Встроенные возможности для визуализации в R довольно обширны, но дополнительные пакеты значительно ее расширяют. Среди этих пакетов есть один, который занимает совершенно особенное место — {ggplot2}.
{ggplot2} — это не просто пакет, который рисует красивые графики. Красивые графики можно рисовать и в базовом R. Чтобы понять, почему пакет {ggplot2} занимает особенное место среди пакетов для визуализации (и не только среди пакетов для R, а вообще!), нужно расшифровать gg в его названии. gg означает грамматику графики (Grammar of Graphics), язык для описания графиков, изложенный в одноименной книге Леланда Уилкинсона (Wilkinson, 2005).
Грамматика графики позволяет описывать графики не в терминах типологии (вот есть пайчарт, есть барплот, есть гистограмма, а есть ящик с усами), а с помощью специального разработанного языка. Этот язык позволяет с помощью грамматики и небольшого количества “слов” языка описывать и создавать практически любые графики и даже придумывать новые! Это дает огромную свободу в создании именно той визуализации, что необходима для текущей задачи.
Хэдли Уикхэм (да, снова он) немного дополнил идею грамматики графики в статье “A Layered Grammar of Graphics” (Wickham, 2010), которую сопроводил пакетом {ggplot2} с реализацией идей Уилкинсона и своих.
14.2 Основы грамматики графики
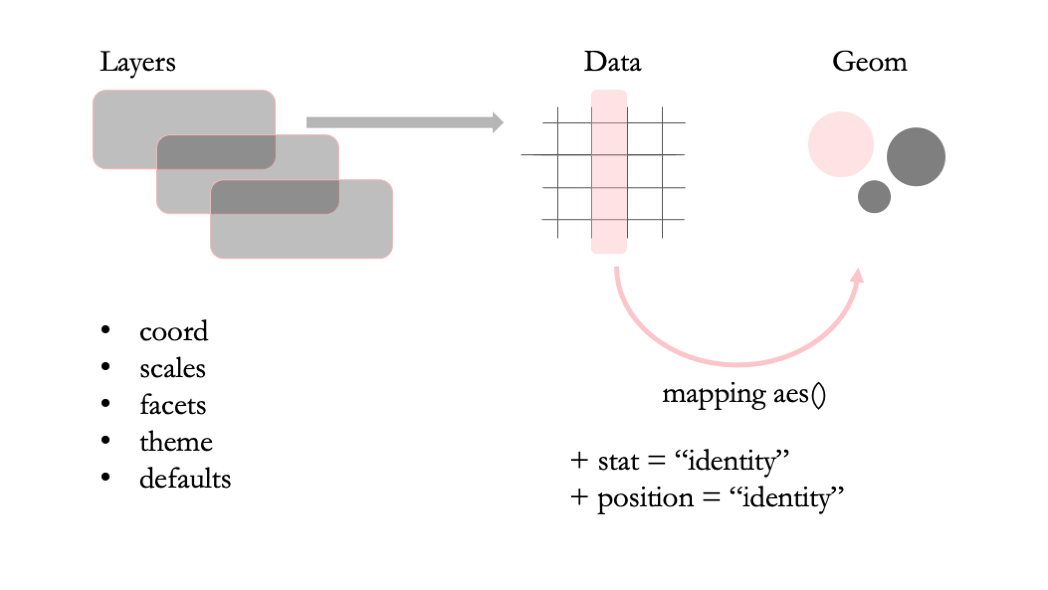
Каждый график состоит из одного или нескольких слоев (layers). Если слоев несколько, то они располагаются один над другим, при этом верхние слои “перекрывают” нижние, примерно как это происходит в программах вроде Adobe Photoshop. У каждого слоя есть три обязательных элемента: данные (data), геом (geom), эстетики (aesthetics); и два вспомогательных: статистические трансформации (stat). и регулировка положения (position adjustment).
Схема слоёв грамматики графики: данные, геом, эстетики, статистика, регулировка положения
Данные (data). Собственно, сами данные в виде датафрейма, используемые в данном слое.
Геом (geom). Геом — это сокращение от “геометрический объект”. Собственно, в какой геометрический объект мы собираемся превращать данные. Например, в точки, прямоугольники или линии.
Отображение (mapping). Эстетические отображения или просто эстетики (aesthetics) — это набор правил, как различные переменные превращаются в визуальные особенности геометрии. Без эстетик остается непонятно, какие именно колонки в используемом датафрейме превращаются в различные особенности геомов: позицию, размер, цвет и т.д. У каждой геометрии свой набор эстетик, но многие из них совпадают у разных геомов, например, x, y, colour, fill, size. Без некоторых эстетик геом не будет работать. Например, геометрия в виде точек не будет работать без двух координат этих точек (x и y). Другие эстетики необязательны и имеют значения по умолчанию. Например, по умолчанию точки будут черными, но можно сделать их цвет зависимым от выбранной колонки в датафрейме с помощью эстетики colour.
Статистические трансформации (stat). Название используемой статистической трансформации (или просто — статистики). Да, статистические трансформации можно делать прямо внутри {ggplot2}! Это дает дополнительную свободу в выборе инструментов, потому что обычно те же статистические трансформации можно сделать вне {ggplot2} в процессе препроцессинга. Формально, статистические трансформации — это обязательный элемент геома, но если вы не хотите преобразовывать данные, то можете выбрать “identity” преобразование, которое оставляет все как есть. В {ggplot2} у каждого геома есть статистика по умолчанию, а у каждой статистики — свой геом по умолчанию. И не всегда статистика по умолчанию — это “identity” статистика. Например, для барплота (geom_bar()) используется статистика “count” 1, которая считает частоты, ведь именно частоты затем трансформируются в высоту барплотов.
Регулировка положения (position adjustment). Регулировка положения — это небольшое улучшение позиции геометрий для части элементов. Например, можно добавить немного случайного шума (“jitter”) в позицию точек, чтобы они не перекрывали друг друга. Или “раздвинуть” (“dodge”) два барплота, чтобы один не загораживал другой. Как и в случае со статистическими трансформациями, в большинстве случаев значение по умолчанию — “identity”.
Кроме слоев, у графика есть:
Координатная система (coord). Если мы задали координаты, то нам нужно задать и координатную плоскость, верно? Конечно, в большинстве случаев используется декартова система координат (Cartesian coordinate system)2, т.е. стандартная прямоугольная система координат, но можно использовать и другие, например, полярную систему координат или картографическую проекцию.
Шкалы (scales). Шкалы задают то, как именно значения превращаются в эстетики. Например, если мы задали, что разные значения в колонке будут влиять на цвет точки, то какая именно палитра будет использоваться? В какие конкретно цвета будут превращаться числовые, логические или строковые значения в колонке? В {ggplot2} есть правила по умолчанию для всех эстетик, и они отличные, но самостоятельная настройка шкал может значительно улучшить график.
Фасетки (facets). Фасетки — это одно из нововведений Уикхэма в грамматику графики. Фасетки позволяют разбить график на множество похожих, задав переменную, по которой график будет разделен. Это очень напоминает использование группировки с помощью group_by().
Тема (theme). Тема — это зрительное оформление “подложки” графика, не относящийся к содержанию графика: размер шрифта, цвет фона, размер и цвет линий на фоне и т.д. и т.п. В {ggplot2} есть несколько встроенных тем, а также есть множество пакетов, которые добавляют дополнительные темы. Кроме того, их можно настраивать самостоятельно!
Значения по умолчанию (defaults). Если в графике используется несколько слоев, то часто все они используют одни и те же данные и эстетики. Можно задать данные и эстетики по умолчанию для всего графика, чтобы не повторять код.
14.3 Пример №0: пайчарт с распределением по полу
Сейчас мы попробуем сделать простой пример в {ggplot2}, похожий на пример, который использует в своей книге Леланд Уилкинсон, чтобы показать мощь грамматики графики (Wilkinson, 2005). Приготовьтесь, этот пример перевернет ваши представления о графиках!
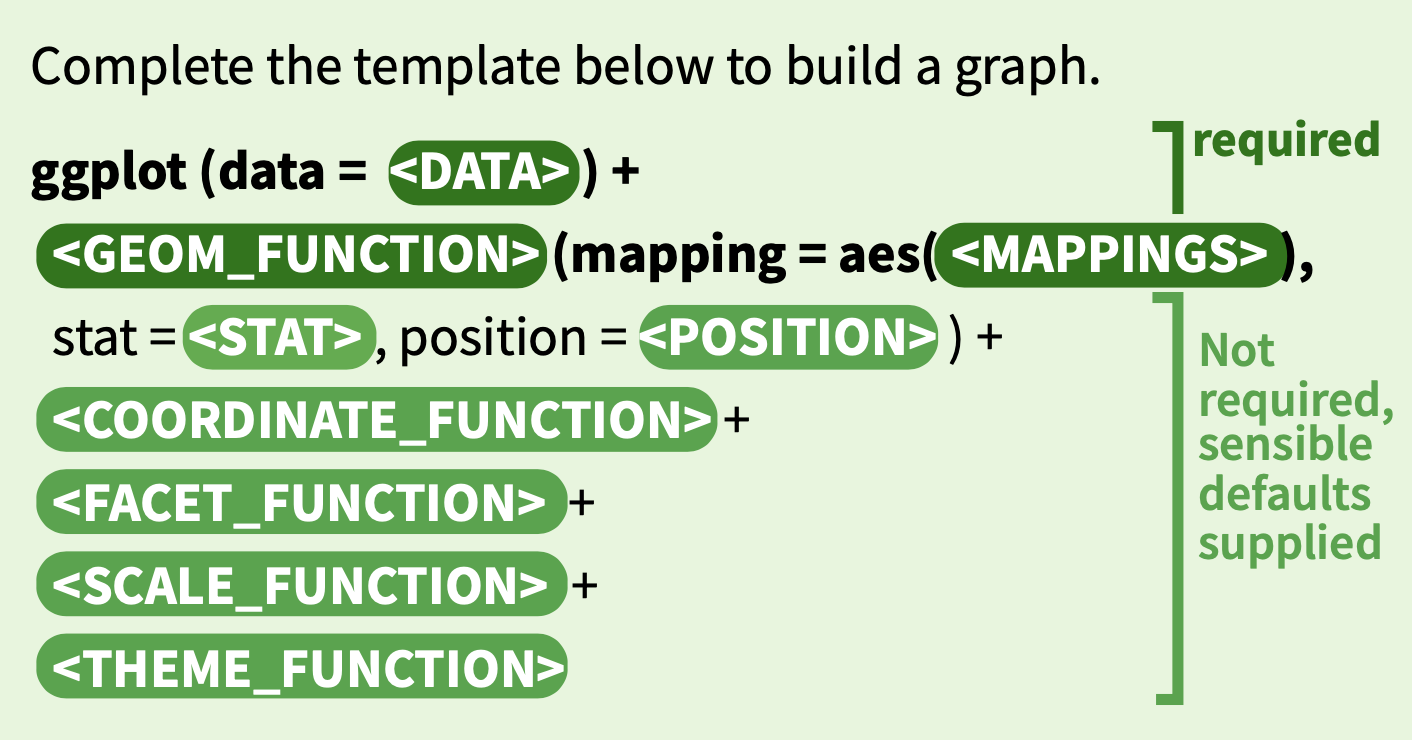
Но сначала взглянем на структуру кода в ggplot().
Структура кода ggplot(): данные, эстетики и геомы, соединённые через +
Как видно, код чем-то напоминает стандартный код tidyverse, но с + вместо пайпов. Когда был написан {ggplot2}, Хэдли Уикхэм еще не знал про %>% из {magrittr}, хотя по смыслу + означает примерно то же самое.
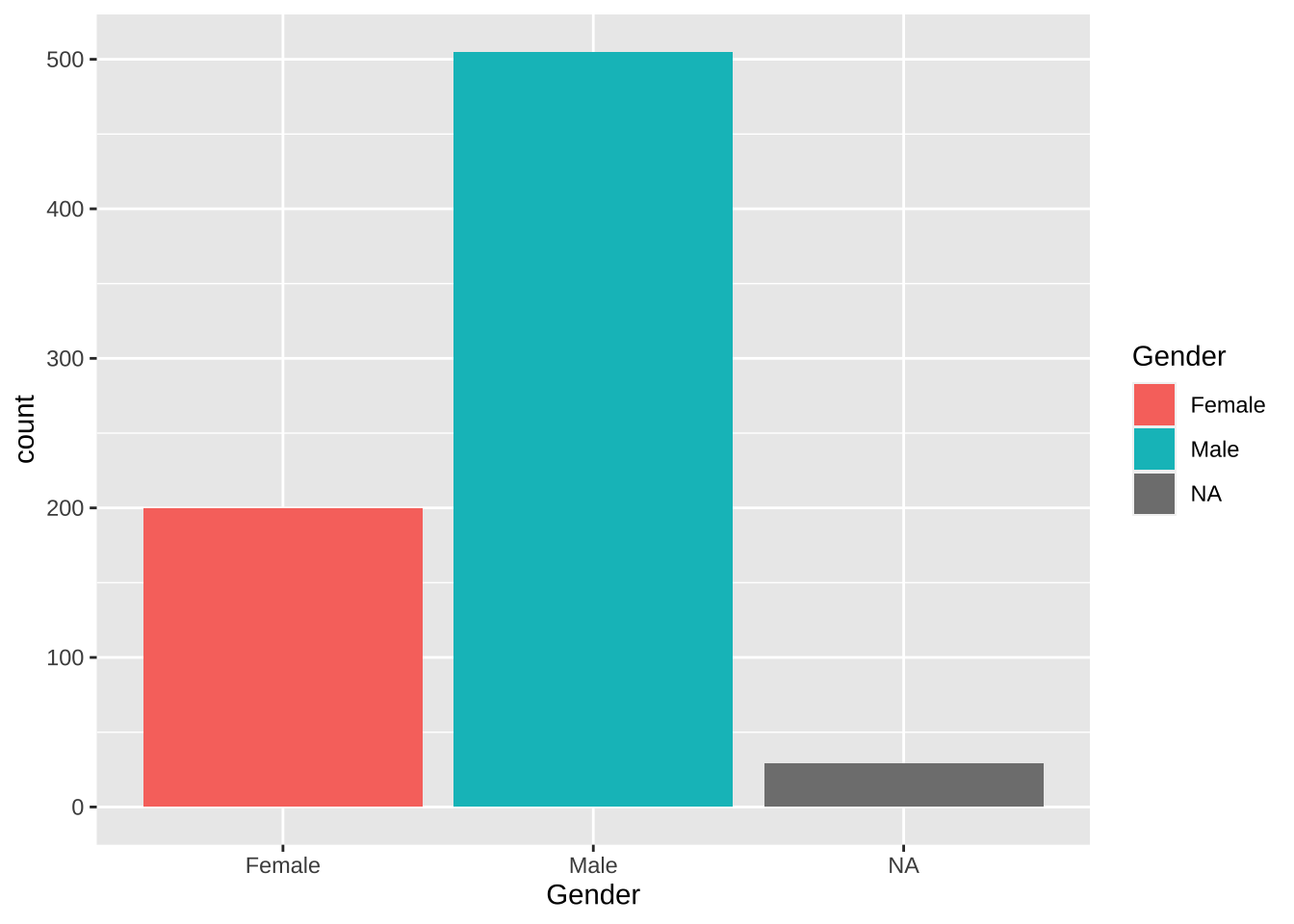
Возьмем geom_bar() для отрисовки барплота. В качестве эстетик поставим x = Gender и fill = Gender. Поскольку это эстетики, они обозначаются внутри параметра mapping = aes() или просто внутри функции aes(). По умолчанию, geom_bar() имеет статистику “count”, что нас полностью устраивает: geom_bar() сам посчитает таблицу частот и использует значения Gender для обозначения позиций и заливки, а посчитанные частоты будет использовать для задания высоты столбцов.
