063552
Похоже, оба распределения немного право-ассиметричны и довольно “плоские”.
Давайте еще посчитаем коэффициент корреляции (correlation coefficient). Мы про него будем говорить позже гораздо подробнее (Глава 20.2). Пока что нам нужно знать, что коэффициент корреляции говорит о линейной связи двух переменных. Если коэффициент корреляции положительный (максимум равен 1), то чем больше х, тем больше у. Если отрицательный (минимум равен -1), то чем больше х, тем меньше у. Если же коэффициент корреляции равен нулю, то такая линейная зависимость отсутствует.
cor(xxx$x, xxx$y)
[1] -0.06447185
Коэффициент корреляции очень близка к нулю (делайте выводы и представляйте).
Давайте напоследок воспользуемся функцией describe() из psych:
psych::describe(xxx)
vars n mean sd median trimmed mad min max range skew kurtosis
x 1 142 54.26 16.77 53.33 53.69 15.97 22.31 98.21 75.90 0.28 -0.29
y 2 142 47.83 26.94 46.03 46.90 30.79 2.95 99.49 96.54 0.25 -1.06
se
x 1.41
y 2.26
skimr::skim(xxx)
Data summary
Name
xxx
Number of rows
142
Number of columns
2
_______________________
Column type frequency:
numeric
2
________________________
Group variables
None
Variable type: numeric
skim_variable
n_missing
complete_rate
mean
sd
p0
p25
p50
p75
p100
hist
x
0
1
54.26
16.77
22.31
44.10
53.33
64.74
98.21
▅▇▇▅▂
y
0
1
47.83
26.94
2.95
25.29
46.03
68.53
99.49
▇▇▇▅▆
Готовы узнать, как выглядят эти данные на самом деле?!
Жмите сюда если готовы!
Из этого можно сделать важный вывод: не стоит слепо доверять описательным статистикам. Нужно визуализировать данные, иначе можно попасть в такую ситуацию в реальности. По словам знаменитого статитстика Джона Тьюки, величайшая ценность картинки в том, что она заставляет нас заметить то, что мы не ожидали заметить. Поэтому графики — это не просто метод коммуникации — представления ваших результатов сообществу в понятном виде (хотя и это, конечно, тоже), но и сам по себе очень важный метод анализа данных.
Квартиль — это частный пример квантиля. Другой известный квантиль — процентиль. Процентили часто используют для сравнения значения с другими значениями. Например, 63ий процентиль означает, что данное значение больше 63% значений в выборке.↩︎