ggplot(data = heroes) +geom_bar(aes(x = Gender, fill = Gender))
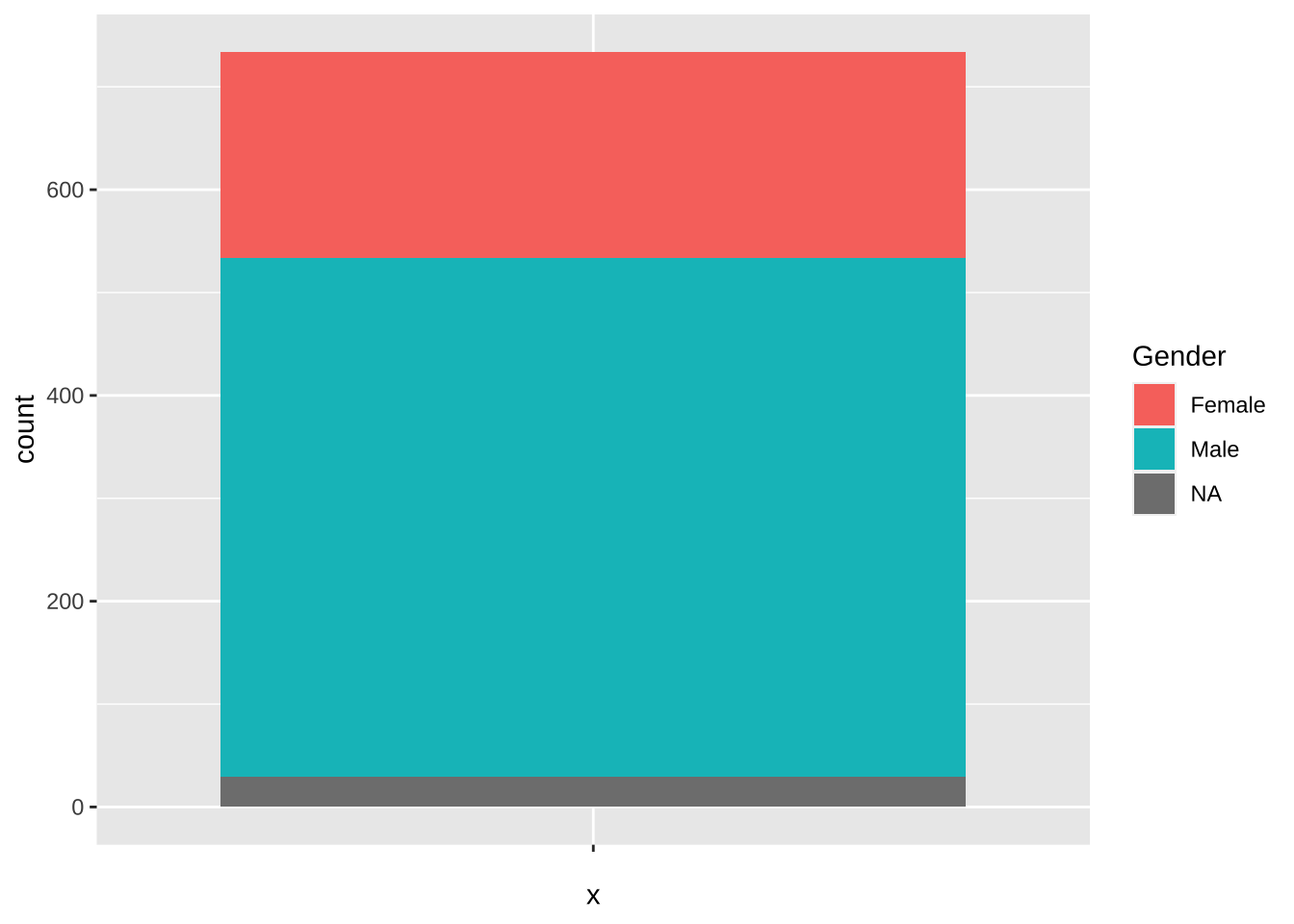
Сейчас мы сделаем один хитрый трюк: поставим значение эстетики x = "", чтобы собрать все столбики в один.
ggplot(data = heroes) +geom_bar(aes(x ="", fill = Gender))
Получилось что-то не очень симпатичное, но вполне осмысленное: доли столбца обозначают относительную частоту.
Можно настроить общие параметры геома, не зависящие от данных. Это нужно делать вне функции aes(), но внутри функции для геома.
А теперь внимание! Подумайте, какого действия нам не хватает, чтобы из имеющегося графика получить пайчарт?
ggplot(data = heroes) +geom_bar(aes(x ="", fill = Gender)) +coord_polar(theta ="y")
Нам нужно было всего лишь поменять систему координат с декартовой на полярную (круговую)! Иначе говоря, пайчарт — это барплот в полярной системе координат.
Именно в этом основная сила грамматики графики и ее реализации в {ggplot2} — вместо того, чтобы описывать и рисовать огромное количество типов графиков, можно описать практически любой график через небольшое количество элементарных элементов и правила их соединения.
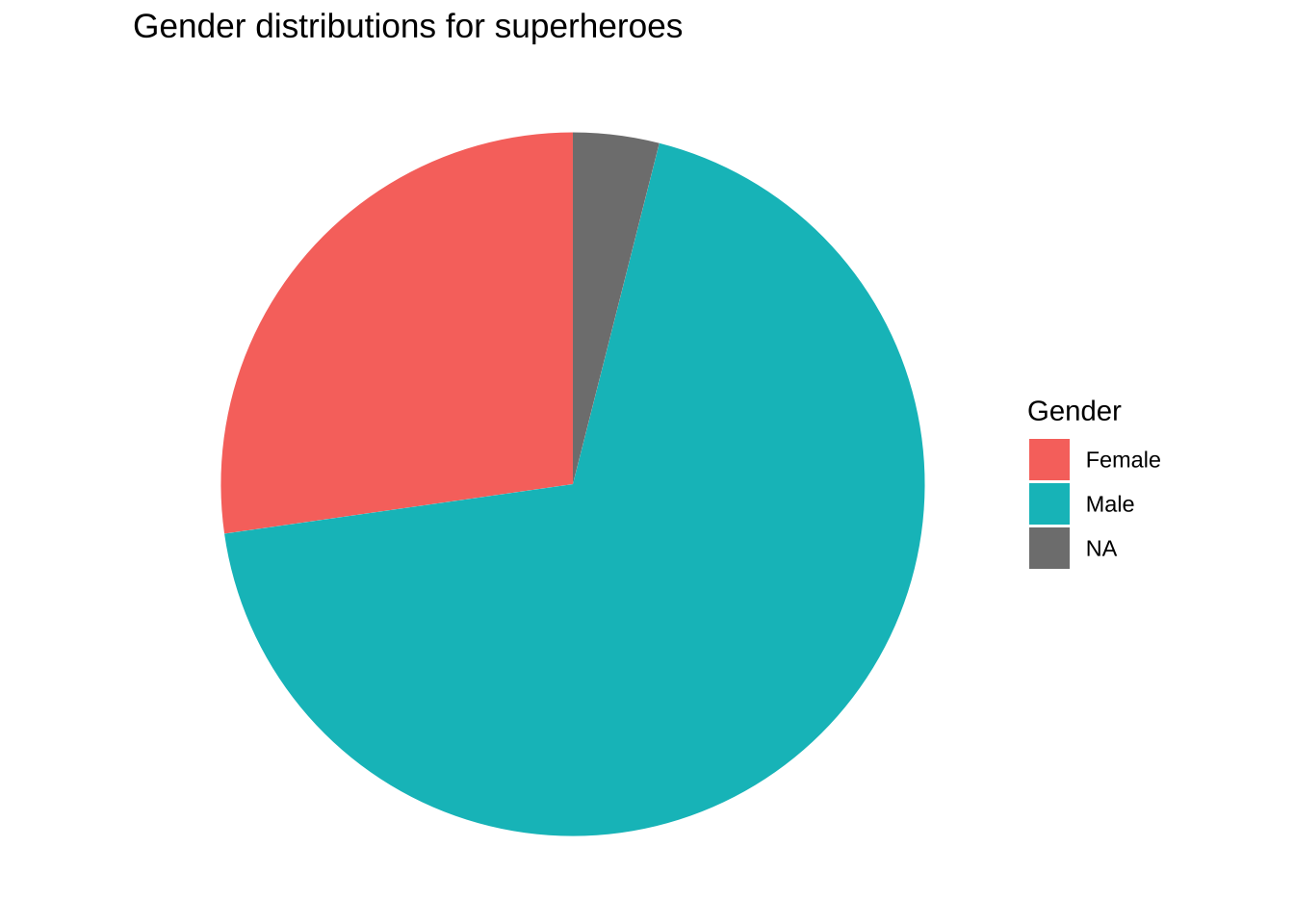
Получившийся пайчарт осталось подретушировать, убрав все лишние элементы подложки с помощью самой минималистичной темы theme_void() и добавив название графика:
ggplot(data = heroes) +geom_bar(aes(x ="", fill = Gender)) +coord_polar(theta ="y") +theme_void() +labs(title ="Gender distributions for superheroes")
Это был интересный, но немного шуточный пример. Все-таки пайчарт — это довольно спорный способ визуализировать данные, вызывающий много вполне справедливой критики. Поэтому сейчас мы перейдем к гораздо более реалистичному примеру.
14.4 Пример №1: мета-анализ образования и интеллекта
Для этого примера мы возьмем мета-анализ связи количества лет обучения и интеллекта: “How Much Does Education Improve Intelligence? A Meta-Analysis”(Ritchie & Tucker-Drob, 2018). Мета-анализ — это группа статистических методов, которые позволяют объединить результаты нескольких исследований с похожим планом исследованием и тематикой, чтобы посчитать средний эффект между несколькими статьями сразу.
Данные и скрипт для анализа данных в этой статье находятся в открытом доступе на OSF.
Существует положительная корреляция между количеством лет, который человек потратил на обучение, и интеллектом. Это может объясняться по-разному: как то, что обучение повышает интеллект, и как то, что люди с высоким интеллекте стремятся получать больше образования. Напрямую в эксперименте это проверить нельзя, поэтому есть несколько квази-экспериментальных планов, которые косвенно указывают на верность той или иной гипотезы. Например, если в стране изменилось количество лет обязательного школьного образования, то повлияло ли это на интеллект целого поколения? Или всё-таки дело в Моргенштерне
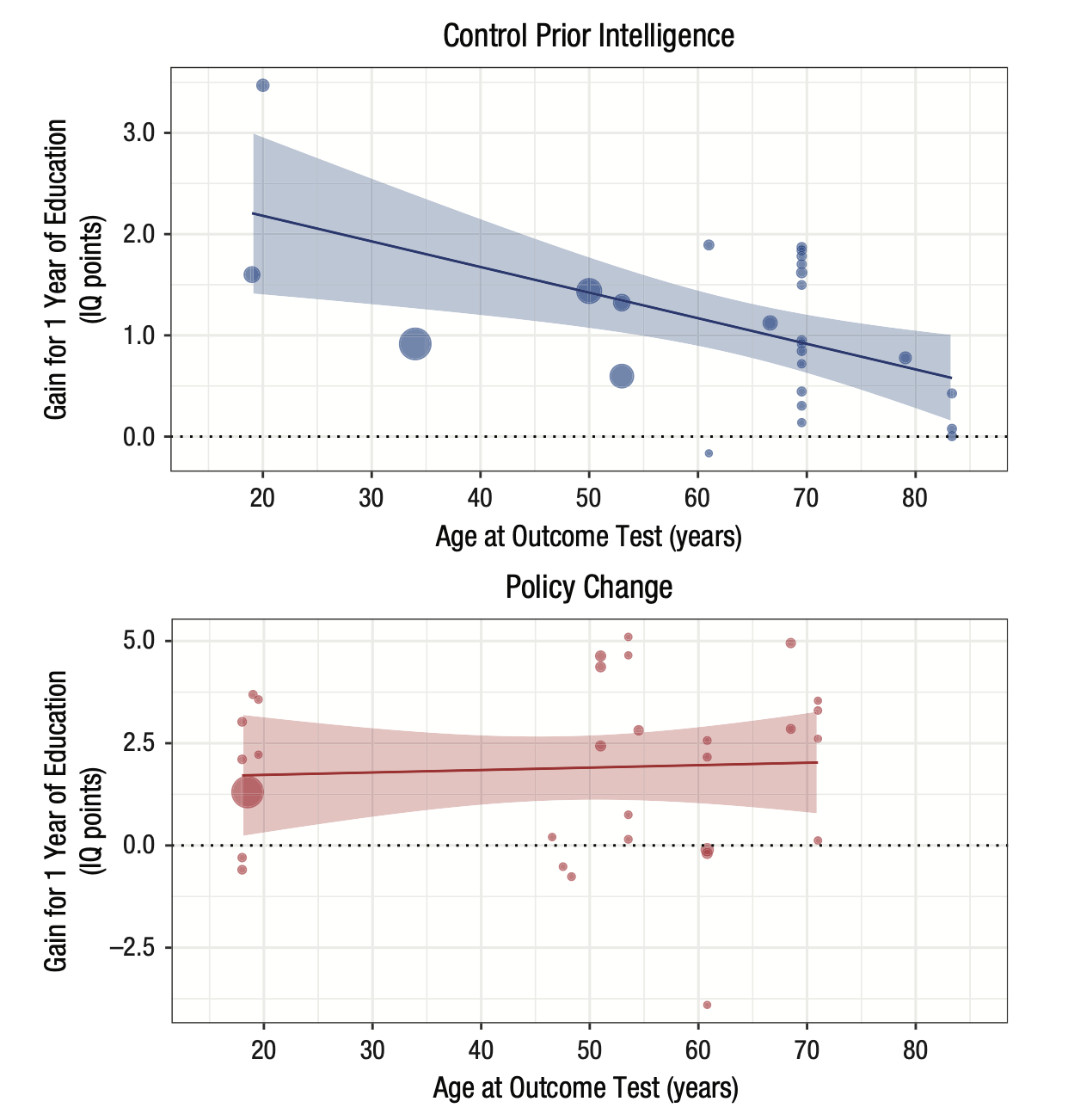
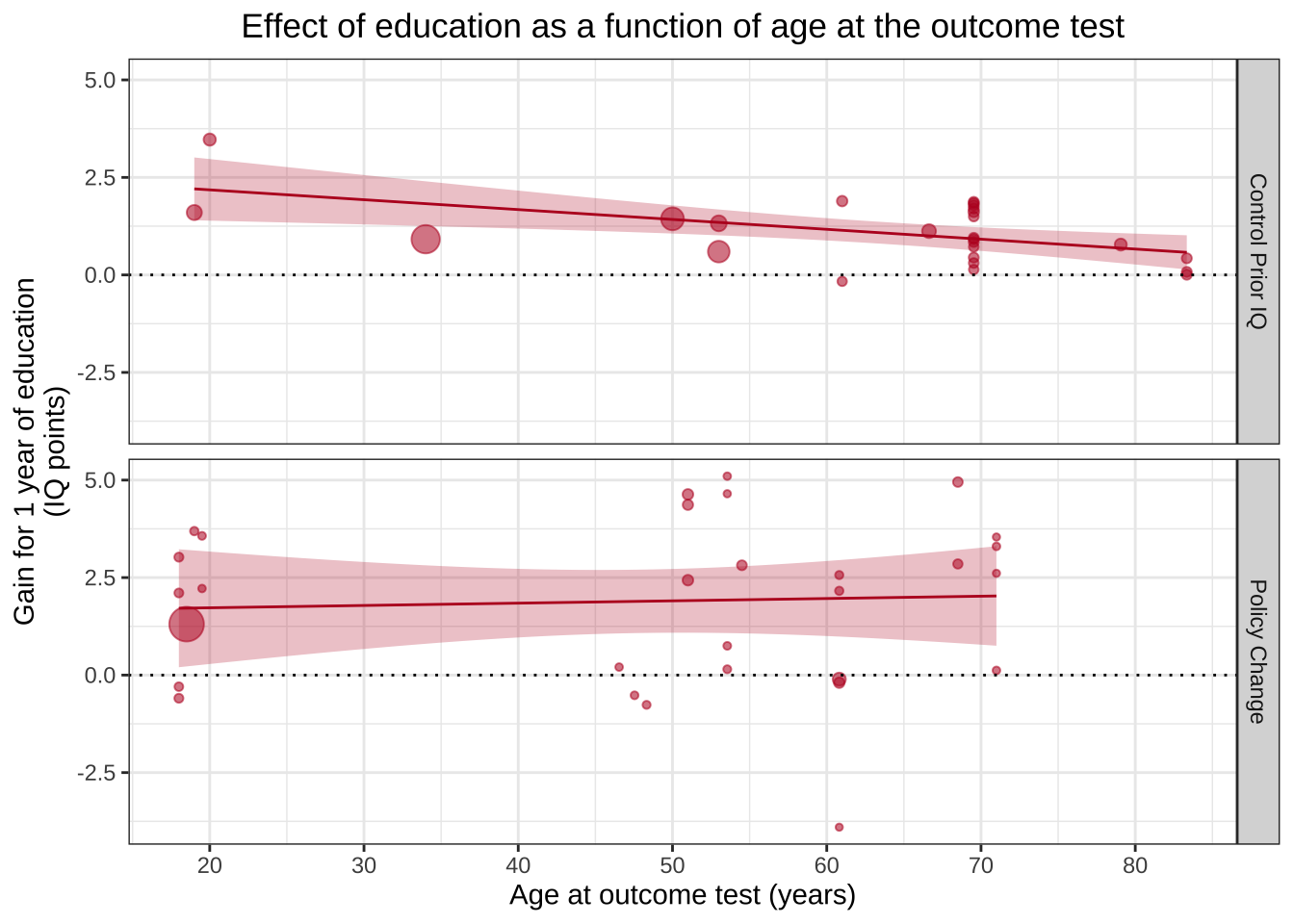
График мета-анализа: зависимость размера эффекта образования на IQ от среднего возраста участников
Эта картинка показывает, насколько размер эффекта (выраженный в баллах IQ) зависит от того, какой средний возраст участвовавших в исследовании испытуемых.
Каждая точка на этом графике — это отдельное исследование, положение по оси x — средний возраст респондентов, а положение по оси y — средний прирост интеллекта согласно исследованию. Размер точки отражает “точность” исследования (грубо говоря, чем больше выборка, тем больше точка). Два графика обозначают два квазиэкспериментальных плана.
Мы сфокусируемся на нижней картинке с “Policy change” — это как раз исследования, в которых изучается изменения интеллекта в возрастных группах после изменения количества лет обучения в школе.
Мы полностью воспроизведем код построчно, посмотрим, как эта картинка создавалась шаг за шагом.
Заметьте, этот набор данных использует немного непривычный для нас формат хранения данных. Попытайтесь самостоятельно прочитать его.
# A tibble: 142 × 17
Study_ID Data_ID k Country n Design outcome_test_cat Effect_size
<dbl> <dbl> <dbl> <chr> <dbl> <chr> <dbl> <dbl>
1 1 1 4 UK 483 Control Pr… 0 0.778
2 1 1 4 UK 290 Control Pr… 1 0.0771
3 1 1 4 UK 290 Control Pr… 1 0.427
4 1 1 4 UK 288 Control Pr… 1 0.00519
5 1 2 13 UK 1017 Control Pr… 0 1.62
6 1 2 13 UK 1022 Control Pr… 1 0.915
7 1 2 13 UK 1021 Control Pr… 1 0.305
8 1 2 13 UK 981 Control Pr… 1 0.719
9 1.5 2 13 UK 1024 Control Pr… 1 1.70
10 1.5 2 13 UK 1023 Control Pr… 1 1.78
# ℹ 132 more rows
# ℹ 9 more variables: SE <dbl>, Outcome_age <dbl>, quasi_age <dbl>,
# cpiq_early_age <dbl>, cpiq_age_diff <dbl>, ses_funnel <dbl>,
# published <dbl>, Male_only <dbl>, Achievement <dbl>
Каждая строчка — это результат отдельного исследования, при этом одна статья может включать несколько исследований, поэтому исследований в датасете больше, чем статей.
В дальнейшем мы будем использовать код авторов статьи и смотреть, строчка за строчкой, как он будет работать.
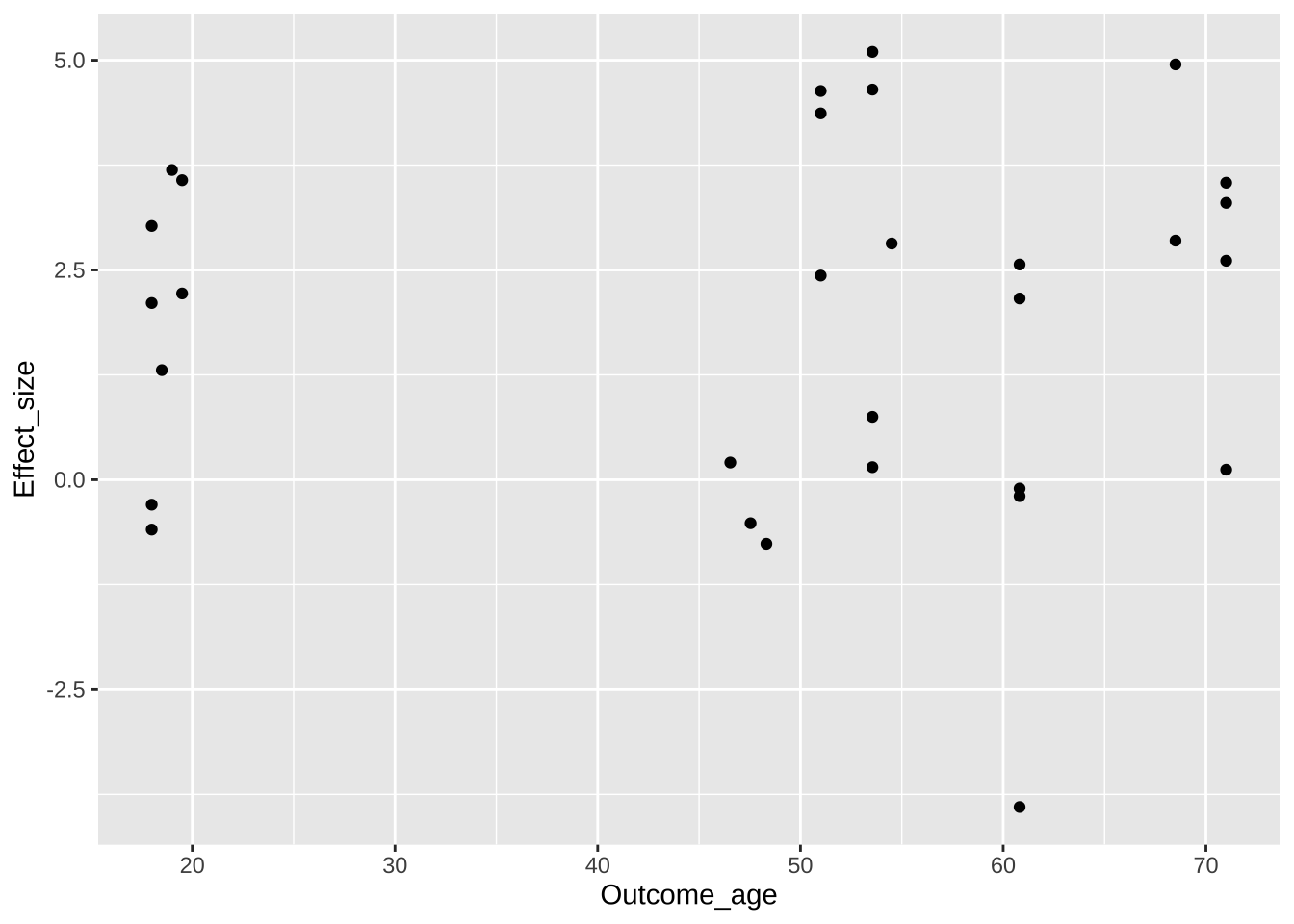
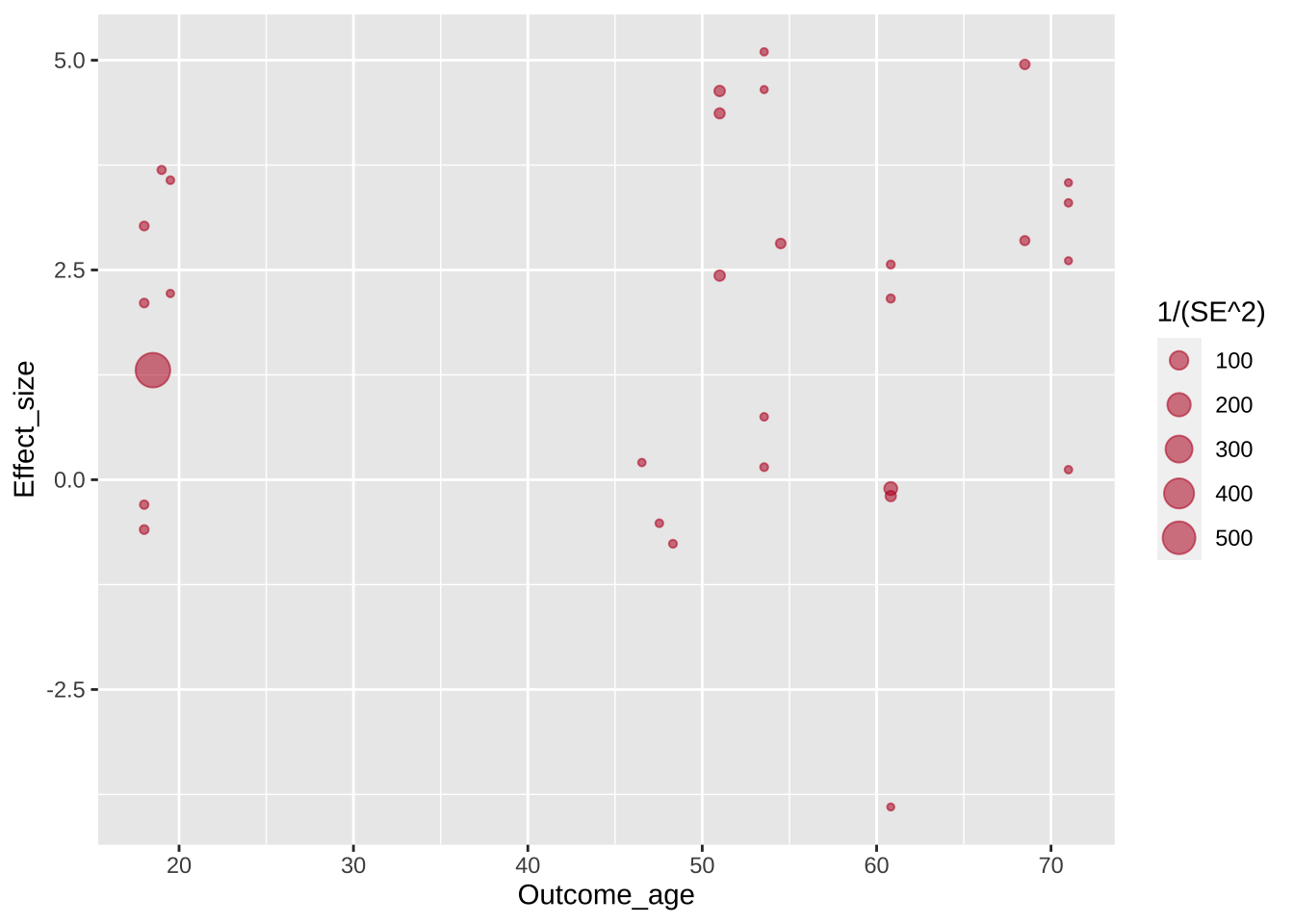
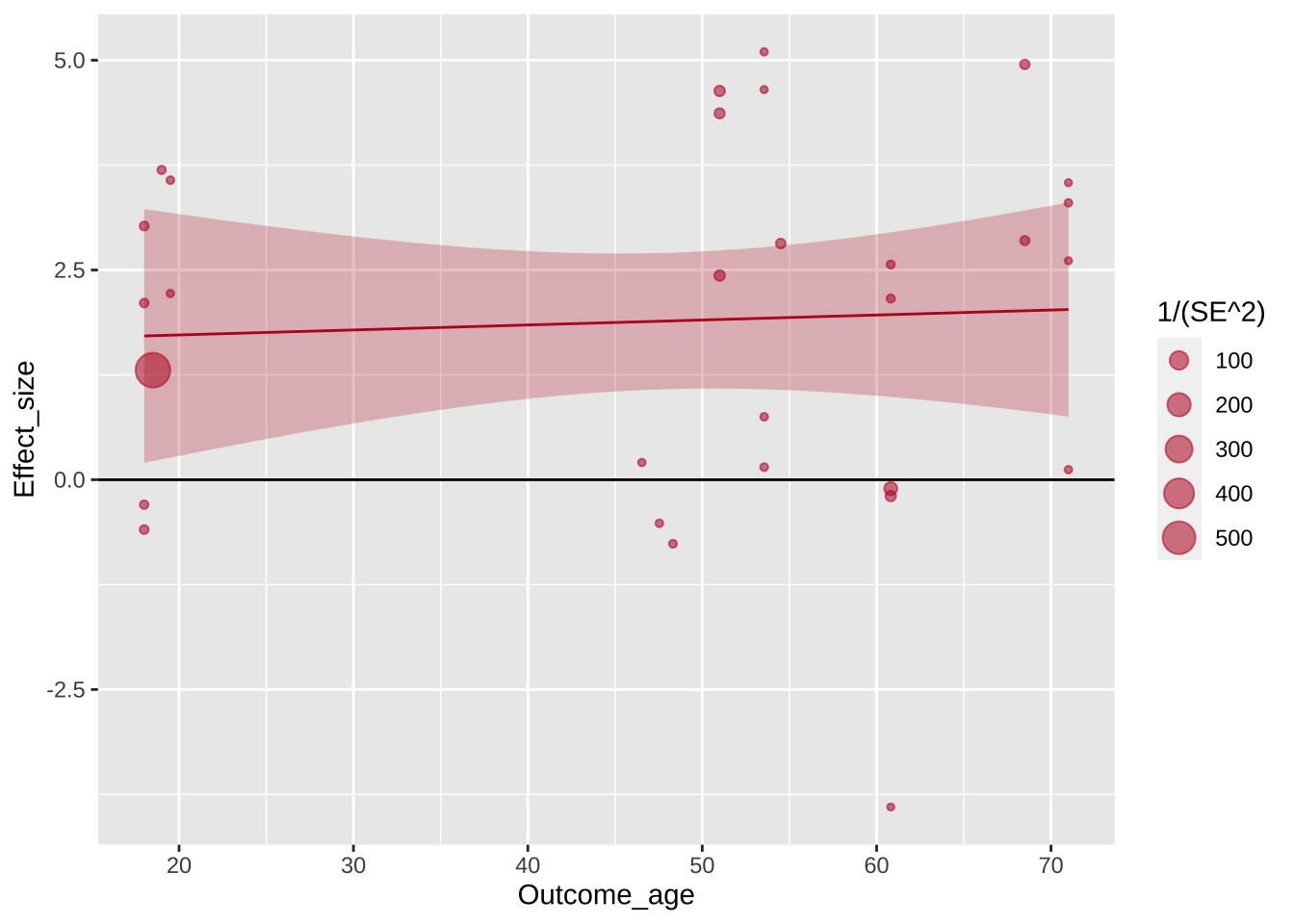
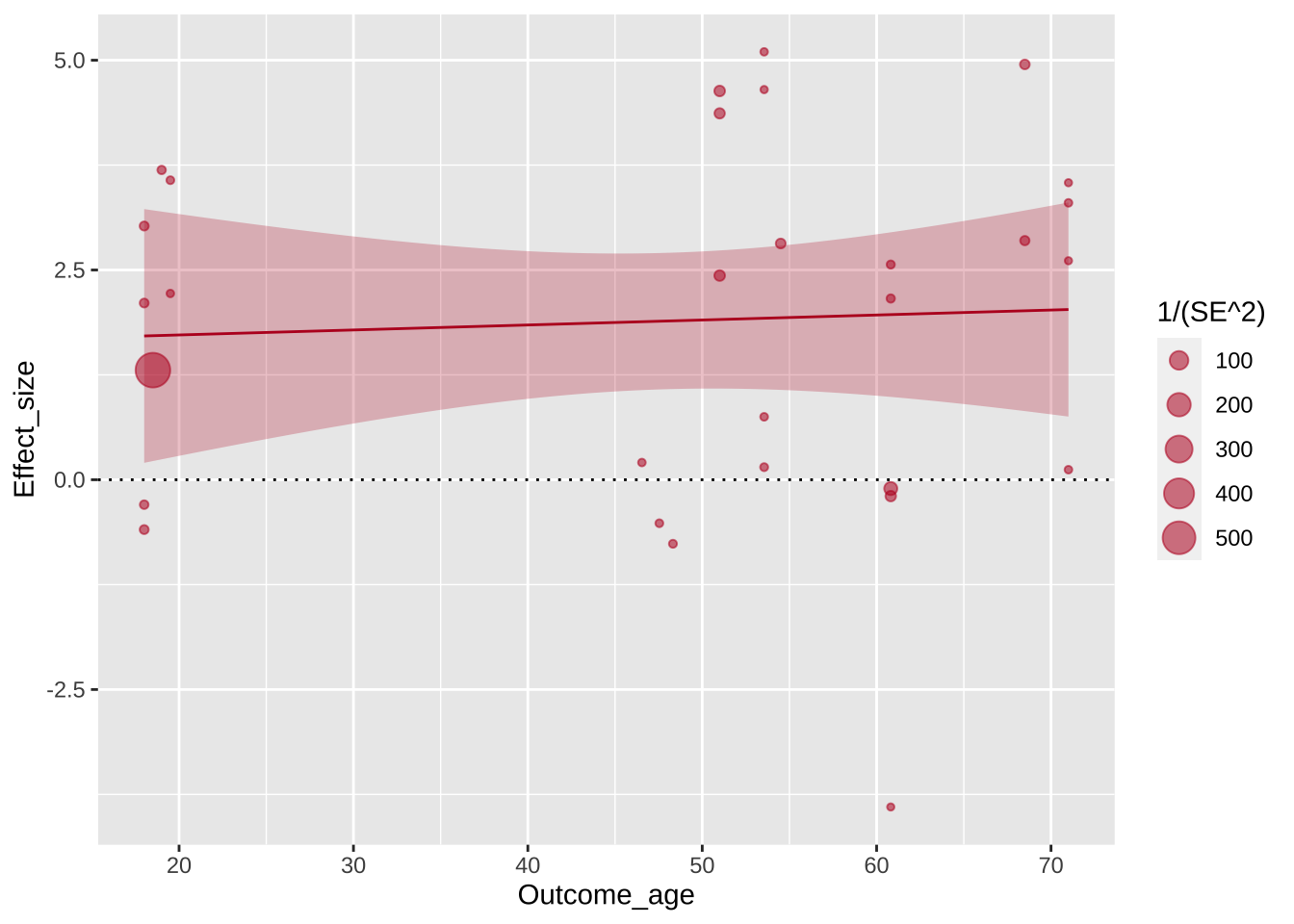
Что изменилось? Появилась координатная ось и шкалы. Заметьте, масштаб неслучаен: он строится на основе разброса значений в выбранных колонках. Однако этого недостаточно для отрисовки графика, не хватает геометрии: нужно задать, в какую геометрическую сущность отобразятся данные.
Перед нами возникла проблема оверплоттинга: некоторые точки перекрывают друг друга, поскольку имеют очень близкие координаты. Авторы графика решают эту проблему очевидным способом: добавляют прозрачности точкам. Заметьте, прозрачность задается для всех точек одним значением, поэтому параметр alpha задается вне функции aes().
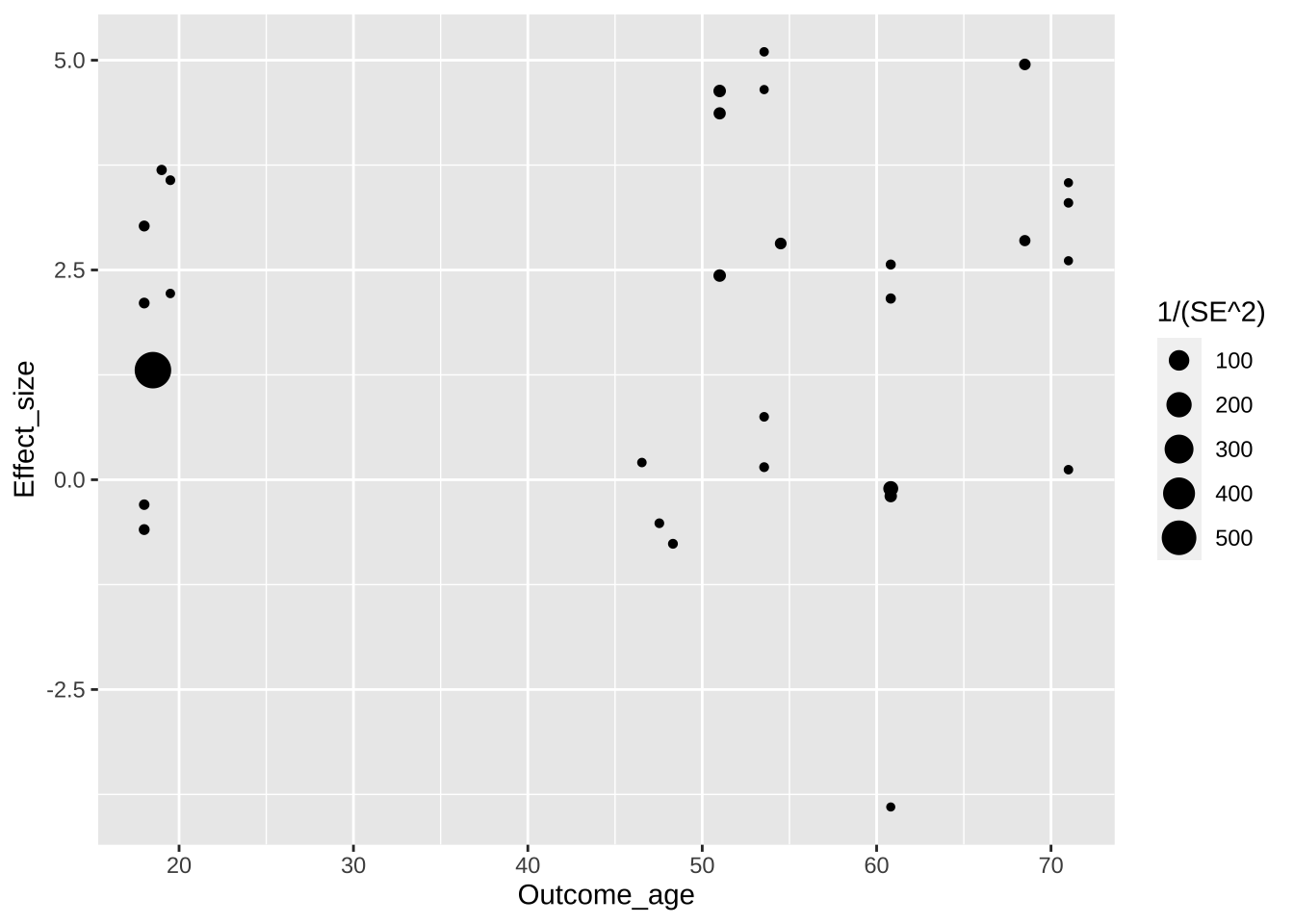
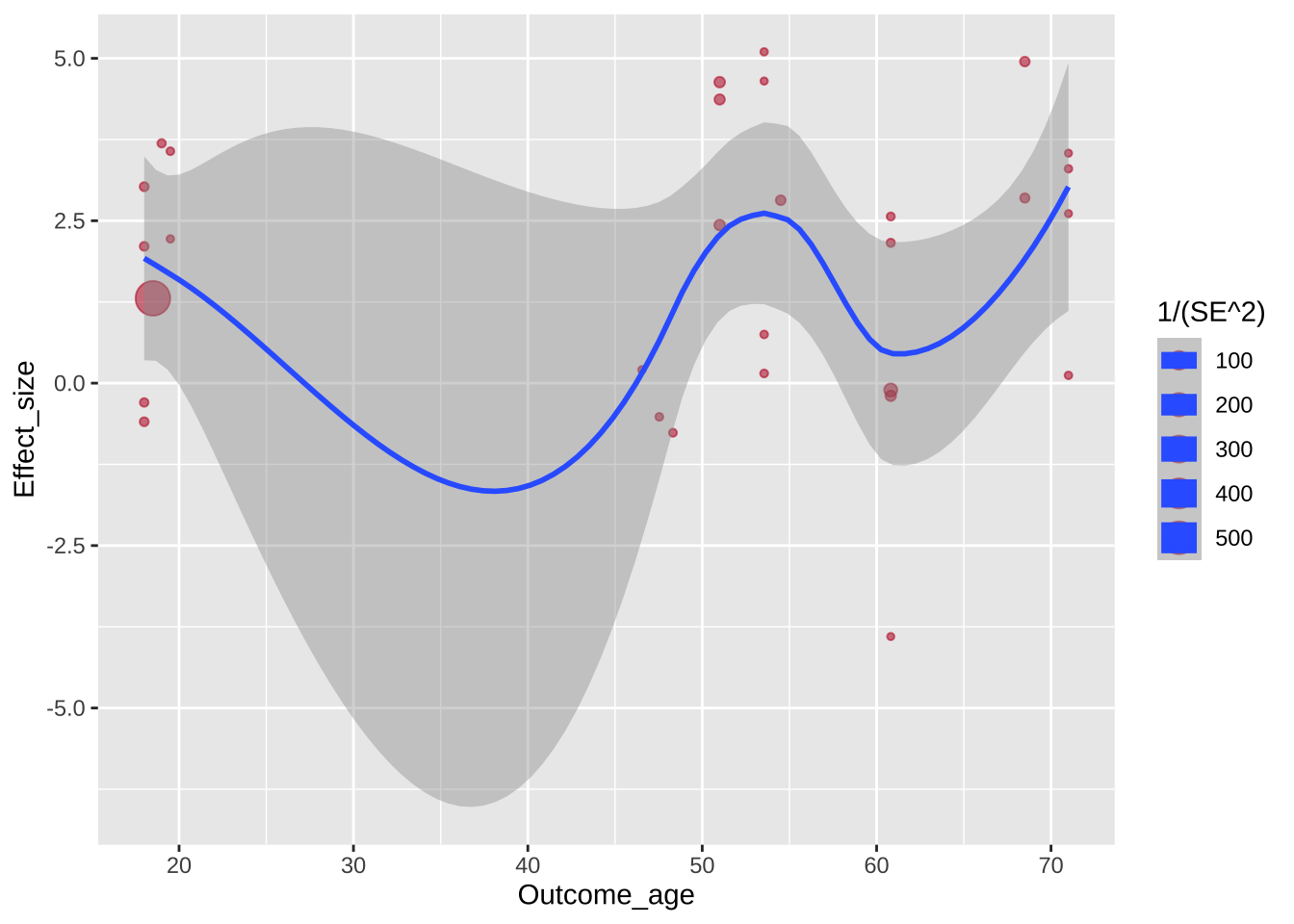
Теперь добавим регрессионную прямую с доверительными интервалами на график. Это специальный геом geom_smooth() со специальной статистикой, который займет второй слой данного графика.
Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.
`geom_smooth()` using method = 'loess' and formula = 'y ~ x'
Warning: The following aesthetics were dropped during statistical transformation: size.
ℹ This can happen when ggplot fails to infer the correct grouping structure in
the data.
ℹ Did you forget to specify a `group` aesthetic or to convert a numerical
variable into a factor?
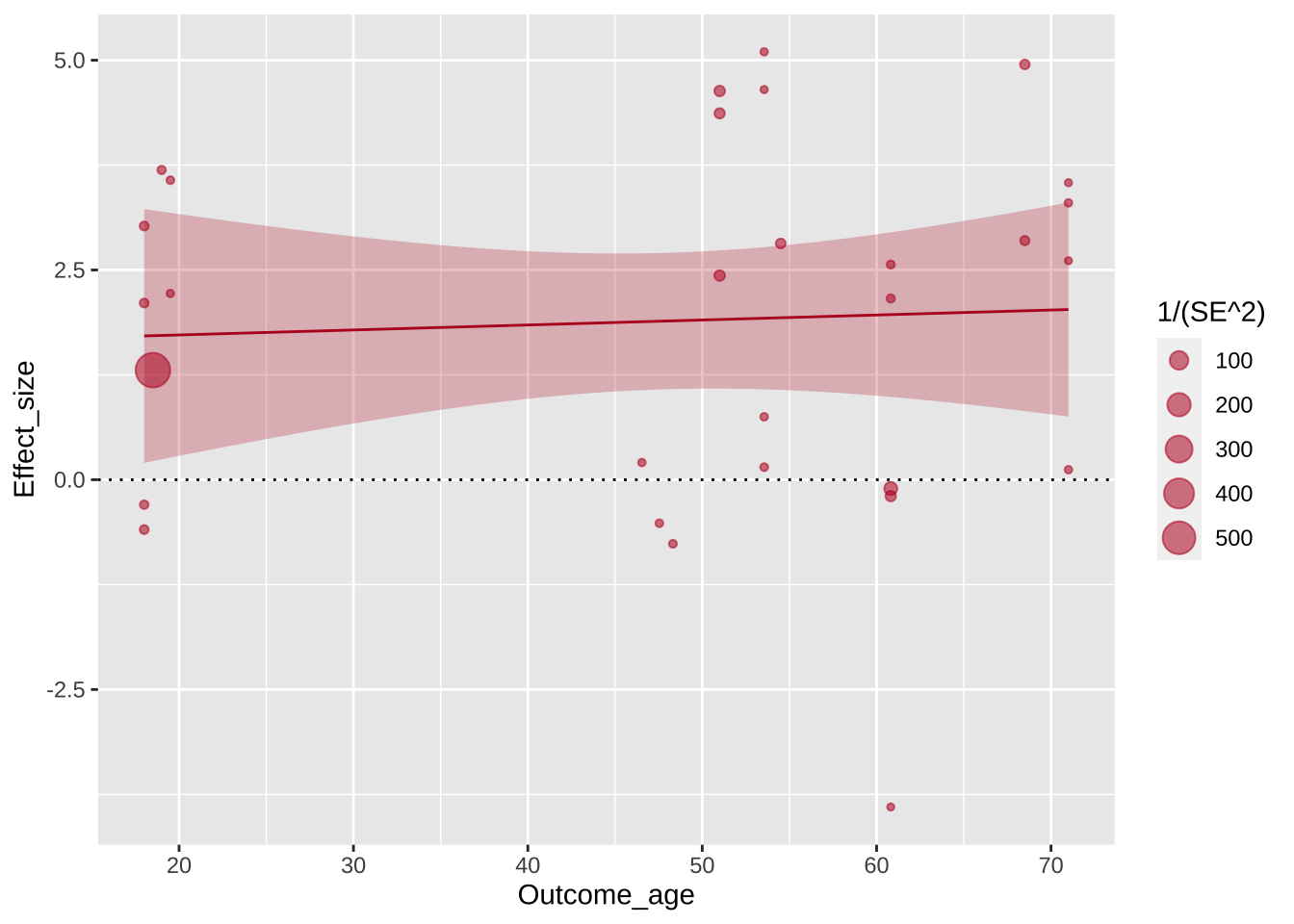
По умолчанию geom_smooth() строит кривую линию. Поставим method = "lm" для прямой.
Warning: The following aesthetics were dropped during statistical transformation: size.
ℹ This can happen when ggplot fails to infer the correct grouping structure in
the data.
ℹ Did you forget to specify a `group` aesthetic or to convert a numerical
variable into a factor?
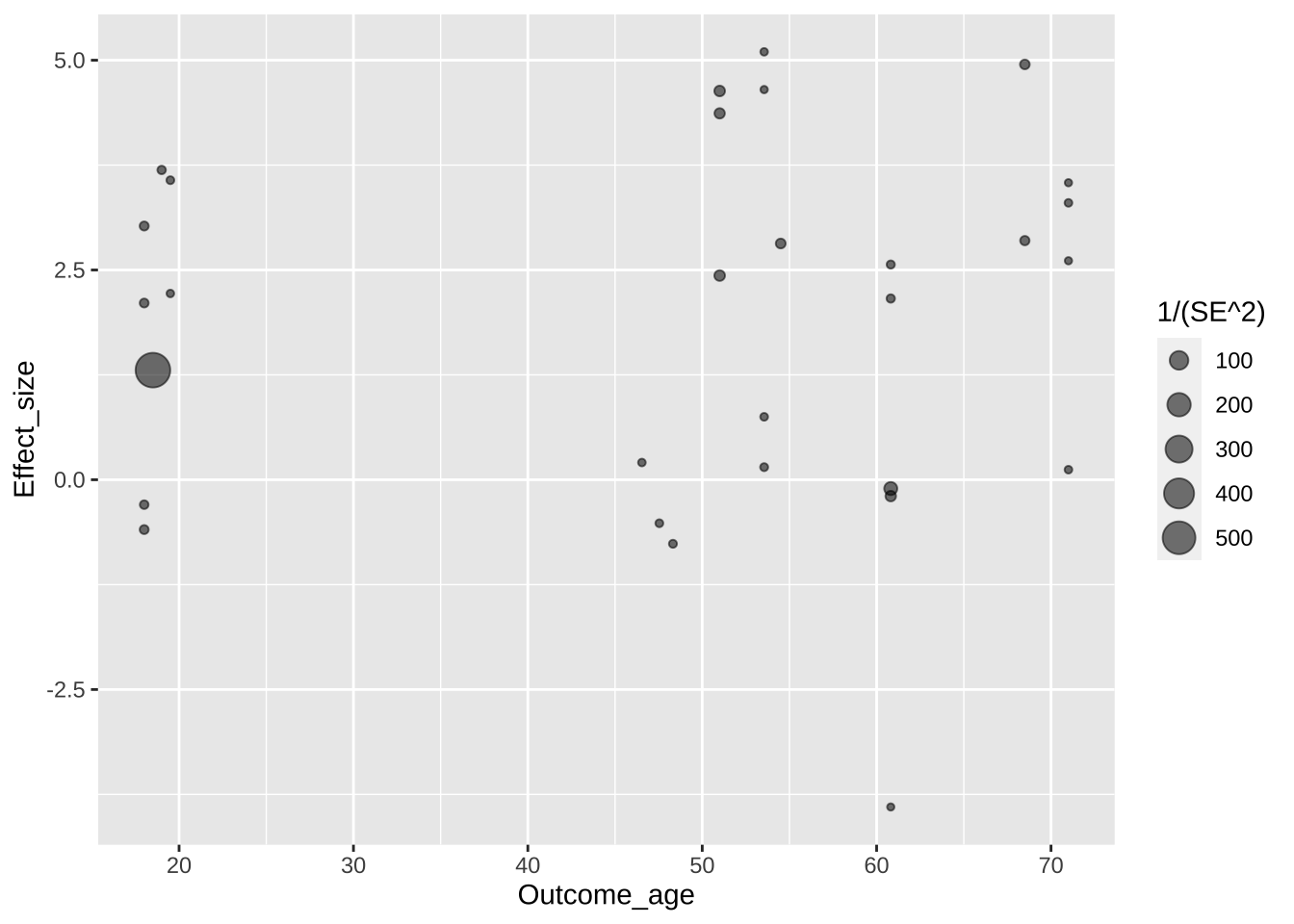
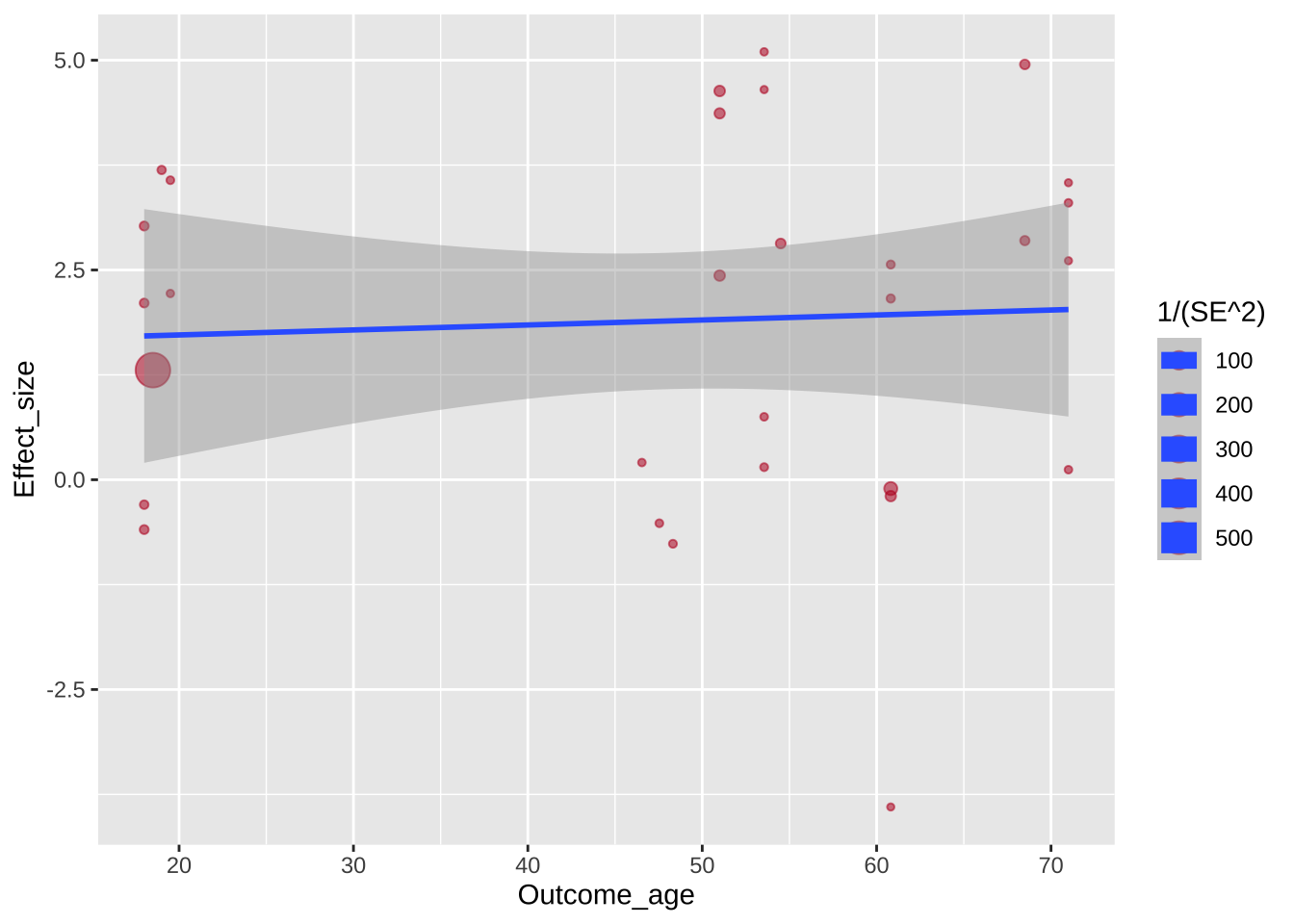
Теперь нужно поменять цвет: ярко синий цвет, используемый по умолчанию здесь попросту мешает восприятию графика.
Warning: The following aesthetics were dropped during statistical transformation: size.
ℹ This can happen when ggplot fails to infer the correct grouping structure in
the data.
ℹ Did you forget to specify a `group` aesthetic or to convert a numerical
variable into a factor?
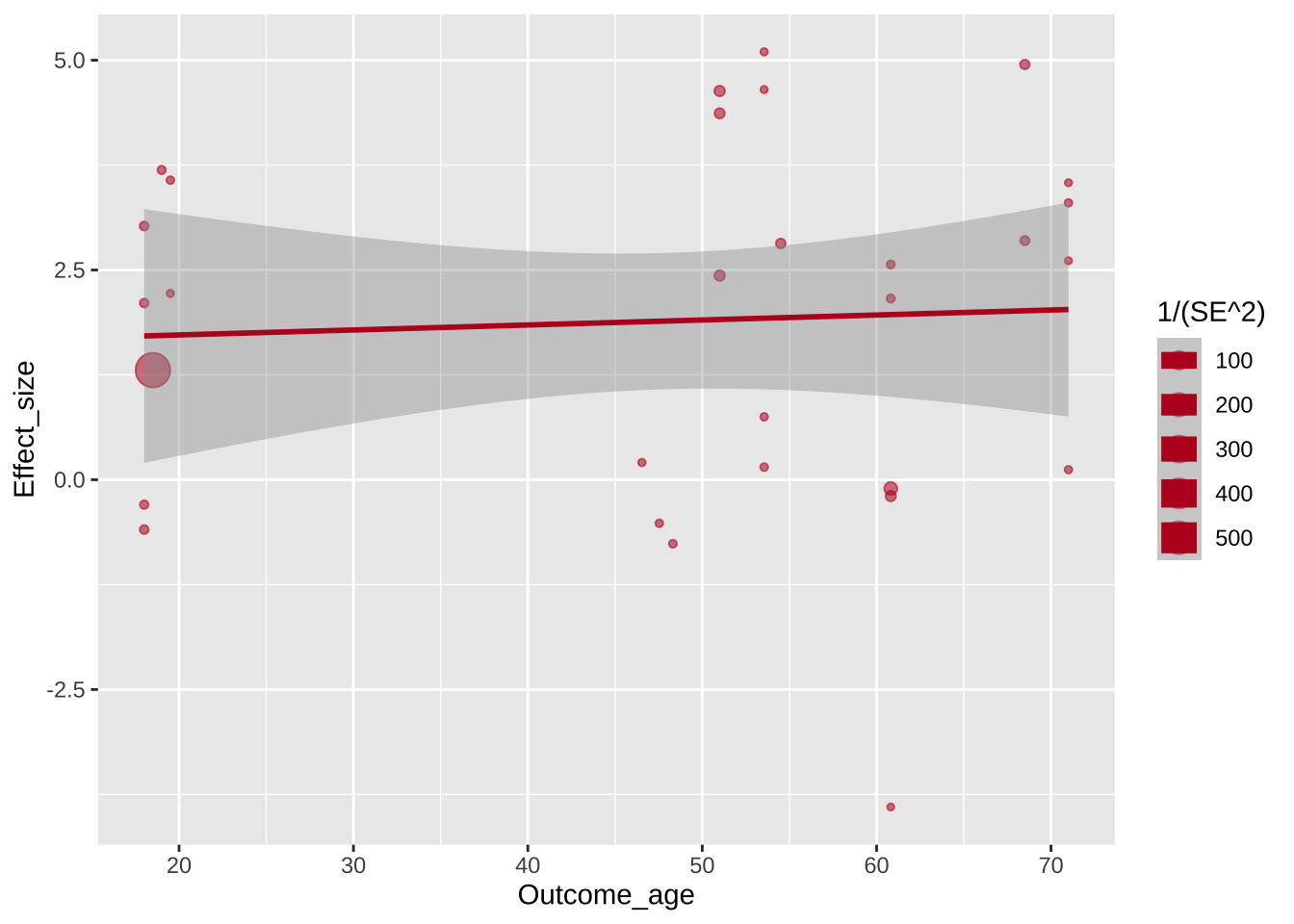
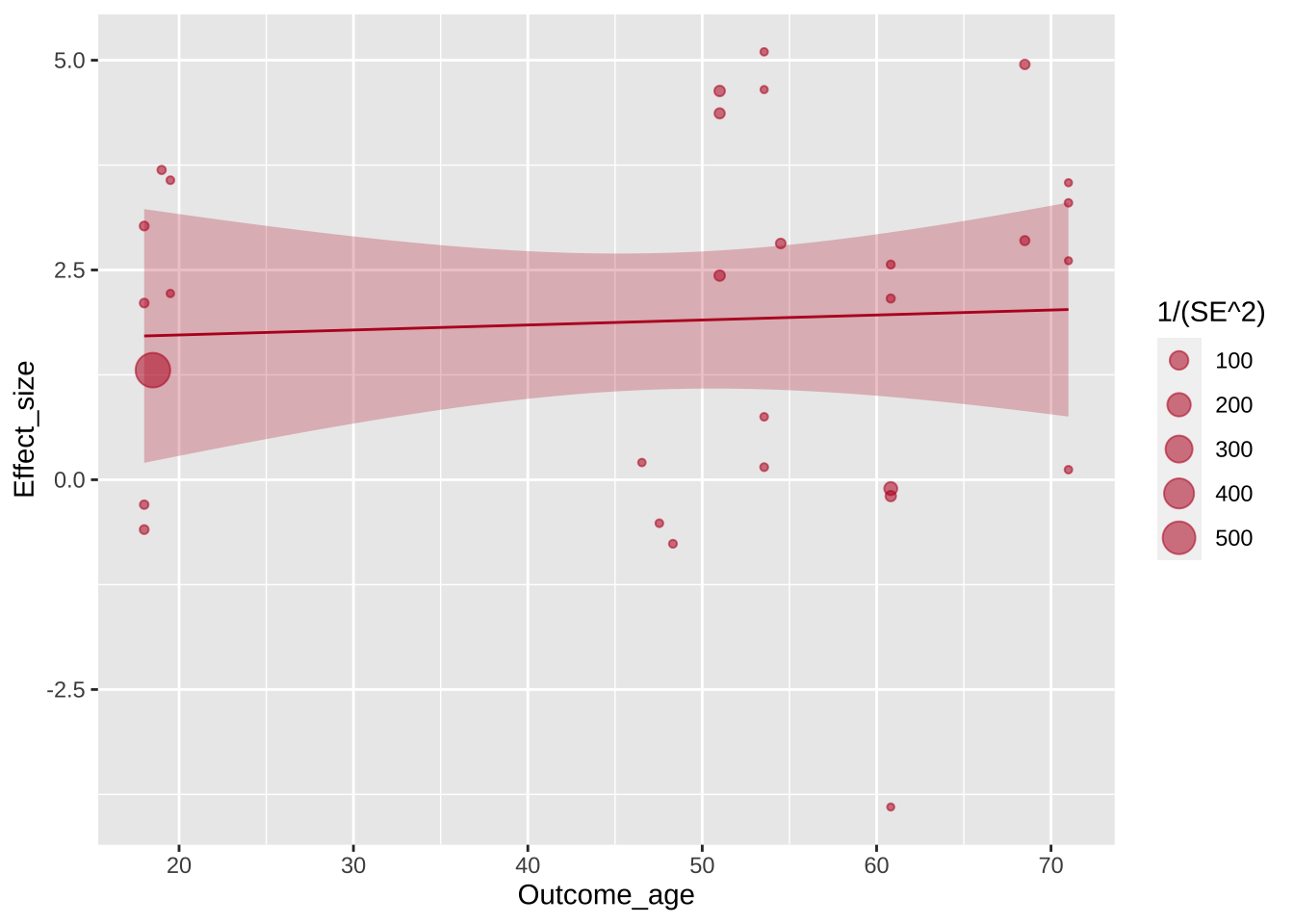
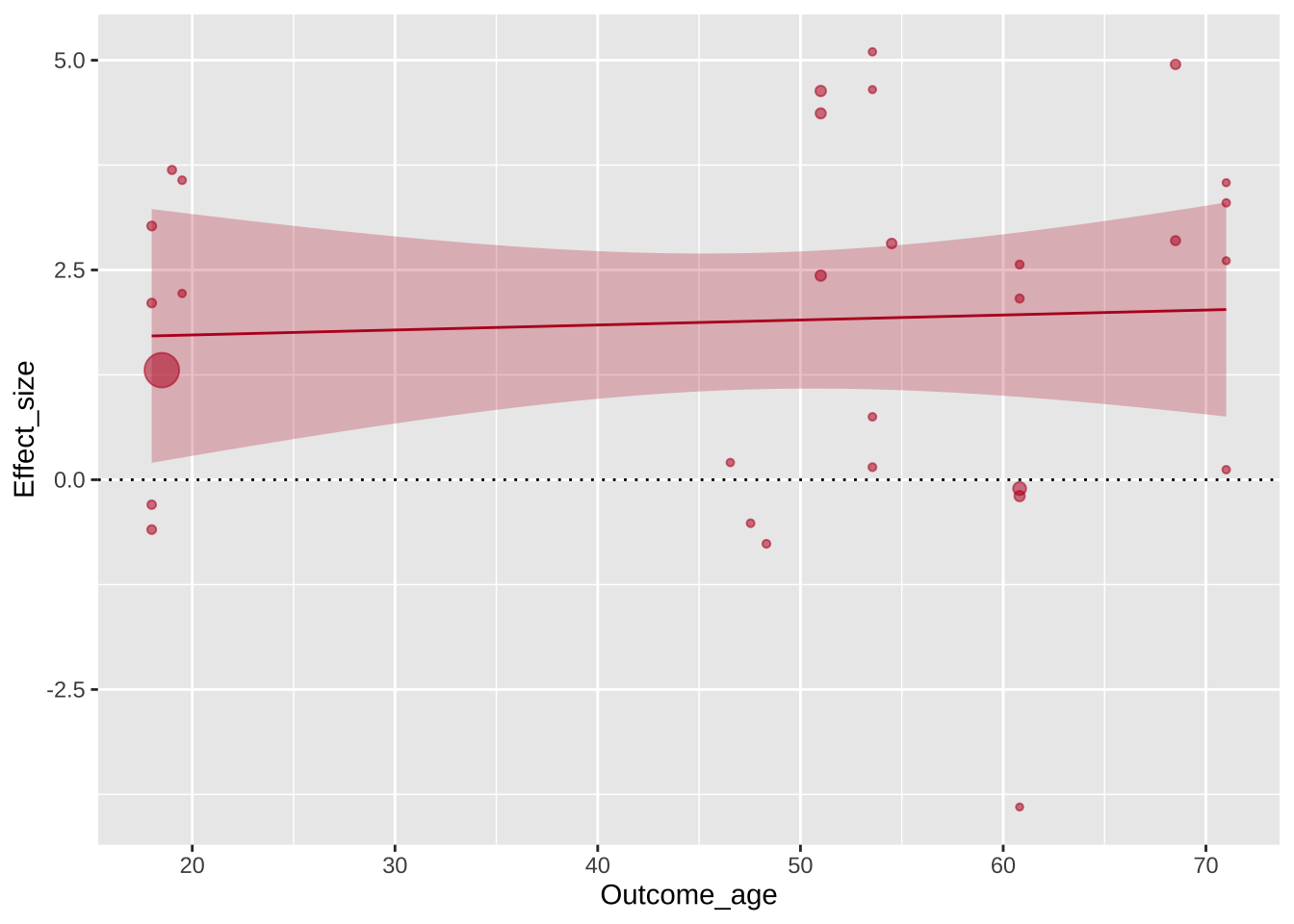
Авторы графика перекрашивают серую полупрозрачную область тоже. В этом случае используется параметр fill =, а не colour =, но цвет используется тот же.
Warning: The following aesthetics were dropped during statistical transformation: size.
ℹ This can happen when ggplot fails to infer the correct grouping structure in
the data.
ℹ Did you forget to specify a `group` aesthetic or to convert a numerical
variable into a factor?
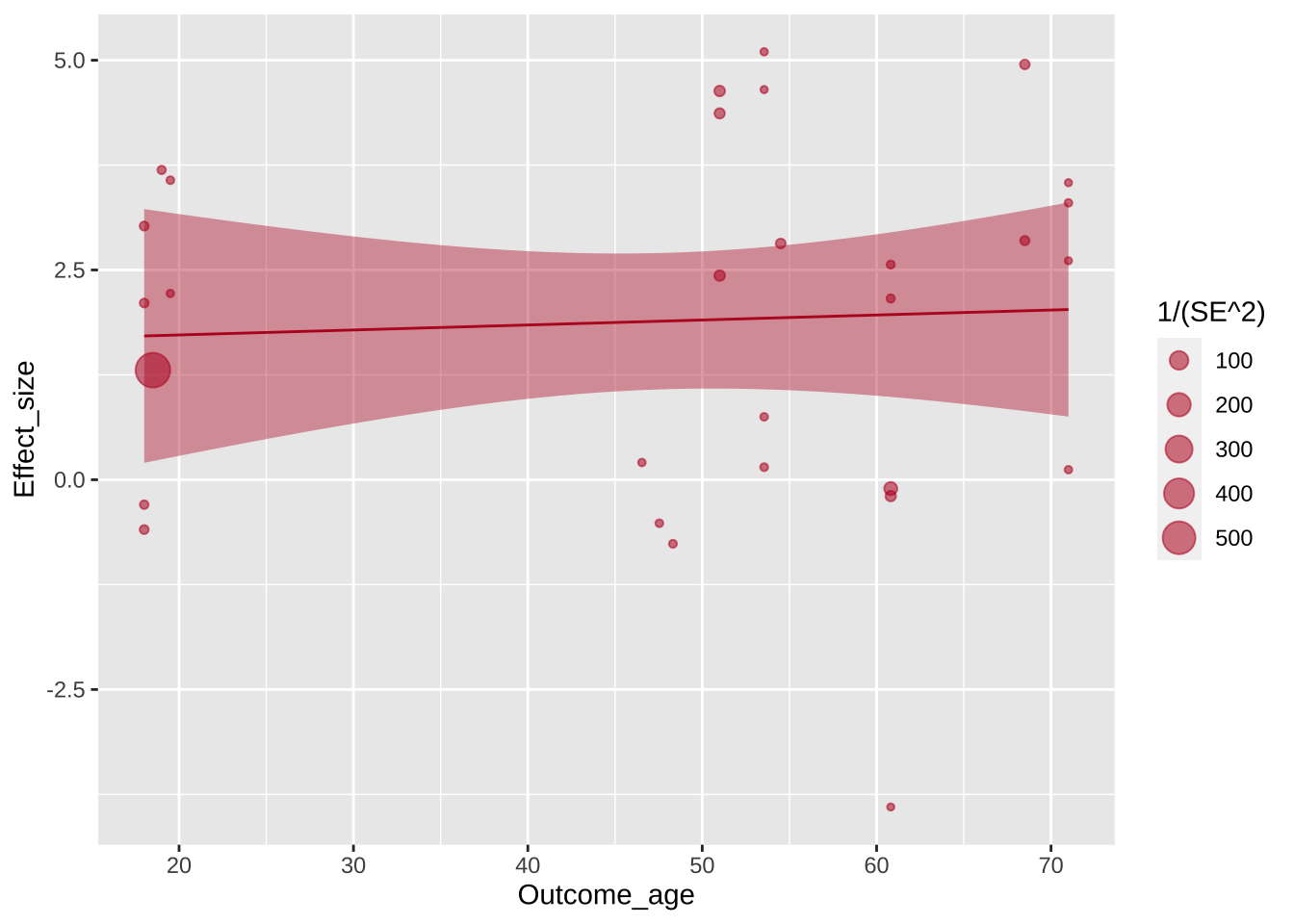
Регрессионную линию авторы немного утоньшают с помощью параметра size =.
Warning: The `<scale>` argument of `guides()` cannot be `FALSE`. Use "none" instead as
of ggplot2 3.3.4.
`geom_smooth()` using formula = 'y ~ x'
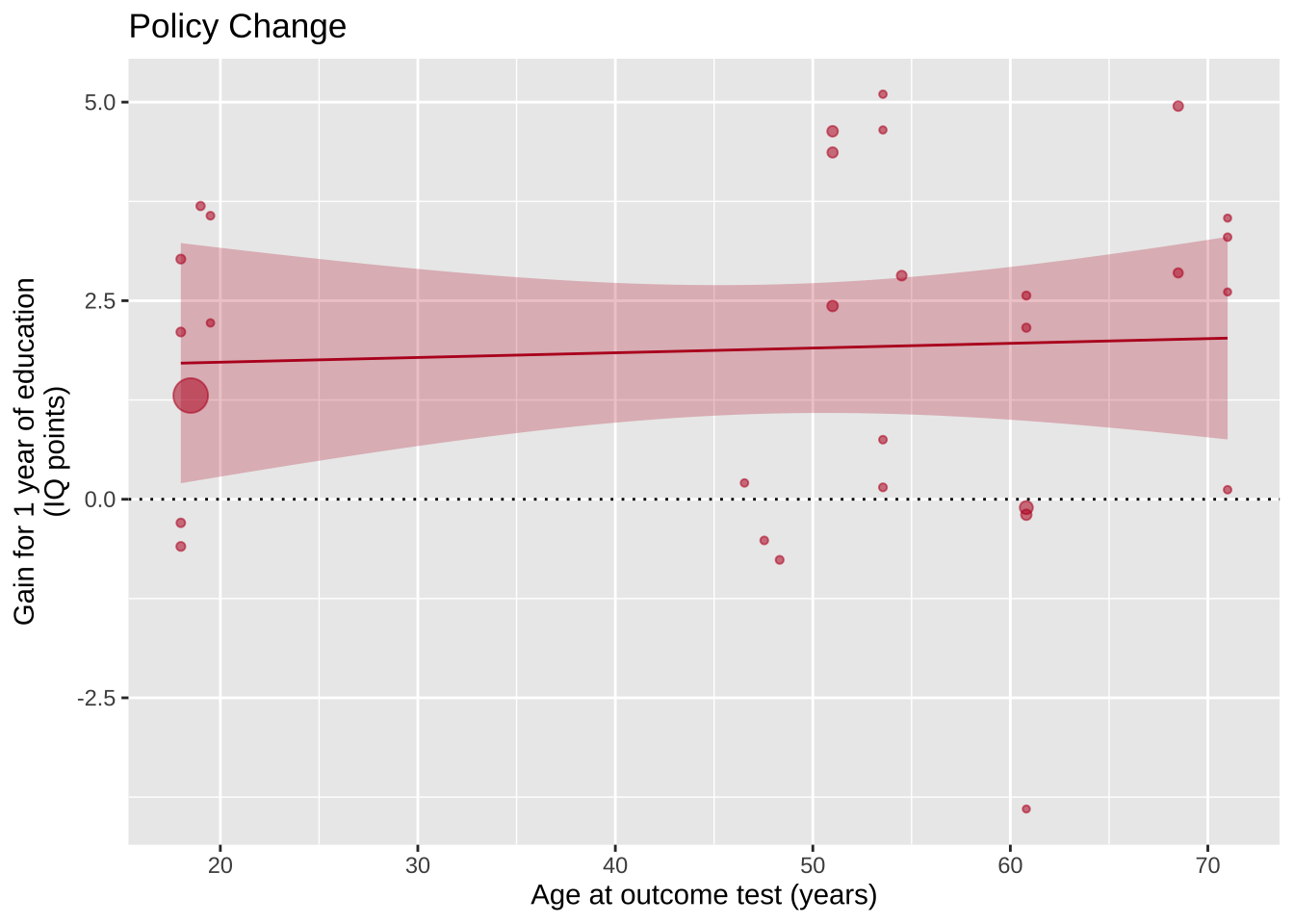
Следующим этапом авторы добавляют подписи шкал и название картинки. Обратите внимание на \n внутри подписи к оси y, которая задает перенос на следующую строку.
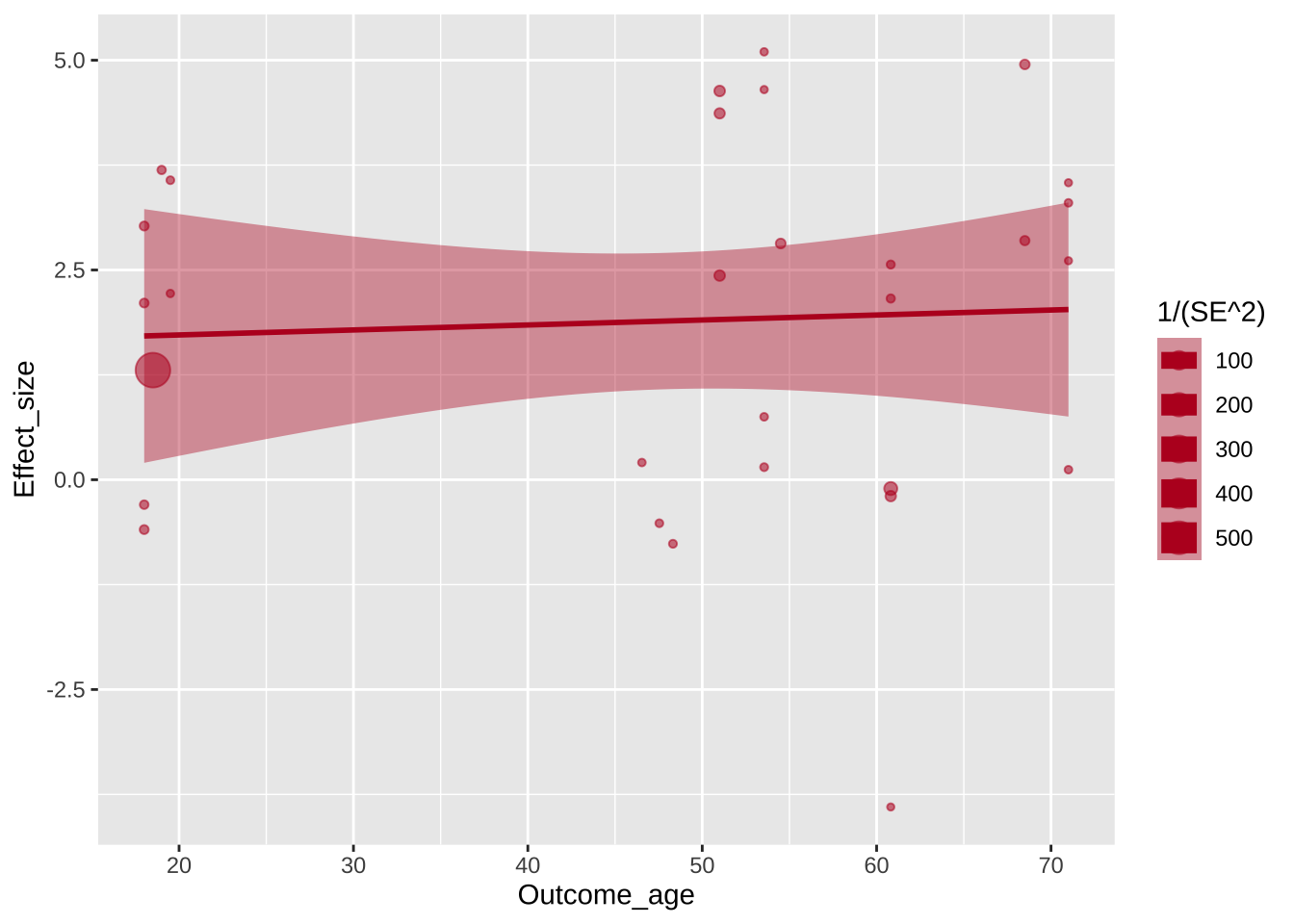
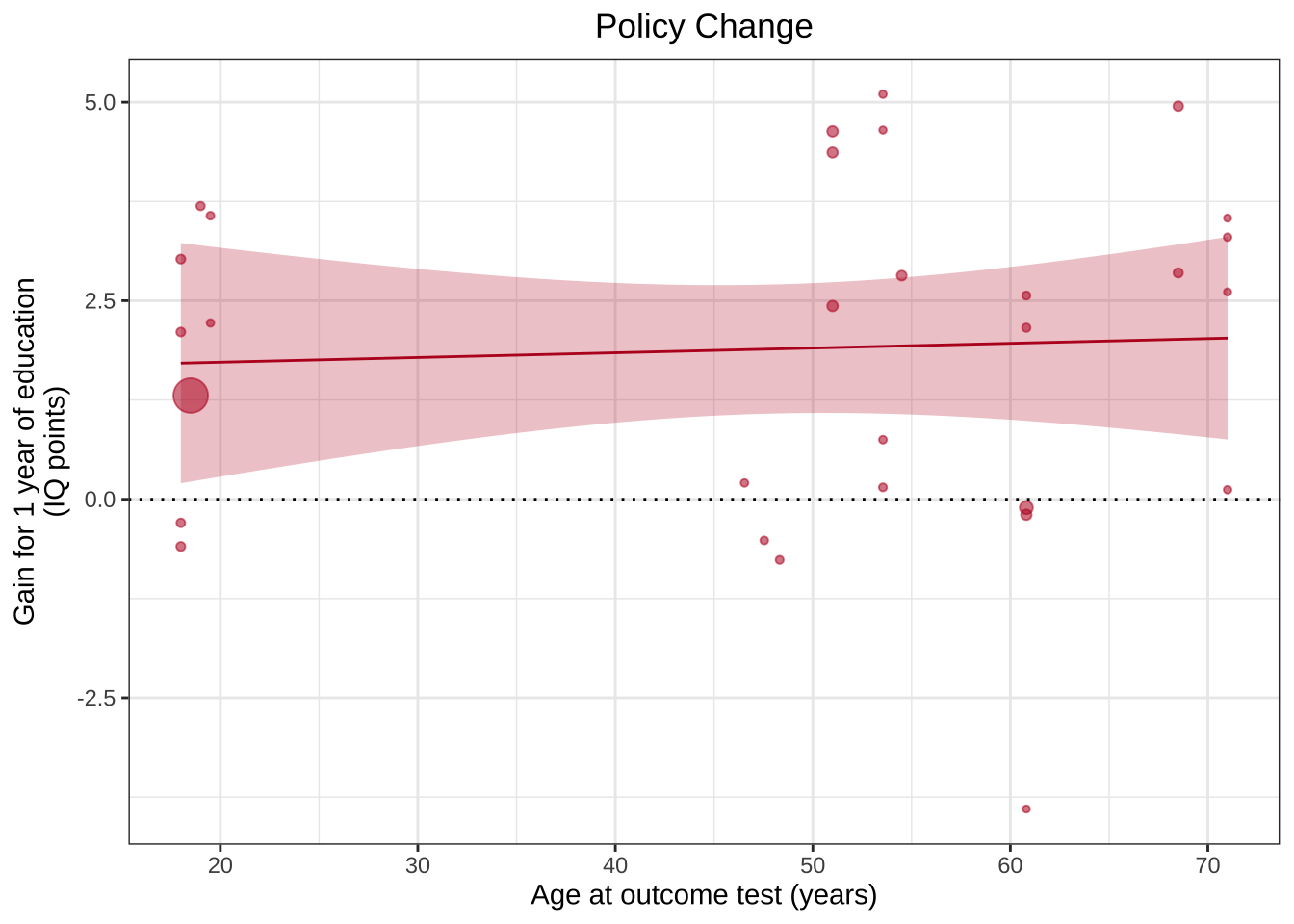
ggplot(aes(x=Outcome_age, y=Effect_size, size=1/(SE^2)), data=poli) +geom_point(alpha=.55, colour="#BA1825") +geom_hline(yintercept=0, linetype="dotted") +scale_x_continuous(breaks=c(20,30,40,50,60,70,80)) +xlab("Age at outcome test (years)") +ylab("Gain for 1 year of education\n(IQ points)") +guides(size=F) +geom_smooth(method="lm", colour="#BA1825",fill="#BA1825",size=.5, alpha=.25) +ggtitle("Policy Change")
`geom_smooth()` using formula = 'y ~ x'
Теперь пришло время сделать график более красивым и понятным с помощью изменения подложки, т.е. работы с темой графика. Здесь тема задается сначала как theme_bw() — встроенная в {ggplot2} минималистичная тема, а потом через функцию theme(), через которую можно управлять конкретными элементами темы. Здесь это сделано, чтобы передвинуть название графика к центру.
ggplot(aes(x=Outcome_age, y=Effect_size, size=1/(SE^2)), data=poli) +geom_point(alpha=.55, colour="#BA1825") +geom_hline(yintercept=0, linetype="dotted") +theme_bw() +scale_x_continuous(breaks=c(20,30,40,50,60,70,80)) +xlab("Age at outcome test (years)") +ylab("Gain for 1 year of education\n(IQ points)") +guides(size=F) +geom_smooth(method="lm", colour="#BA1825",fill="#BA1825",size=.5, alpha=.25) +ggtitle("Policy Change")+theme(plot.title =element_text(hjust=0.5))
`geom_smooth()` using formula = 'y ~ x'
Готово! Мы полностью воспроизвели график авторов статьи с помощью их открытого кода.
Если вы помните, то в изначальном графике было две картинки. Авторы делают их отдельно, с помощью почти идентичного кода. Нечто похожее можно сделать по-другому, применяя фасетки.
Для этого мы возьмем неотфильтрованный датасет df, а с помощью колонки Design, на основании которой разделялся датасет для графиков, произведем разделение графиков внутри самого ggplot объекта. Для этого нам понадобится функция facet_wrap(), в которой с помощью формулы можно задать колонки, по которым будут разделены картинки по вертикали (слева от ~) и горизонтально (справа от ~). Пробуем разделить графики горизонтально:
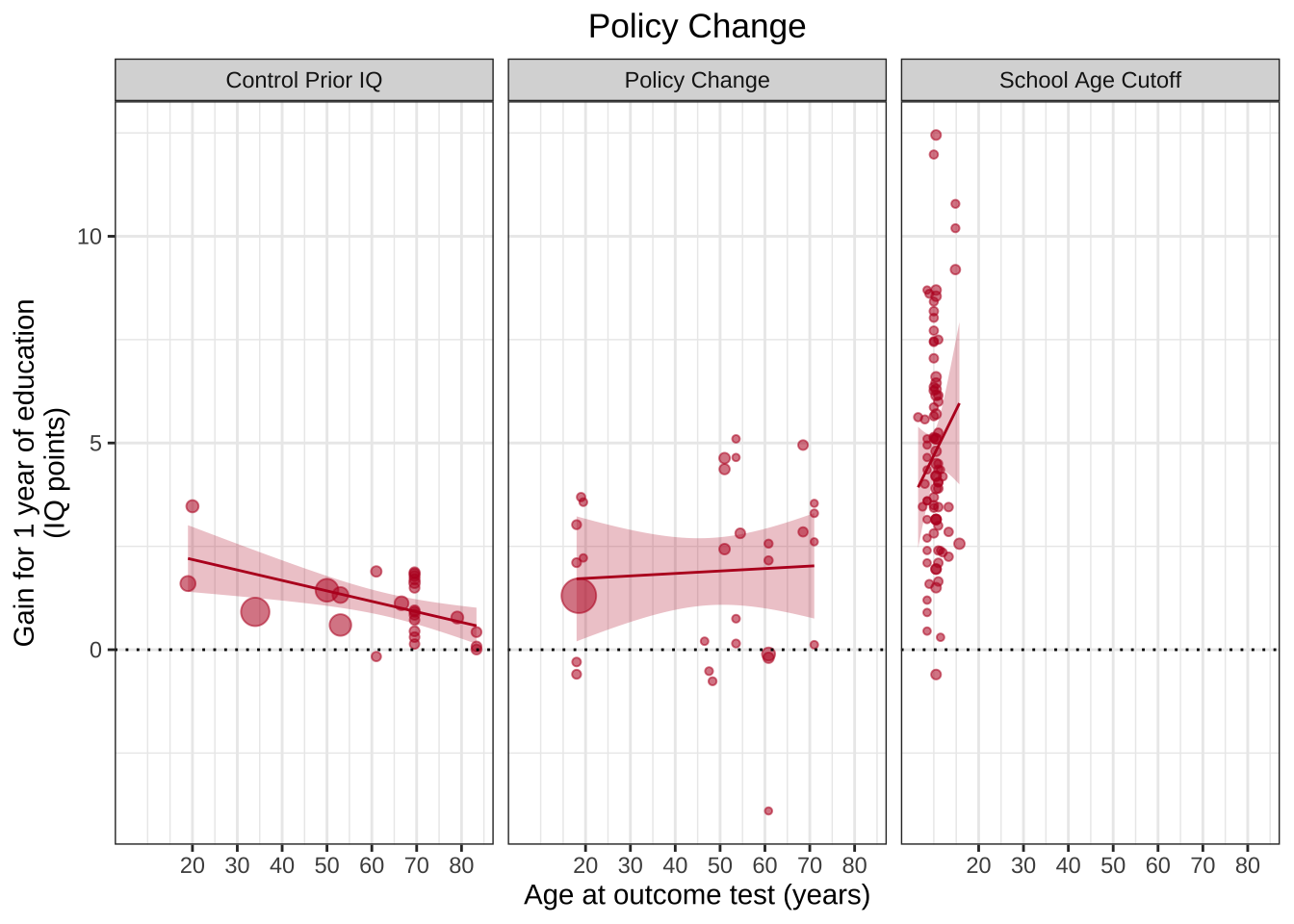
ggplot(aes(x=Outcome_age, y=Effect_size, size=1/(SE^2)), data=df) +geom_point(alpha=.55, colour="#BA1825") +geom_hline(yintercept=0, linetype="dotted") +theme_bw() +scale_x_continuous(breaks=c(20,30,40,50,60,70,80)) +xlab("Age at outcome test (years)") +ylab("Gain for 1 year of education\n(IQ points)") +guides(size=F) +geom_smooth(method="lm", colour="#BA1825",fill="#BA1825",size=.5, alpha=.25) +ggtitle("Policy Change")+theme(plot.title =element_text(hjust=0.5)) +facet_wrap(~Design)
`geom_smooth()` using formula = 'y ~ x'
Здесь становится очевидно, почему авторы не включали данные "School Age Cutoff" третьим графиком: средний возраст участников этих исследований сильно отличается.
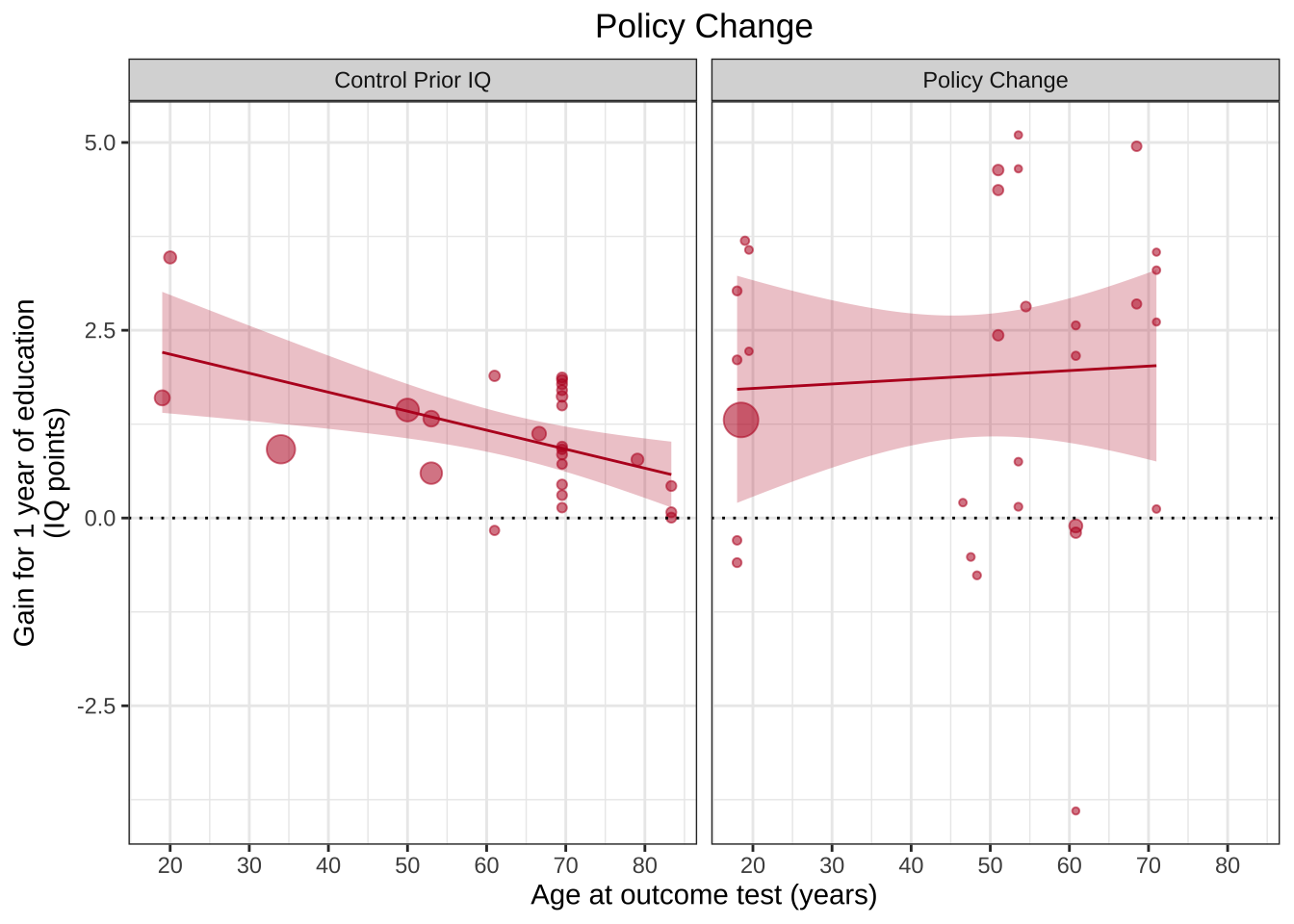
ggplot(aes(x=Outcome_age, y=Effect_size, size=1/(SE^2)), data=df %>%filter(Design !="School Age Cutoff")) +geom_point(alpha=.55, colour="#BA1825") +geom_hline(yintercept=0, linetype="dotted") +theme_bw() +scale_x_continuous(breaks=c(20,30,40,50,60,70,80)) +xlab("Age at outcome test (years)") +ylab("Gain for 1 year of education\n(IQ points)") +guides(size=F) +geom_smooth(method="lm", colour="#BA1825",fill="#BA1825",size=.5, alpha=.25) +ggtitle("Policy Change")+theme(plot.title =element_text(hjust=0.5)) +facet_wrap(~Design)
`geom_smooth()` using formula = 'y ~ x'
Теперь поставим два графика друг над другом, поместив Design слева от ~ внутри facet_grid(). Справа нужно добавить точку.
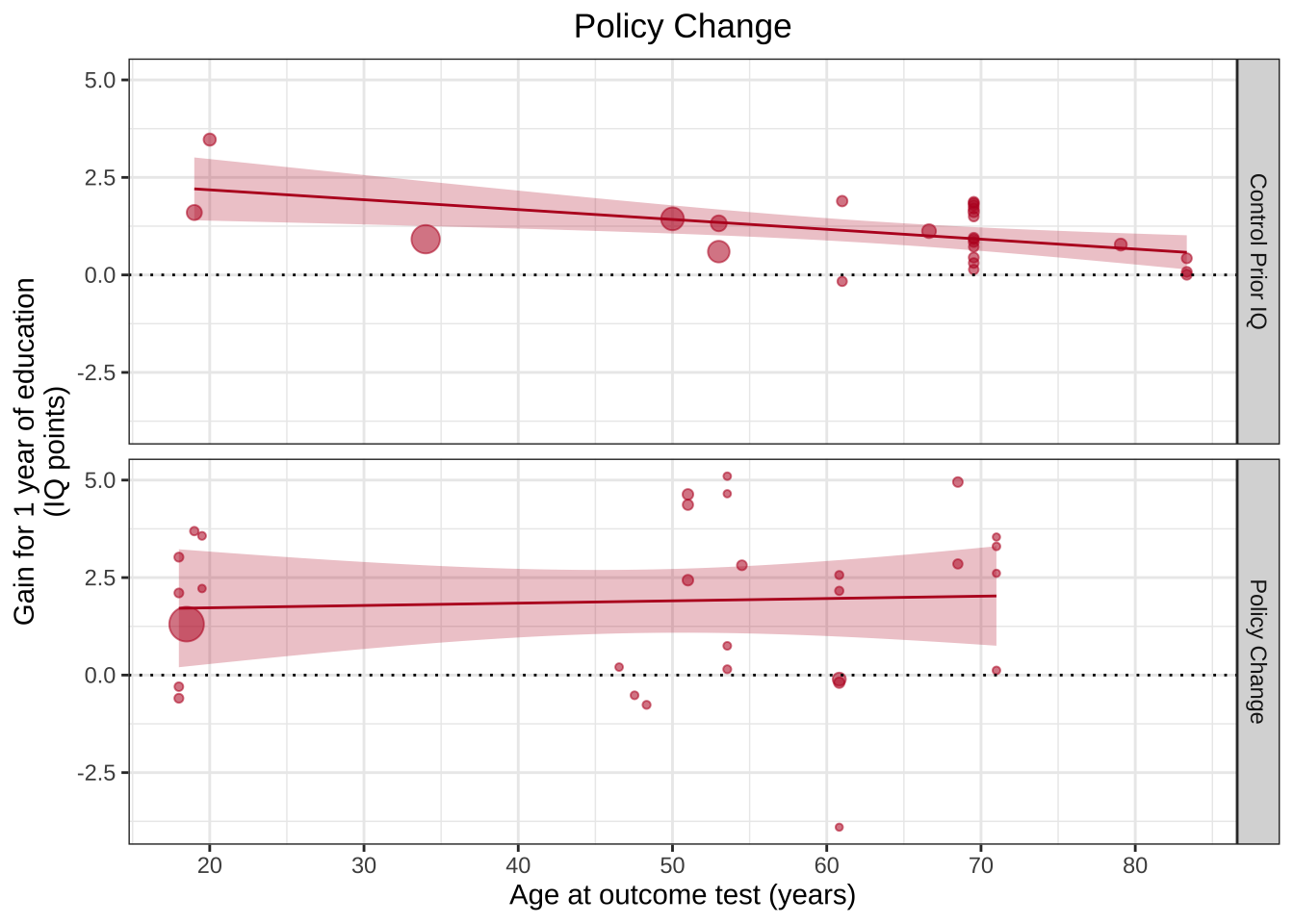
ggplot(aes(x=Outcome_age, y=Effect_size, size=1/(SE^2)), data=df %>%filter(Design !="School Age Cutoff")) +geom_point(alpha=.55, colour="#BA1825") +geom_hline(yintercept=0, linetype="dotted") +theme_bw() +scale_x_continuous(breaks=c(20,30,40,50,60,70,80)) +xlab("Age at outcome test (years)") +ylab("Gain for 1 year of education\n(IQ points)") +guides(size=F) +geom_smooth(method="lm", colour="#BA1825",fill="#BA1825",size=.5, alpha=.25) +ggtitle("Policy Change")+theme(plot.title =element_text(hjust=0.5)) +facet_grid(Design~.)
`geom_smooth()` using formula = 'y ~ x'
Теперь нужно изменить подписи.
ggplot(aes(x=Outcome_age, y=Effect_size, size=1/(SE^2)), data=df %>%filter(Design !="School Age Cutoff")) +geom_point(alpha=.55, colour="#BA1825") +geom_hline(yintercept=0, linetype="dotted") +theme_bw() +scale_x_continuous(breaks=c(20,30,40,50,60,70,80)) +xlab("Age at outcome test (years)") +ylab("Gain for 1 year of education\n(IQ points)") +guides(size=F) +geom_smooth(method="lm", colour="#BA1825",fill="#BA1825",size=.5, alpha=.25) +ggtitle("Effect of education as a function of age at the outcome test")+theme(plot.title =element_text(hjust=0.5)) +facet_grid(Design~.)
`geom_smooth()` using formula = 'y ~ x'
Чтобы акцентировать графики, можно раскрасить их в разные цвета в дополнение к фасеткам. Для этого мы переносим colour = и fill = из параметров соответствующих геомов внутрь эстетик и делаем зависимыми от Design. Поскольку эти эстетики (точнее, colour =) одинаковы заданы для двух геомов (geom_point() и geom_smooth()), то мы спокойно можем вынести их в эстетики по умолчанию — в параметры aes() внутри ggplot().
При этом сразу выключим легенды для новых эстетик, потому что они избыточны.
ggplot(aes(x=Outcome_age, y=Effect_size, size=1/(SE^2), colour = Design, fill = Design), data=df %>%filter(Design !="School Age Cutoff")) +geom_point(alpha=.55) +geom_hline(yintercept=0, linetype="dotted") +theme_bw() +scale_x_continuous(breaks=c(20,30,40,50,60,70,80)) +xlab("Age at outcome test (years)") +ylab("Gain for 1 year of education\n(IQ points)") +guides(size=FALSE, colour =FALSE, fill =FALSE) +geom_smooth(method="lm", size=.5, alpha=.25) +ggtitle("Effect of education as a function of age at the outcome test")+theme(plot.title =element_text(hjust=0.5)) +facet_grid(Design~.)
`geom_smooth()` using formula = 'y ~ x'
Слишком блеклая палитра? Не беда, можно задать палитру вручную! В {ggplot2} встроены легендарные Brewer’s Color Palettes, которыми мы и воспользуемся.
Функции для шкал устроены интересным образом: они состоят из трех слов, первое из которых scale_*_*(), второе — эстетика, например, scale_color_*(), а последнее слово — тип самой шкалы, в некоторых случаях - специальное название для используемой шкалы, как и в случае с scale_color_brewer().
meta_2_gg <-ggplot(aes(x=Outcome_age, y=Effect_size, size=1/(SE^2), colour = Design, fill = Design), data=df %>%filter(Design !="School Age Cutoff")) +geom_point(alpha=.55) +geom_hline(yintercept=0, linetype="dotted") +theme_bw() +scale_x_continuous(breaks=c(20,30,40,50,60,70,80)) +xlab("Age at outcome test (years)") +ylab("Gain for 1 year of education\n(IQ points)") +guides(size=FALSE, colour =FALSE, fill =FALSE) +geom_smooth(method="lm", size=.5, alpha=.25) +ggtitle("Effect of education as a function of age at the outcome test")+theme(plot.title =element_text(hjust=0.5)) +facet_grid(Design~.)+scale_colour_brewer(palette ="Set1")+scale_fill_brewer(palette ="Set1")meta_2_gg
`geom_smooth()` using formula = 'y ~ x'
14.5 Расширения ggplot2
{ggplot2} стал очень популярным пакетом и быстро обзавелся расширениями — пакетами R, надстройками над {ggplot2}. Эти расширения бывают самого разного рода, например, добавляющие дополнительные геомы или просто реализующие отдельные типы графиков на языке {ggplot2}.
Больше сотни пакетов! Это самые различные пакеты, включая как очень специфические, посвященные отдельным научным областям или решающие отдельную задачу при визуализации, так и большие пакеты, которые пытаются расширять саму грамматику графики.
Для примера мы возьмем пакет {hrbrthemes}, который предоставляет дополнительные темы для {ggplot2}, компоненты тем и шкалы.
install.packages("hrbrthemes")
library(hrbrthemes)meta_2_gg +theme_ipsum()
Ritchie, S. J., & Tucker-Drob, E. M. (2018). How Much Does Education Improve Intelligence? A Meta-Analysis. Psychological Science, 29(8), 1358–1369. https://doi.org/10.1177/0956797618774253
Wilkinson, L. (2005). The Grammar of Graphics (2-я изд.). Springer.
Идентична по своему смыслу функции dplyr::count, которая считает частоты по выбранной колонке тиббла (см. Глава 10.9.3).↩︎
Декартова система координат названа в честь великого математика и философа Рене Декарта, на латинском — Renatus Cartesius, отсюда и название cartesian coordinate system.↩︎
Кстати, именно функция subset() вдохновила Уикхема на создание filter().↩︎